 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Shaping for User Satisfaction in a REINFORCE Recommender
Sep 30, 2022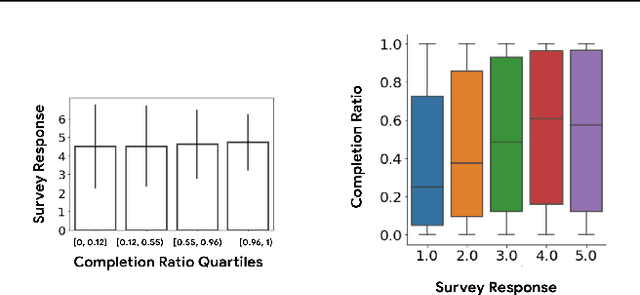
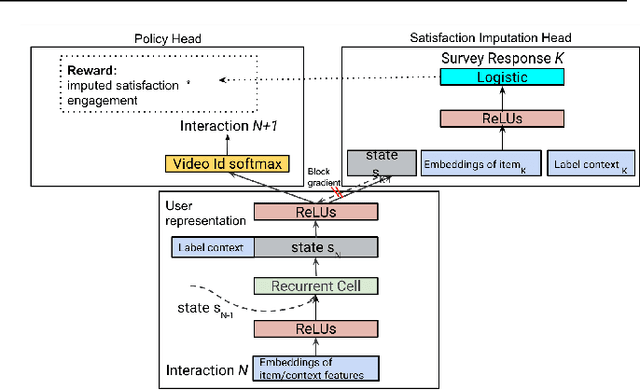
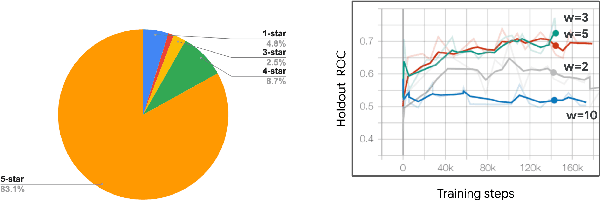
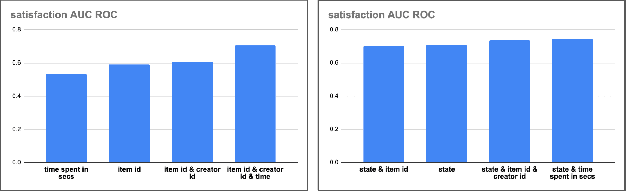
How might we design Reinforcement Learning (RL)-based recommenders that encourage aligning user trajectories with the underlying user satisfaction? Three research questions are key: (1) measuring user satisfaction, (2) combatting sparsity of satisfaction signals, and (3) adapting the training of the recommender agent to maximize satisfaction. For measurement, it has been found that surveys explicitly asking users to rate their experience with consumed items can provide valuable orthogonal information to the engagement/interaction data, acting as a proxy to the underlying user satisfaction. For sparsity, i.e, only being able to observe how satisfied users are with a tiny fraction of user-item interactions, imputation models can be useful in predicting satisfaction level for all items users have consumed. For learning satisfying recommender policies, we postulate that reward shaping in RL recommender agents is powerful for driving satisfying user experiences. Putting everything together, we propose to jointly learn a policy network and a satisfaction imputation network: The role of the imputation network is to learn which actions are satisfying to the user; while the policy network, built on top of REINFORCE, decides which items to recommend, with the reward utilizing the imputed satisfaction. We use both offline analysis and live experiments in an industrial large-scale recommendation platform to demonstrate the promise of our approach for satisfying user experiences.
