 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFragility-aware Classification for Understanding Risk and Improving Generalization
Feb 18, 2025Classification models play a critical role in data-driven decision-making applications such as medical diagnosis, user profiling, recommendation systems, and default detection. Traditional performance metrics, such as accuracy, focus on overall error rates but fail to account for the confidence of incorrect predictions, thereby overlooking the risk of confident misjudgments. This risk is particularly significant in cost-sensitive and safety-critical domains like medical diagnosis and autonomous driving, where overconfident false predictions may cause severe consequences. To address this issue, we introduce the Fragility Index (FI), a novel metric that evaluates classification performance from a risk-averse perspective by explicitly capturing the tail risk of confident misjudgments. To enhance generalizability, we define FI within the robust satisficing (RS) framework, incorporating data uncertainty. We further develop a model training approach that optimizes FI while maintaining tractability for common loss functions. Specifically, we derive exact reformulations for cross-entropy loss, hinge-type loss, and Lipschitz loss, and extend the approach to deep learning models. Through synthetic experiments and real-world medical diagnosis tasks, we demonstrate that FI effectively identifies misjudgment risk and FI-based training improves model robustness and generalizability. Finally, we extend our framework to deep neural network training, further validating its effectiveness in enhancing deep learning models.
Distributionally Robust Policy Learning under Concept Drifts
Dec 18, 2024Distributionally robust policy learning aims to find a policy that performs well under the worst-case distributional shift, and yet most existing methods for robust policy learning consider the worst-case joint distribution of the covariate and the outcome. The joint-modeling strategy can be unnecessarily conservative when we have more information on the source of distributional shifts. This paper studiesa more nuanced problem -- robust policy learning under the concept drift, when only the conditional relationship between the outcome and the covariate changes. To this end, we first provide a doubly-robust estimator for evaluating the worst-case average reward of a given policy under a set of perturbed conditional distributions. We show that the policy value estimator enjoys asymptotic normality even if the nuisance parameters are estimated with a slower-than-root-$n$ rate. We then propose a learning algorithm that outputs the policy maximizing the estimated policy value within a given policy class $\Pi$, and show that the sub-optimality gap of the proposed algorithm is of the order $\kappa(\Pi)n^{-1/2}$, with $\kappa(\Pi)$ is the entropy integral of $\Pi$ under the Hamming distance and $n$ is the sample size. A matching lower bound is provided to show the optimality of the rate. The proposed methods are implemented and evaluated in numerical studies, demonstrating substantial improvement compared with existing benchmarks.
Adaptively Learning to Select-Rank in Online Platforms
Jun 07, 2024



Ranking algorithms are fundamental to various online platforms across e-commerce sites to content streaming services. Our research addresses the challenge of adaptively ranking items from a candidate pool for heterogeneous users, a key component in personalizing user experience. We develop a user response model that considers diverse user preferences and the varying effects of item positions, aiming to optimize overall user satisfaction with the ranked list. We frame this problem within a contextual bandits framework, with each ranked list as an action. Our approach incorporates an upper confidence bound to adjust predicted user satisfaction scores and selects the ranking action that maximizes these adjusted scores, efficiently solved via maximum weight imperfect matching. We demonstrate that our algorithm achieves a cumulative regret bound of $O(d\sqrt{NKT})$ for ranking $K$ out of $N$ items in a $d$-dimensional context space over $T$ rounds, under the assumption that user responses follow a generalized linear model. This regret alleviates dependence on the ambient action space, whose cardinality grows exponentially with $N$ and $K$ (thus rendering direct application of existing adaptive learning algorithms -- such as UCB or Thompson sampling -- infeasible). Experiments conducted on both simulated and real-world datasets demonstrate our algorithm outperforms the baseline.
Statistical Properties of Robust Satisficing
May 30, 2024The Robust Satisficing (RS) model is an emerging approach to robust optimization, offering streamlined procedures and robust generalization across various applications. However, the statistical theory of RS remains unexplored in the literature. This paper fills in the gap by comprehensively analyzing the theoretical properties of the RS model. Notably, the RS structure offers a more straightforward path to deriving statistical guarantees compared to the seminal Distributionally Robust Optimization (DRO), resulting in a richer set of results. In particular, we establish two-sided confidence intervals for the optimal loss without the need to solve a minimax optimization problem explicitly. We further provide finite-sample generalization error bounds for the RS optimizer. Importantly, our results extend to scenarios involving distribution shifts, where discrepancies exist between the sampling and target distributions. Our numerical experiments show that the RS model consistently outperforms the baseline empirical risk minimization in small-sample regimes and under distribution shifts. Furthermore, compared to the DRO model, the RS model exhibits lower sensitivity to hyperparameter tuning, highlighting its practicability for robustness considerations.
