 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVOLvE: Evaluating and Optimizing LLMs For Exploration
Oct 08, 2024



Despite their success in many domains, large language models (LLMs) remain under-studied in scenarios requiring optimal decision-making under uncertainty. This is crucial as many real-world applications, ranging from personalized recommendations to healthcare interventions, demand that LLMs not only predict but also actively learn to make optimal decisions through exploration. In this work, we measure LLMs' (in)ability to make optimal decisions in bandits, a state-less reinforcement learning setting relevant to many applications. We develop a comprehensive suite of environments, including both context-free and contextual bandits with varying task difficulties, to benchmark LLMs' performance. Motivated by the existence of optimal exploration algorithms, we propose efficient ways to integrate this algorithmic knowledge into LLMs: by providing explicit algorithm-guided support during inference; and through algorithm distillation via in-context demonstrations and fine-tuning, using synthetic data generated from these algorithms. Impressively, these techniques allow us to achieve superior exploration performance with smaller models, surpassing larger models on various tasks. We conducted an extensive ablation study to shed light on various factors, such as task difficulty and data representation, that influence the efficiency of LLM exploration. Additionally, we conduct a rigorous analysis of the LLM's exploration efficiency using the concept of regret, linking its ability to explore to the model size and underlying algorithm.
Latent User Intent Modeling for Sequential Recommenders