Learning to Augment for Casual User Recommendation
Apr 02, 2022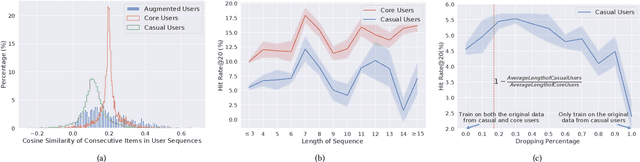
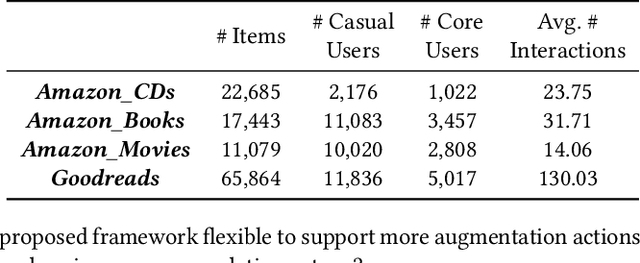
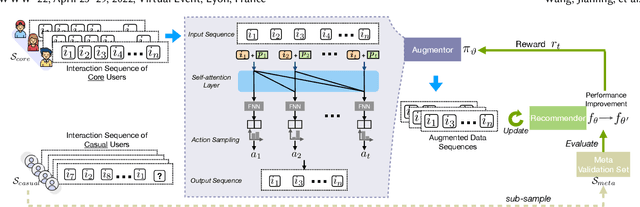
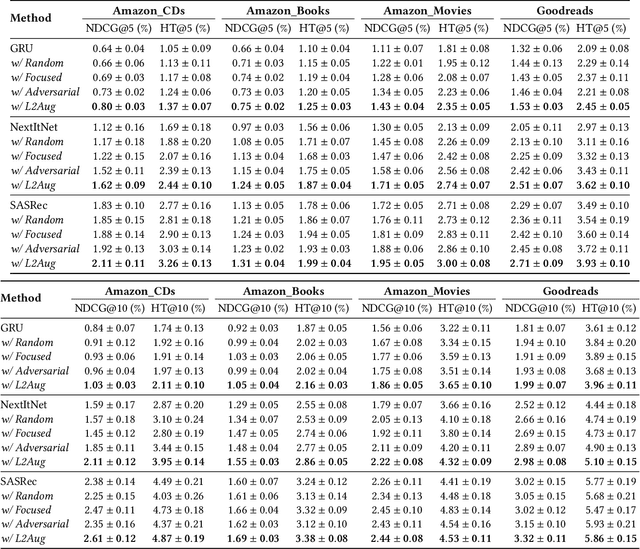
Users who come to recommendation platforms are heterogeneous in activity levels. There usually exists a group of core users who visit the platform regularly and consume a large body of content upon each visit, while others are casual users who tend to visit the platform occasionally and consume less each time. As a result, consumption activities from core users often dominate the training data used for learning. As core users can exhibit different activity patterns from casual users, recommender systems trained on historical user activity data usually achieve much worse performance on casual users than core users. To bridge the gap, we propose a model-agnostic framework L2Aug to improve recommendations for casual users through data augmentation, without sacrificing core user experience. L2Aug is powered by a data augmentor that learns to generate augmented interaction sequences, in order to fine-tune and optimize the performance of the recommendation system for casual users. On four real-world public datasets, L2Aug outperforms other treatment methods and achieves the best sequential recommendation performance for both casual and core users. We also test L2Aug in an online simulation environment with real-time feedback to further validate its efficacy, and showcase its flexibility in supporting different augmentation actions.