Proportional Response: Contextual Bandits for Simple and Cumulative Regret Minimization
Jul 05, 2023
Simple regret minimization is a critical problem in learning optimal treatment assignment policies across various domains, including healthcare and e-commerce. However, it remains understudied in the contextual bandit setting. We propose a new family of computationally efficient bandit algorithms for the stochastic contextual bandit settings, with the flexibility to be adapted for cumulative regret minimization (with near-optimal minimax guarantees) and simple regret minimization (with SOTA guarantees). Furthermore, our algorithms adapt to model misspecification and extend to the continuous arm settings. These advantages come from constructing and relying on "conformal arm sets" (CASs), which provide a set of arms at every context that encompass the context-specific optimal arm with some probability across the context distribution. Our positive results on simple and cumulative regret guarantees are contrasted by a negative result, which shows that an algorithm can't achieve instance-dependent simple regret guarantees while simultaneously achieving minimax optimal cumulative regret guarantees.
Post-Episodic Reinforcement Learning Inference
Feb 17, 2023We consider estimation and inference with data collected from episodic reinforcement learning (RL) algorithms; i.e. adaptive experimentation algorithms that at each period (aka episode) interact multiple times in a sequential manner with a single treated unit. Our goal is to be able to evaluate counterfactual adaptive policies after data collection and to estimate structural parameters such as dynamic treatment effects, which can be used for credit assignment (e.g. what was the effect of the first period action on the final outcome). Such parameters of interest can be framed as solutions to moment equations, but not minimizers of a population loss function, leading to Z-estimation approaches in the case of static data. However, such estimators fail to be asymptotically normal in the case of adaptive data collection. We propose a re-weighted Z-estimation approach with carefully designed adaptive weights to stabilize the episode-varying estimation variance, which results from the nonstationary policy that typical episodic RL algorithms invoke. We identify proper weighting schemes to restore the consistency and asymptotic normality of the re-weighted Z-estimators for target parameters, which allows for hypothesis testing and constructing reliable confidence regions for target parameters of interest. Primary applications include dynamic treatment effect estimation and dynamic off-policy evaluation.
Two-Stage Constrained Actor-Critic for Short Video Recommendation
Feb 06, 2023
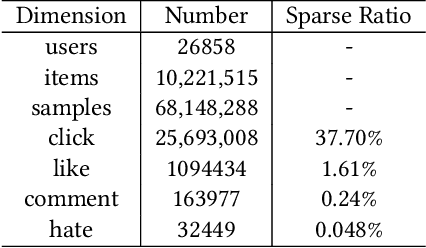
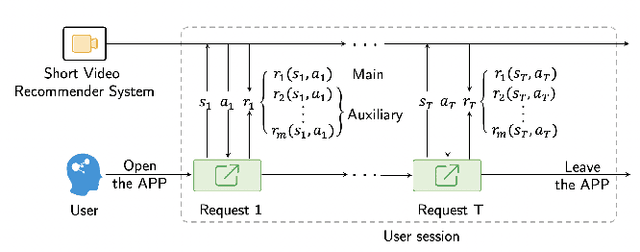
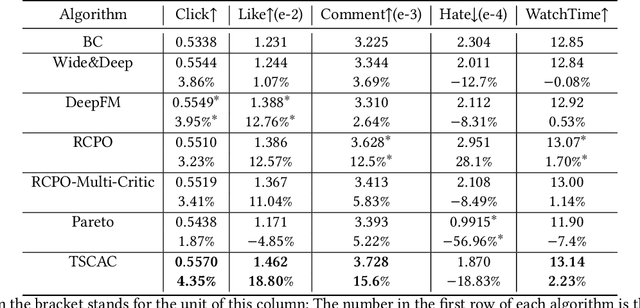
The wide popularity of short videos on social media poses new opportunities and challenges to optimize recommender systems on the video-sharing platforms. Users sequentially interact with the system and provide complex and multi-faceted responses, including watch time and various types of interactions with multiple videos. One the one hand, the platforms aims at optimizing the users' cumulative watch time (main goal) in long term, which can be effectively optimized by Reinforcement Learning. On the other hand, the platforms also needs to satisfy the constraint of accommodating the responses of multiple user interactions (auxiliary goals) such like, follow, share etc. In this paper, we formulate the problem of short video recommendation as a Constrained Markov Decision Process (CMDP). We find that traditional constrained reinforcement learning algorithms can not work well in this setting. We propose a novel two-stage constrained actor-critic method: At stage one, we learn individual policies to optimize each auxiliary signal. At stage two, we learn a policy to (i) optimize the main signal and (ii) stay close to policies learned at the first stage, which effectively guarantees the performance of this main policy on the auxiliaries. Through extensive offline evaluations, we demonstrate effectiveness of our method over alternatives in both optimizing the main goal as well as balancing the others. We further show the advantage of our method in live experiments of short video recommendations, where it significantly outperforms other baselines in terms of both watch time and interactions. Our approach has been fully launched in the production system to optimize user experiences on the platform.
