 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Autonomous Mathematics Discovery with Gemini: A Case Study on the Erdős Problems
Jan 29, 2026We present a case study in semi-autonomous mathematics discovery, using Gemini to systematically evaluate 700 conjectures labeled 'Open' in Bloom's Erdős Problems database. We employ a hybrid methodology: AI-driven natural language verification to narrow the search space, followed by human expert evaluation to gauge correctness and novelty. We address 13 problems that were marked 'Open' in the database: 5 through seemingly novel autonomous solutions, and 8 through identification of previous solutions in the existing literature. Our findings suggest that the 'Open' status of the problems was through obscurity rather than difficulty. We also identify and discuss issues arising in applying AI to math conjectures at scale, highlighting the difficulty of literature identification and the risk of ''subconscious plagiarism'' by AI. We reflect on the takeaways from AI-assisted efforts on the Erdős Problems.
Rethinking generative image pretraining: How far are we from scaling up next-pixel prediction?
Nov 11, 2025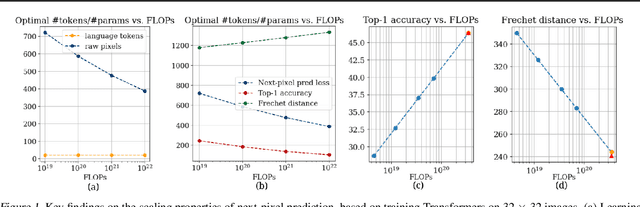
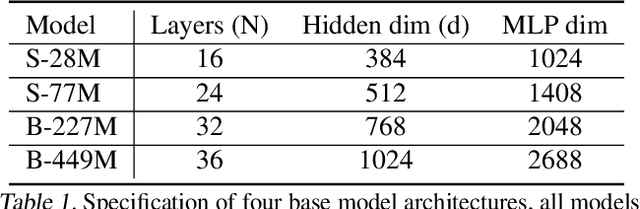

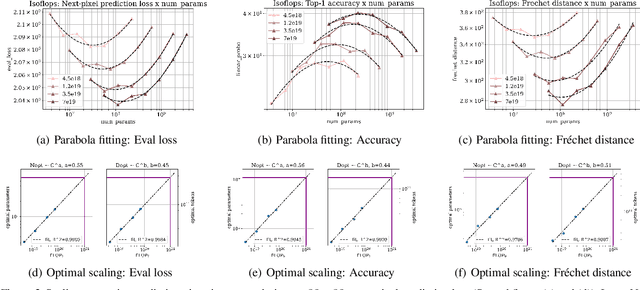
This paper investigates the scaling properties of autoregressive next-pixel prediction, a simple, end-to-end yet under-explored framework for unified vision models. Starting with images at resolutions of 32x32, we train a family of Transformers using IsoFlops profiles across compute budgets up to 7e19 FLOPs and evaluate three distinct target metrics: next-pixel prediction objective, ImageNet classification accuracy, and generation quality measured by Fr'echet Distance. First, optimal scaling strategy is critically task-dependent. At a fixed 32x32 resolution alone, the optimal scaling properties for image classification and image generation diverge, where generation optimal setup requires the data size grow three to five times faster than for the classification optimal setup. Second, as image resolution increases, the optimal scaling strategy indicates that the model size must grow much faster than data size. Surprisingly, by projecting our findings, we discover that the primary bottleneck is compute rather than the amount of training data. As compute continues to grow four to five times annually, we forecast the feasibility of pixel-by-pixel modeling of images within the next five years.
BIG-Bench Extra Hard
Feb 26, 2025Large language models (LLMs) are increasingly deployed in everyday applications, demanding robust general reasoning capabilities and diverse reasoning skillset. However, current LLM reasoning benchmarks predominantly focus on mathematical and coding abilities, leaving a gap in evaluating broader reasoning proficiencies. One particular exception is the BIG-Bench dataset, which has served as a crucial benchmark for evaluating the general reasoning capabilities of LLMs, thanks to its diverse set of challenging tasks that allowed for a comprehensive assessment of general reasoning across various skills within a unified framework. However, recent advances in LLMs have led to saturation on BIG-Bench, and its harder version BIG-Bench Hard (BBH). State-of-the-art models achieve near-perfect scores on many tasks in BBH, thus diminishing its utility. To address this limitation, we introduce BIG-Bench Extra Hard (BBEH), a new benchmark designed to push the boundaries of LLM reasoning evaluation. BBEH replaces each task in BBH with a novel task that probes a similar reasoning capability but exhibits significantly increased difficulty. We evaluate various models on BBEH and observe a (harmonic) average accuracy of 9.8\% for the best general-purpose model and 44.8\% for the best reasoning-specialized model, indicating substantial room for improvement and highlighting the ongoing challenge of achieving robust general reasoning in LLMs. We release BBEH publicly at: https://github.com/google-deepmind/bbeh.
Gold-medalist Performance in Solving Olympiad Geometry with AlphaGeometry2
Feb 05, 2025We present AlphaGeometry2, a significantly improved version of AlphaGeometry introduced in Trinh et al. (2024), which has now surpassed an average gold medalist in solving Olympiad geometry problems. To achieve this, we first extend the original AlphaGeometry language to tackle harder problems involving movements of objects, and problems containing linear equations of angles, ratios, and distances. This, together with other additions, has markedly improved the coverage rate of the AlphaGeometry language on International Math Olympiads (IMO) 2000-2024 geometry problems from 66% to 88%. The search process of AlphaGeometry2 has also been greatly improved through the use of Gemini architecture for better language modeling, and a novel knowledge-sharing mechanism that combines multiple search trees. Together with further enhancements to the symbolic engine and synthetic data generation, we have significantly boosted the overall solving rate of AlphaGeometry2 to 84% for $\textit{all}$ geometry problems over the last 25 years, compared to 54% previously. AlphaGeometry2 was also part of the system that achieved silver-medal standard at IMO 2024 https://dpmd.ai/imo-silver. Last but not least, we report progress towards using AlphaGeometry2 as a part of a fully automated system that reliably solves geometry problems directly from natural language input.
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
Jan 28, 2025