Recency Dropout for Recurrent Recommender Systems
Jan 26, 2022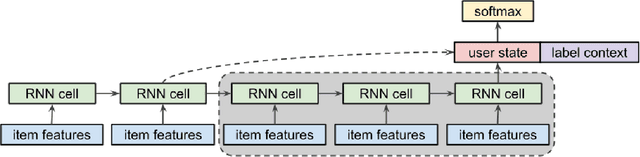
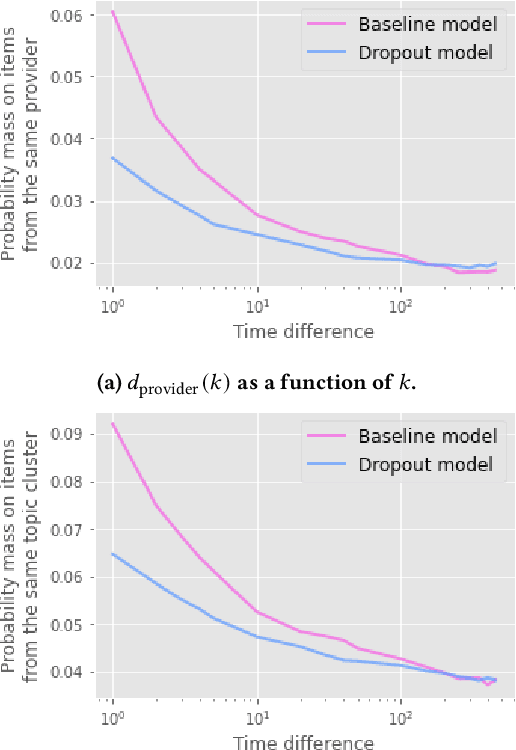
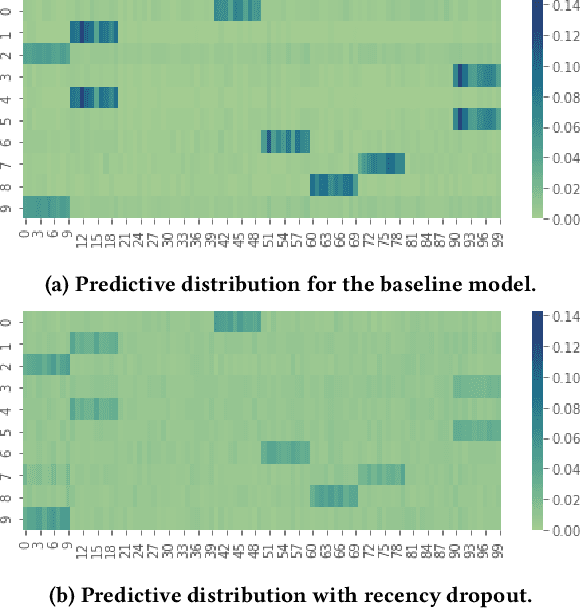
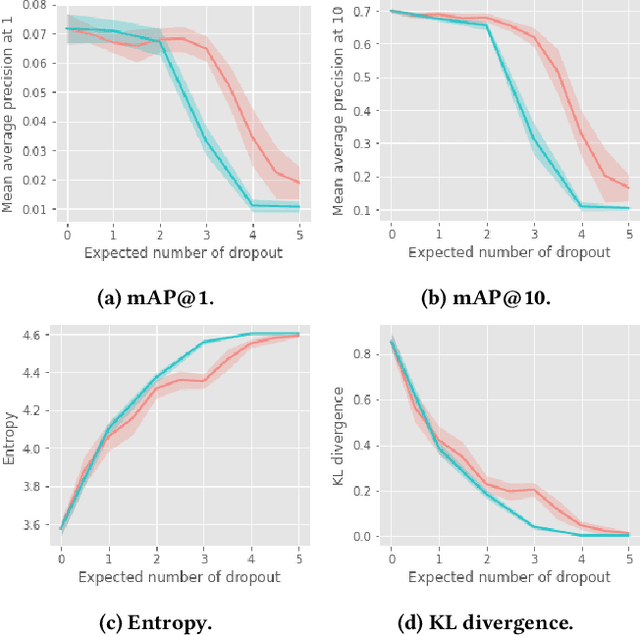
Recurrent recommender systems have been successful in capturing the temporal dynamics in users' activity trajectories. However, recurrent neural networks (RNNs) are known to have difficulty learning long-term dependencies. As a consequence, RNN-based recommender systems tend to overly focus on short-term user interests. This is referred to as the recency bias, which could negatively affect the long-term user experience as well as the health of the ecosystem. In this paper, we introduce the recency dropout technique, a simple yet effective data augmentation technique to alleviate the recency bias in recurrent recommender systems. We demonstrate the effectiveness of recency dropout in various experimental settings including a simulation study, offline experiments, as well as live experiments on a large-scale industrial recommendation platform.