Nov 17, 2022Sequential recommender models are essential components of modern industrial recommender systems. These models learn to predict the next items a user is likely to interact with based on his/her interaction history on the platform. Most sequential recommenders however lack a higher-level understanding of user intents, which often drive user behaviors online. Intent modeling is thus critical for understanding users and optimizing long-term user experience. We propose a probabilistic modeling approach and formulate user intent as latent variables, which are inferred based on user behavior signals using variational autoencoders (VAE). The recommendation policy is then adjusted accordingly given the inferred user intent. We demonstrate the effectiveness of the latent user intent modeling via offline analyses as well as live experiments on a large-scale industrial recommendation platform.
Learning to Augment for Casual User Recommendation
Apr 02, 2022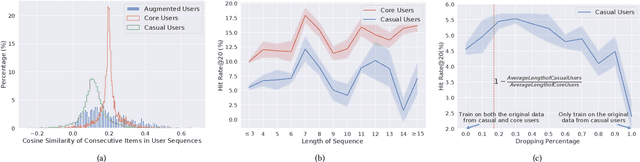
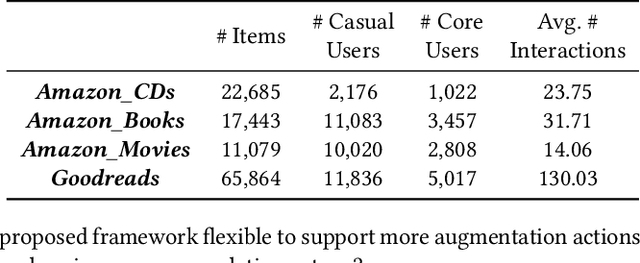
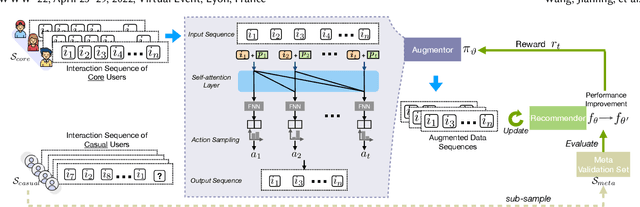
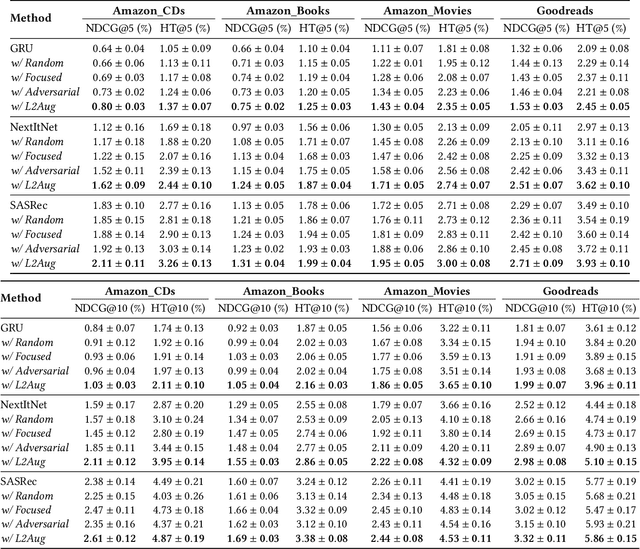
Users who come to recommendation platforms are heterogeneous in activity levels. There usually exists a group of core users who visit the platform regularly and consume a large body of content upon each visit, while others are casual users who tend to visit the platform occasionally and consume less each time. As a result, consumption activities from core users often dominate the training data used for learning. As core users can exhibit different activity patterns from casual users, recommender systems trained on historical user activity data usually achieve much worse performance on casual users than core users. To bridge the gap, we propose a model-agnostic framework L2Aug to improve recommendations for casual users through data augmentation, without sacrificing core user experience. L2Aug is powered by a data augmentor that learns to generate augmented interaction sequences, in order to fine-tune and optimize the performance of the recommendation system for casual users. On four real-world public datasets, L2Aug outperforms other treatment methods and achieves the best sequential recommendation performance for both casual and core users. We also test L2Aug in an online simulation environment with real-time feedback to further validate its efficacy, and showcase its flexibility in supporting different augmentation actions.