Supervised fine-tuning (SFT) and reinforcement learning (RL) are widely used post-training techniques for foundation models. However, their roles in enhancing model generalization capabilities remain unclear. This paper studies the difference between SFT and RL on generalization and memorization, focusing on text-based rule variants and visual variants. We introduce GeneralPoints, an arithmetic reasoning card game, and adopt V-IRL, a real-world navigation environment, to assess how models trained with SFT and RL generalize to unseen variants in both textual and visual domains. We show that RL, especially when trained with an outcome-based reward, generalizes across both rule-based textual and visual variants. SFT, in contrast, tends to memorize training data and struggles to generalize out-of-distribution scenarios. Further analysis reveals that RL improves the model's underlying visual recognition capabilities, contributing to its enhanced generalization in the visual domain. Despite RL's superior generalization, we show that SFT remains essential for effective RL training; SFT stabilizes the model's output format, enabling subsequent RL to achieve its performance gains. These findings demonstrates the capability of RL for acquiring generalizable knowledge in complex, multi-modal tasks.
Evolving Alignment via Asymmetric Self-Play
Oct 31, 2024



Current RLHF frameworks for aligning large language models (LLMs) typically assume a fixed prompt distribution, which is sub-optimal and limits the scalability of alignment and generalizability of models. To address this, we introduce a general open-ended RLHF framework that casts alignment as an asymmetric game between two players: (i) a creator that generates increasingly informative prompt distributions using the reward model, and (ii) a solver that learns to produce more preferred responses on prompts produced by the creator. This framework of Evolving Alignment via Asymmetric Self-Play (eva), results in a simple and efficient approach that can utilize any existing RLHF algorithm for scalable alignment. eva outperforms state-of-the-art methods on widely-used benchmarks, without the need of any additional human crafted prompts. Specifically, eva improves the win rate of Gemma-2-9B-it on Arena-Hard from 51.6% to 60.1% with DPO, from 55.7% to 58.9% with SPPO, from 52.3% to 60.7% with SimPO, and from 54.8% to 60.3% with ORPO, surpassing its 27B version and matching claude-3-opus. This improvement is persistent even when new human crafted prompts are introduced. Finally, we show eva is effective and robust under various ablation settings.
EVOLvE: Evaluating and Optimizing LLMs For Exploration
Oct 08, 2024



Despite their success in many domains, large language models (LLMs) remain under-studied in scenarios requiring optimal decision-making under uncertainty. This is crucial as many real-world applications, ranging from personalized recommendations to healthcare interventions, demand that LLMs not only predict but also actively learn to make optimal decisions through exploration. In this work, we measure LLMs' (in)ability to make optimal decisions in bandits, a state-less reinforcement learning setting relevant to many applications. We develop a comprehensive suite of environments, including both context-free and contextual bandits with varying task difficulties, to benchmark LLMs' performance. Motivated by the existence of optimal exploration algorithms, we propose efficient ways to integrate this algorithmic knowledge into LLMs: by providing explicit algorithm-guided support during inference; and through algorithm distillation via in-context demonstrations and fine-tuning, using synthetic data generated from these algorithms. Impressively, these techniques allow us to achieve superior exploration performance with smaller models, surpassing larger models on various tasks. We conducted an extensive ablation study to shed light on various factors, such as task difficulty and data representation, that influence the efficiency of LLM exploration. Additionally, we conduct a rigorous analysis of the LLM's exploration efficiency using the concept of regret, linking its ability to explore to the model size and underlying algorithm.
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Jul 31, 2024