Towards Content Provider Aware Recommender Systems: A Simulation Study on the Interplay between User and Provider Utilities
May 06, 2021
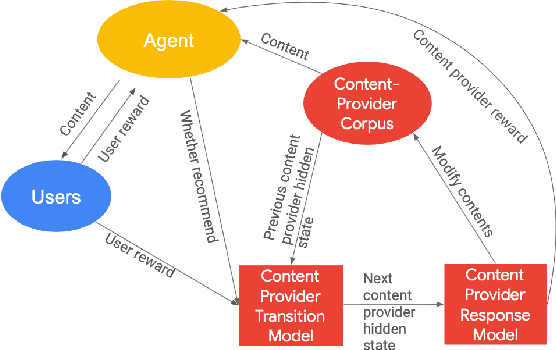
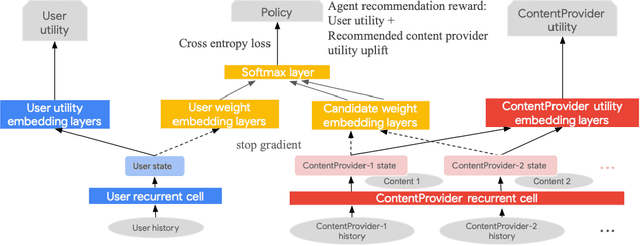
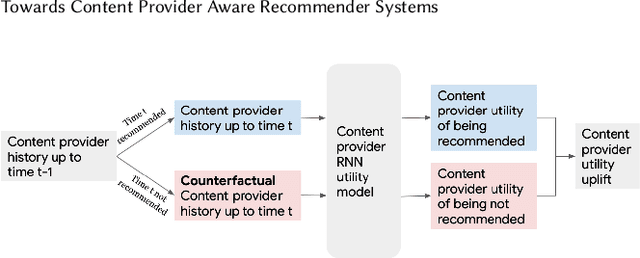
Most existing recommender systems focus primarily on matching users to content which maximizes user satisfaction on the platform. It is increasingly obvious, however, that content providers have a critical influence on user satisfaction through content creation, largely determining the content pool available for recommendation. A natural question thus arises: can we design recommenders taking into account the long-term utility of both users and content providers? By doing so, we hope to sustain more providers and a more diverse content pool for long-term user satisfaction. Understanding the full impact of recommendations on both user and provider groups is challenging. This paper aims to serve as a research investigation of one approach toward building a provider-aware recommender, and evaluating its impact in a simulated setup. To characterize the user-recommender-provider interdependence, we complement user modeling by formalizing provider dynamics as well. The resulting joint dynamical system gives rise to a weakly-coupled partially observable Markov decision process driven by recommender actions and user feedback to providers. We then build a REINFORCE recommender agent, coined EcoAgent, to optimize a joint objective of user utility and the counterfactual utility lift of the provider associated with the recommended content, which we show to be equivalent to maximizing overall user utility and the utilities of all providers on the platform under some mild assumptions. To evaluate our approach, we introduce a simulation environment capturing the key interactions among users, providers, and the recommender. We offer a number of simulated experiments that shed light on both the benefits and the limitations of our approach. These results help understand how and when a provider-aware recommender agent is of benefit in building multi-stakeholder recommender systems.