Recency Dropout for Recurrent Recommender Systems
Jan 26, 2022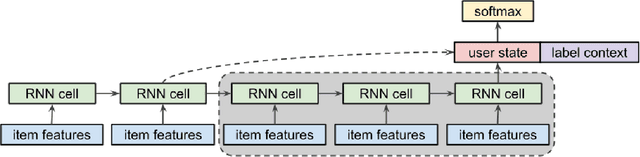
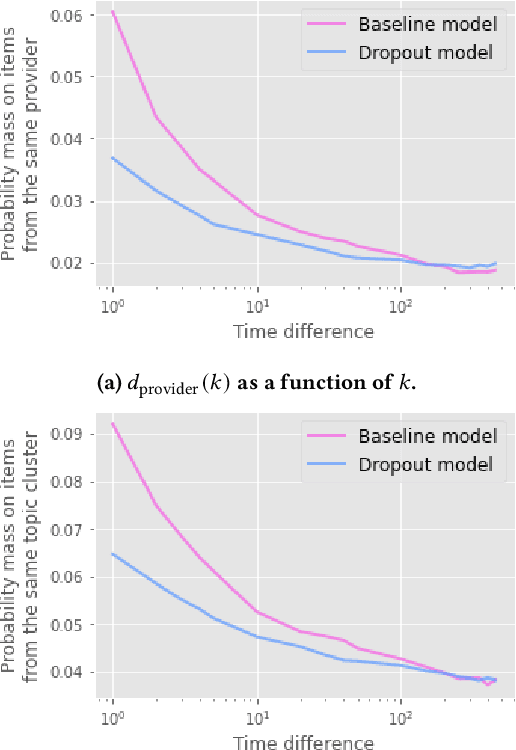
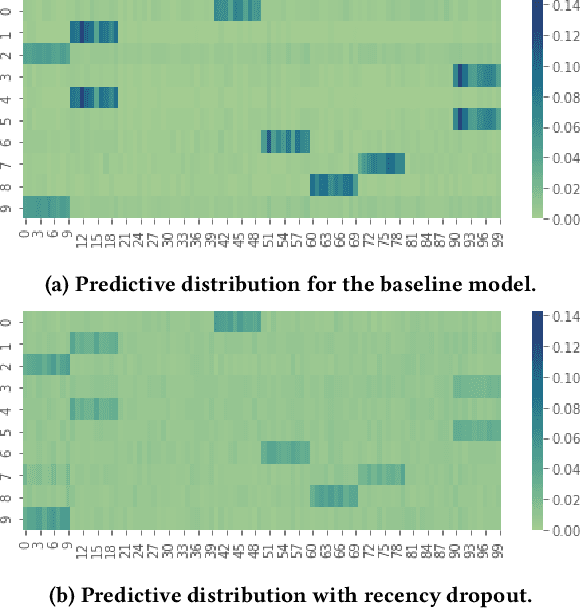
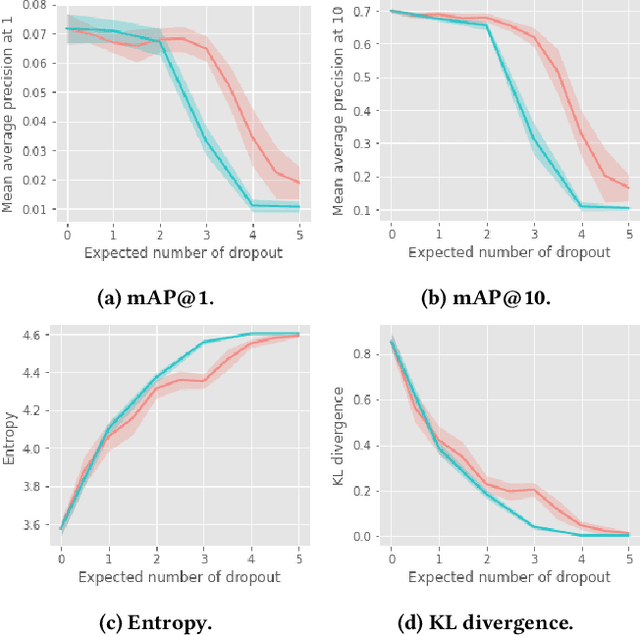
Recurrent recommender systems have been successful in capturing the temporal dynamics in users' activity trajectories. However, recurrent neural networks (RNNs) are known to have difficulty learning long-term dependencies. As a consequence, RNN-based recommender systems tend to overly focus on short-term user interests. This is referred to as the recency bias, which could negatively affect the long-term user experience as well as the health of the ecosystem. In this paper, we introduce the recency dropout technique, a simple yet effective data augmentation technique to alleviate the recency bias in recurrent recommender systems. We demonstrate the effectiveness of recency dropout in various experimental settings including a simulation study, offline experiments, as well as live experiments on a large-scale industrial recommendation platform.
CopulaGNN: Towards Integrating Representational and Correlational Roles of Graphs in Graph Neural Networks
Oct 05, 2020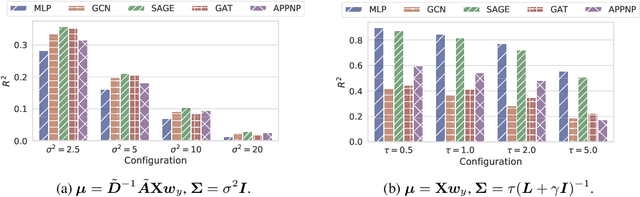
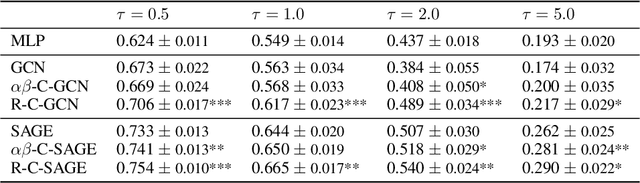
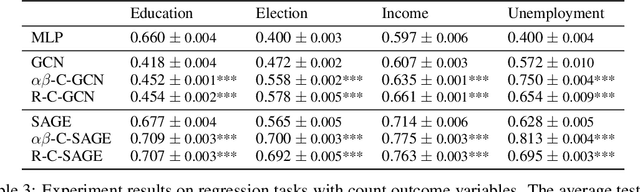
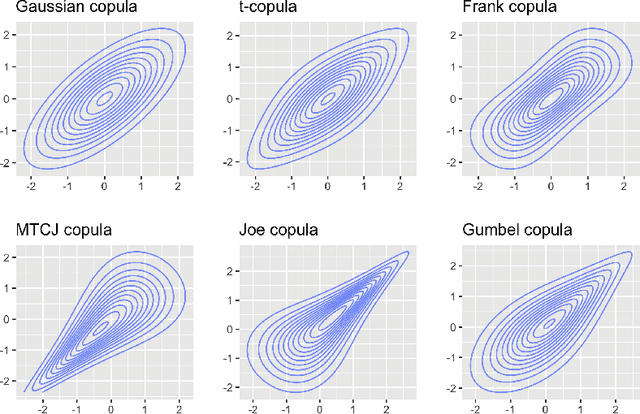
Graph-structured data are ubiquitous. However, graphs encode diverse types of information and thus play different roles in data representation. In this paper, we distinguish the \textit{representational} and the \textit{correlational} roles played by the graphs in node-level prediction tasks, and we investigate how Graph Neural Network (GNN) models