Scaling the amount of compute used to train language models has dramatically improved their capabilities. However, when it comes to inference, we often limit the amount of compute to only one attempt per problem. Here, we explore inference compute as another axis for scaling by increasing the number of generated samples. Across multiple tasks and models, we observe that coverage - the fraction of problems solved by any attempt - scales with the number of samples over four orders of magnitude. In domains like coding and formal proofs, where all answers can be automatically verified, these increases in coverage directly translate into improved performance. When we apply repeated sampling to SWE-bench Lite, the fraction of issues solved with DeepSeek-V2-Coder-Instruct increases from 15.9% with one sample to 56% with 250 samples, outperforming the single-attempt state-of-the-art of 43% which uses more capable frontier models. Moreover, using current API pricing, amplifying the cheaper DeepSeek model with five samples is more cost-effective and solves more issues than paying a premium for one sample from GPT-4o or Claude 3.5 Sonnet. Interestingly, the relationship between coverage and the number of samples is often log-linear and can be modelled with an exponentiated power law, suggesting the existence of inference-time scaling laws. Finally, we find that identifying correct samples out of many generations remains an important direction for future research in domains without automatic verifiers. When solving math word problems from GSM8K and MATH, coverage with Llama-3 models grows to over 95% with 10,000 samples. However, common methods to pick correct solutions from a sample collection, such as majority voting or reward models, plateau beyond several hundred samples and fail to fully scale with the sample budget.
NATURAL PLAN: Benchmarking LLMs on Natural Language Planning
Jun 06, 2024



We introduce NATURAL PLAN, a realistic planning benchmark in natural language containing 3 key tasks: Trip Planning, Meeting Planning, and Calendar Scheduling. We focus our evaluation on the planning capabilities of LLMs with full information on the task, by providing outputs from tools such as Google Flights, Google Maps, and Google Calendar as contexts to the models. This eliminates the need for a tool-use environment for evaluating LLMs on Planning. We observe that NATURAL PLAN is a challenging benchmark for state of the art models. For example, in Trip Planning, GPT-4 and Gemini 1.5 Pro could only achieve 31.1% and 34.8% solve rate respectively. We find that model performance drops drastically as the complexity of the problem increases: all models perform below 5% when there are 10 cities, highlighting a significant gap in planning in natural language for SoTA LLMs. We also conduct extensive ablation studies on NATURAL PLAN to further shed light on the (in)effectiveness of approaches such as self-correction, few-shot generalization, and in-context planning with long-contexts on improving LLM planning.
Long-form factuality in large language models
Apr 03, 2024



Large language models (LLMs) often generate content that contains factual errors when responding to fact-seeking prompts on open-ended topics. To benchmark a model's long-form factuality in open domains, we first use GPT-4 to generate LongFact, a prompt set comprising thousands of questions spanning 38 topics. We then propose that LLM agents can be used as automated evaluators for long-form factuality through a method which we call Search-Augmented Factuality Evaluator (SAFE). SAFE utilizes an LLM to break down a long-form response into a set of individual facts and to evaluate the accuracy of each fact using a multi-step reasoning process comprising sending search queries to Google Search and determining whether a fact is supported by the search results. Furthermore, we propose extending F1 score as an aggregated metric for long-form factuality. To do so, we balance the percentage of supported facts in a response (precision) with the percentage of provided facts relative to a hyperparameter representing a user's preferred response length (recall). Empirically, we demonstrate that LLM agents can outperform crowdsourced human annotators - on a set of ~16k individual facts, SAFE agrees with crowdsourced human annotators 72% of the time, and on a random subset of 100 disagreement cases, SAFE wins 76% of the time. At the same time, SAFE is more than 20 times cheaper than human annotators. We also benchmark thirteen language models on LongFact across four model families (Gemini, GPT, Claude, and PaLM-2), finding that larger language models generally achieve better long-form factuality. LongFact, SAFE, and all experimental code are available at https://github.com/google-deepmind/long-form-factuality.