Sparse Quadratic Discriminant Analysis and Community Bayes
Oct 19, 2016
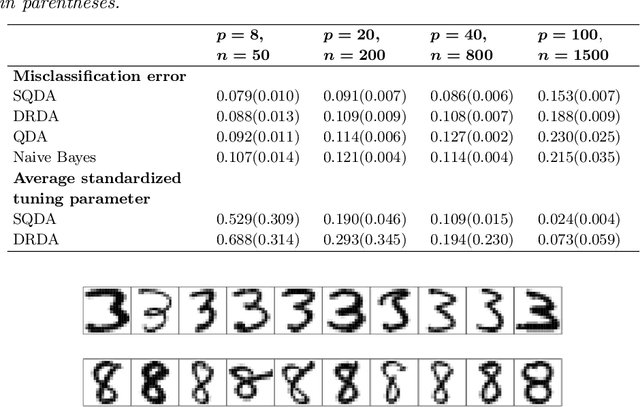
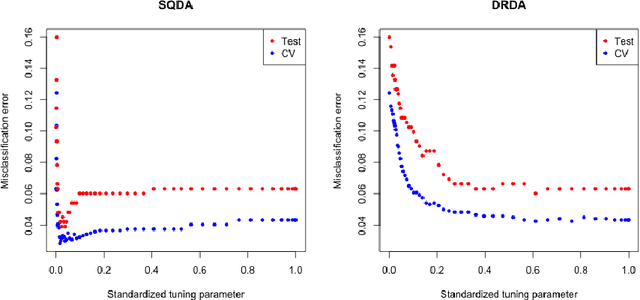

We develop a class of rules spanning the range between quadratic discriminant analysis and naive Bayes, through a path of sparse graphical models. A group lasso penalty is used to introduce shrinkage and encourage a similar pattern of sparsity across precision matrices. It gives sparse estimates of interactions and produces interpretable models. Inspired by the connected-components structure of the estimated precision matrices, we propose the community Bayes model, which partitions features into several conditional independent communities and splits the classification problem into separate smaller ones. The community Bayes idea is quite general and can be applied to non-Gaussian data and likelihood-based classifiers.