can effectively leverage both types of information. Conceptually, the representational information provides guidance for the model to construct better node features; while the correlational information indicates the correlation between node outcomes conditional on node features. Through a simulation study, we find that many popular GNN models are incapable of effectively utilizing the correlational information. By leveraging the idea of the copula, a principled way to describe the dependence among multivariate random variables, we offer a general solution. The proposed Copula Graph Neural Network (CopulaGNN) can take a wide range of GNN models as base models and utilize both representational and correlational information stored in the graphs. Experimental results on two types of regression tasks verify the effectiveness of the proposed method.
Modeling Continuous Stochastic Processes with Dynamic Normalizing Flows
Feb 24, 2020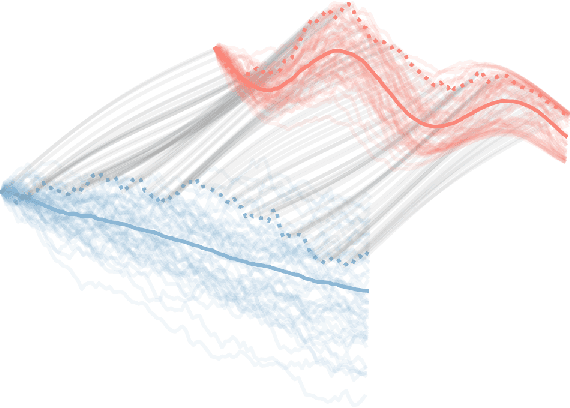
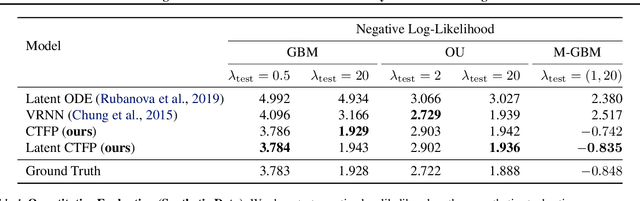
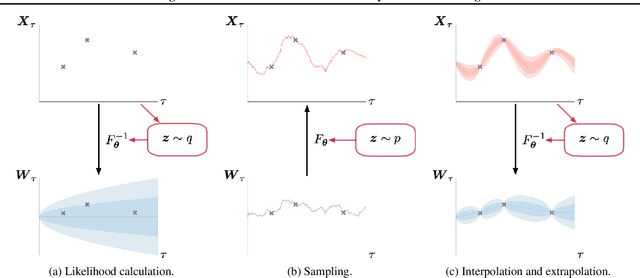

Normalizing flows transform a simple base distribution into a complex target distribution and have proved to be powerful models for data generation and density estimation. In this work, we propose a novel type of normalizing flow driven by a differential deformation of the continuous-time Wiener process. As a result, we obtain a rich time series model whose observable process inherits many of the appealing properties of its base process, such as efficient computation of likelihoods and marginals. Furthermore, our continuous treatment provides a natural framework for irregular time series with an independent arrival process, including straightforward interpolation. We illustrate the desirable properties of the proposed model on popular stochastic processes and demonstrate its superior flexibility to variational RNN and latent ODE baselines in a series of experiments on synthetic and real-world data.