Validation of Matching
Apr 11, 2016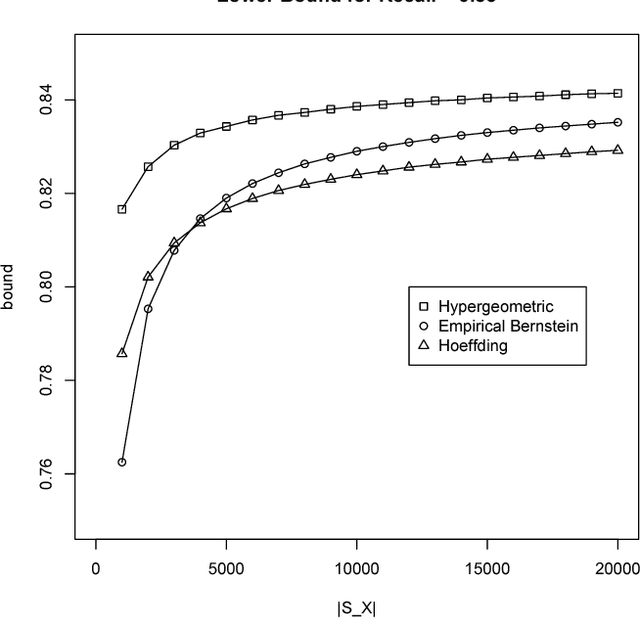
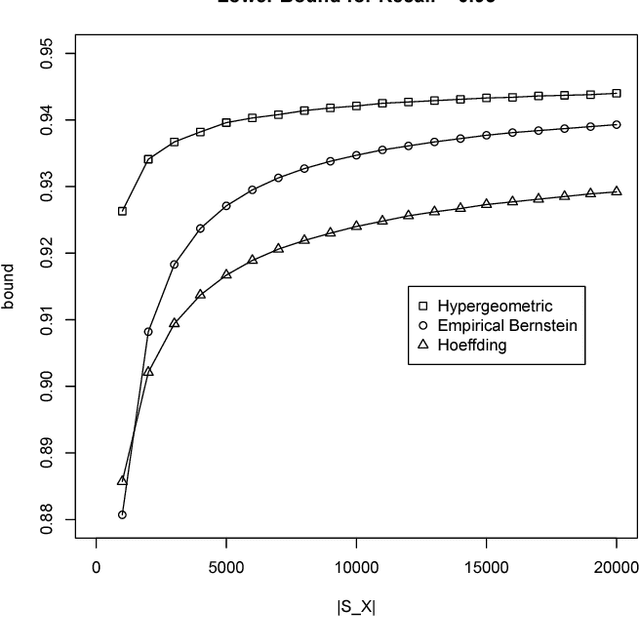
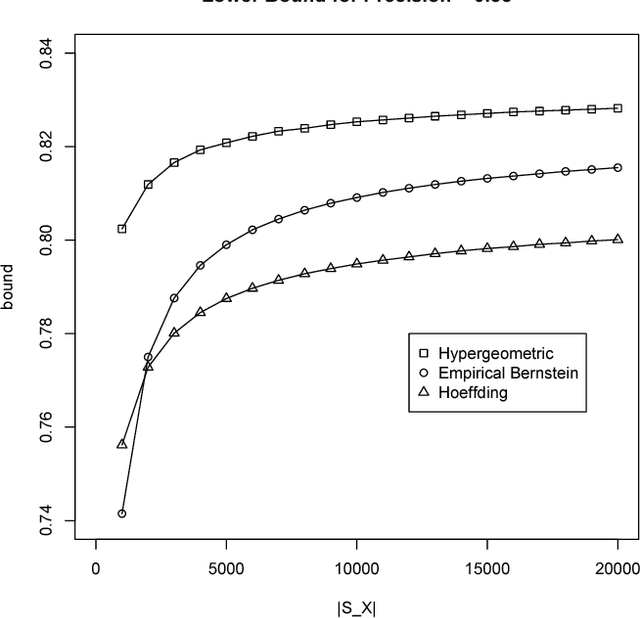
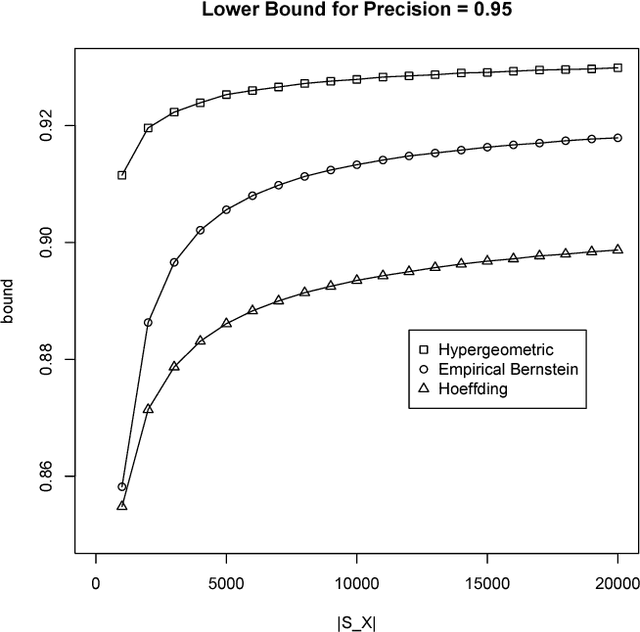
We introduce a technique to compute probably approximately correct (PAC) bounds on precision and recall for matching algorithms. The bounds require some verified matches, but those matches may be used to develop the algorithms. The bounds can be applied to network reconciliation or entity resolution algorithms, which identify nodes in different networks or values in a data set that correspond to the same entity. For network reconciliation, the bounds do not require knowledge of the network generation process.
Some Theory For Practical Classifier Validation
Oct 09, 2015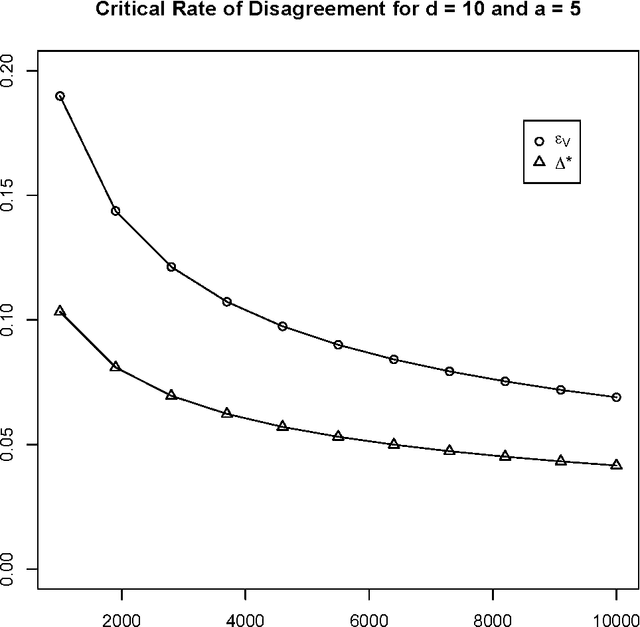
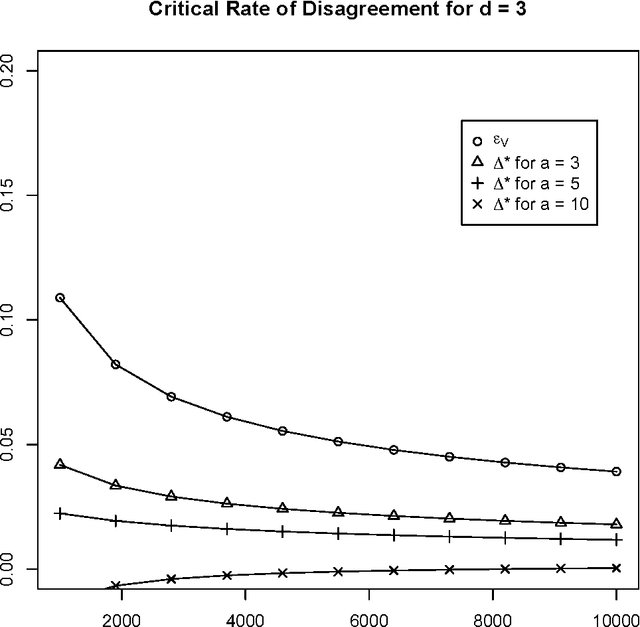
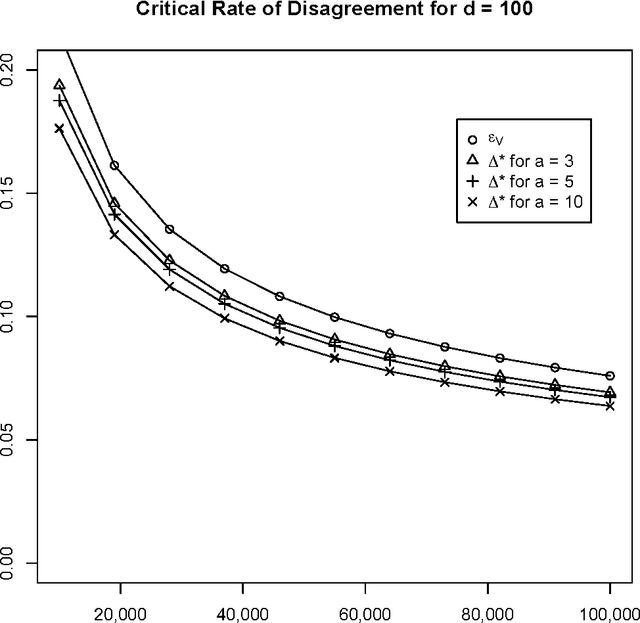
We compare and contrast two approaches to validating a trained classifier while using all in-sample data for training. One is simultaneous validation over an organized set of hypotheses (SVOOSH), the well-known method that began with VC theory. The other is withhold and gap (WAG). WAG withholds a validation set, trains a holdout classifier on the remaining data, uses the validation data to validate that classifier, then adds the rate of disagreement between the holdout classifier and one trained using all in-sample data, which is an upper bound on the difference in error rates. We show that complex hypothesis classes and limited training data can make WAG a favorable alternative.