Variational Hyper RNN for Sequence Modeling
Feb 24, 2020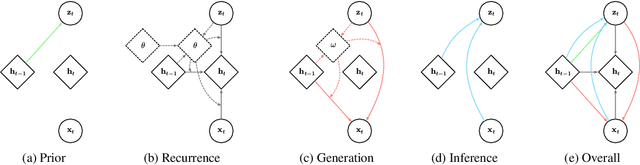

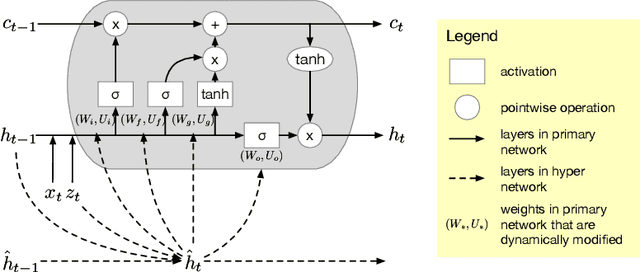
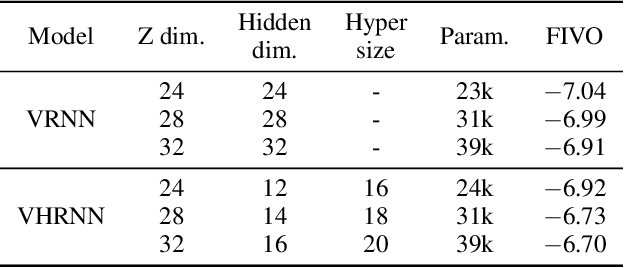
In this work, we propose a novel probabilistic sequence model that excels at capturing high variability in time series data, both across sequences and within an individual sequence. Our method uses temporal latent variables to capture information about the underlying data pattern and dynamically decodes the latent information into modifications of weights of the base decoder and recurrent model. The efficacy of the proposed method is demonstrated on a range of synthetic and real-world sequential data that exhibit large scale variations, regime shifts, and complex dynamics.
Point Process Flows
Oct 31, 2019
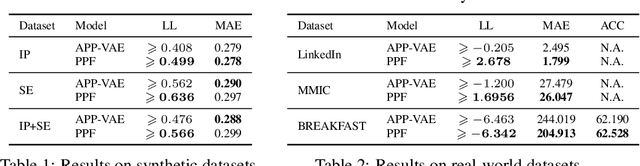
Event sequences can be modeled by temporal point processes (TPPs) to capture their asynchronous and probabilistic nature. We propose an intensity-free framework that directly models the point process distribution by utilizing normalizing flows. This approach is capable of capturing highly complex temporal distributions and does not rely on restrictive parametric forms. Comparisons with state-of-the-art baseline models on both synthetic and challenging real-life datasets show that the proposed framework is effective at modeling the stochasticity of discrete event sequences.
AntisymmetricRNN: A Dynamical System View on Recurrent Neural Networks
Feb 26, 2019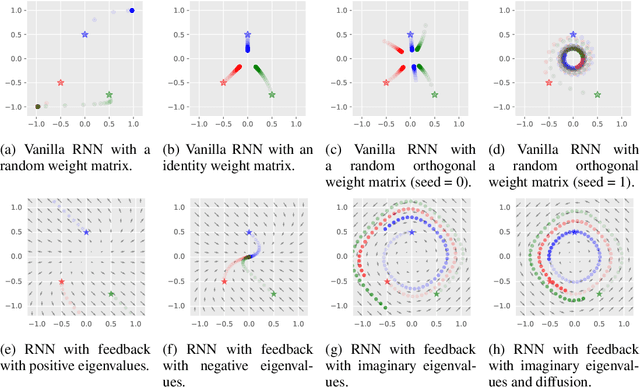
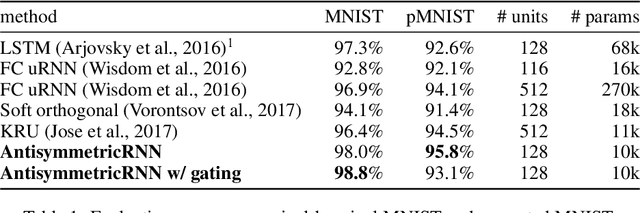
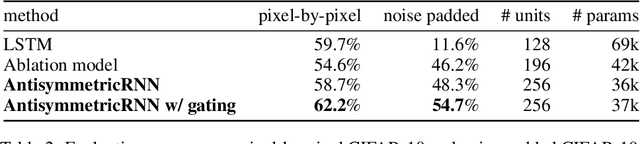
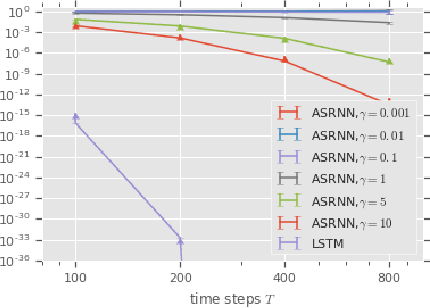
Recurrent neural networks have gained widespread use in modeling sequential data. Learning long-term dependencies using these models remains difficult though, due to exploding or vanishing gradients. In this paper, we draw connections between recurrent networks and ordinary differential equations. A special form of recurrent networks called the AntisymmetricRNN is proposed under this theoretical framework, which is able to capture long-term dependencies thanks to the stability property of its underlying differential equation. Existing approaches to improving RNN trainability often incur significant computation overhead. In comparison, AntisymmetricRNN achieves the same goal by design. We showcase the advantage of this new architecture through extensive simulations and experiments. AntisymmetricRNN exhibits much more predictable dynamics. It outperforms regular LSTM models on tasks requiring long-term memory and matches the performance on tasks where short-term dependencies dominate despite being much simpler.
Dynamical Isometry and a Mean Field Theory of LSTMs and GRUs
Jan 25, 2019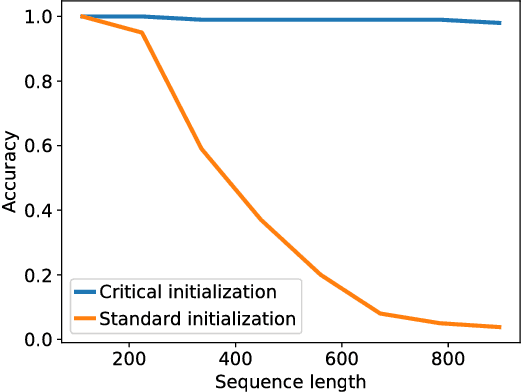

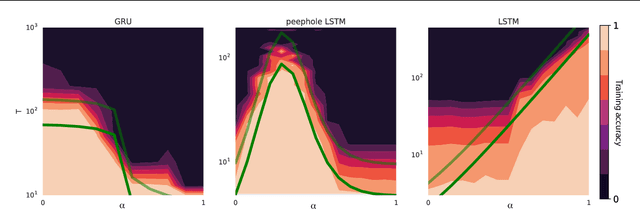

Training recurrent neural networks (RNNs) on long sequence tasks is plagued with difficulties arising from the exponential explosion or vanishing of signals as they propagate forward or backward through the network. Many techniques have been proposed to ameliorate these issues, including various algorithmic and architectural modifications. Two of the most successful RNN architectures, the LSTM and the GRU, do exhibit modest improvements over vanilla RNN cells, but they still suffer from instabilities when trained on very long sequences. In this work, we develop a mean field theory of signal propagation in LSTMs and GRUs that enables us to calculate the time scales for signal propagation as well as the spectral properties of the state-to-state Jacobians. By optimizing these quantities in terms of the initialization hyperparameters, we derive a novel initialization scheme that eliminates or reduces training instabilities. We demonstrate the efficacy of our initialization scheme on multiple sequence tasks, on which it enables successful training while a standard initialization either fails completely or is orders of magnitude slower. We also observe a beneficial effect on generalization performance using this new initialization.