* arXiv admin note: substantial text overlap with arXiv:2205.13248
Deconfounding Duration Bias in Watch-time Prediction for Video Recommendation
Jun 13, 2022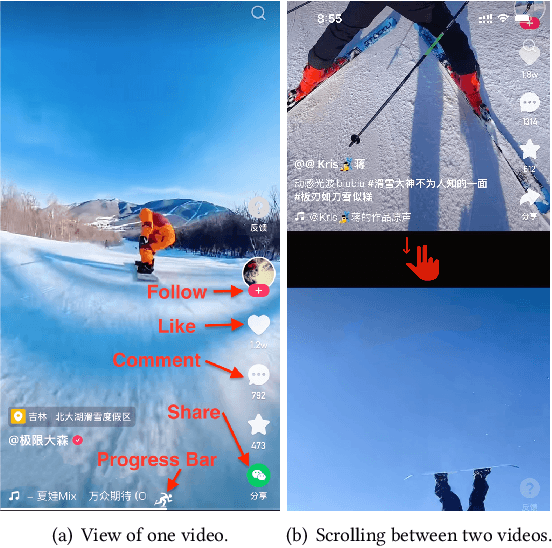

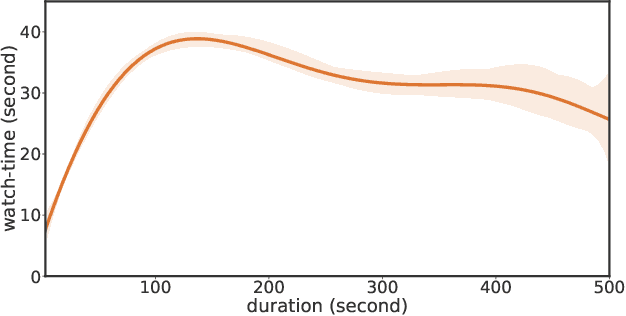
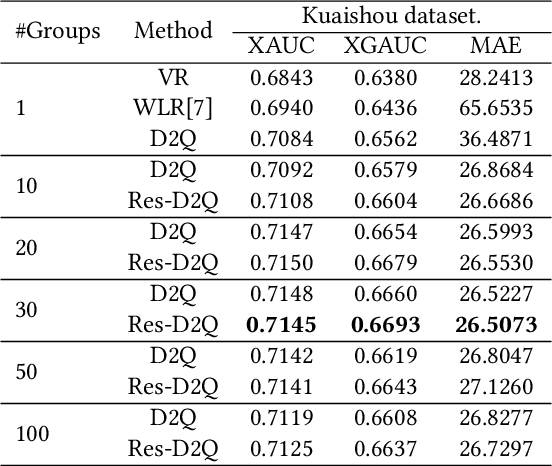
Watch-time prediction remains to be a key factor in reinforcing user engagement via video recommendations. It has become increasingly important given the ever-growing popularity of online videos. However, prediction of watch time not only depends on the match between the user and the video but is often mislead by the duration of the video itself. With the goal of improving watch time, recommendation is always biased towards videos with long duration. Models trained on this imbalanced data face the risk of bias amplification, which misguides platforms to over-recommend videos with long duration but overlook the underlying user interests. This paper presents the first work to study duration bias in watch-time prediction for video recommendation. We employ a causal graph illuminating that duration is a confounding factor that concurrently affects video exposure and watch-time prediction -- the first effect on video causes the bias issue and should be eliminated, while the second effect on watch time originates from video intrinsic characteristics and should be preserved. To remove the undesired bias but leverage the natural effect, we propose a Duration Deconfounded Quantile-based (D2Q) watch-time prediction framework, which allows for scalability to perform on industry production systems. Through extensive offline evaluation and live experiments, we showcase the effectiveness of this duration-deconfounding framework by significantly outperforming the state-of-the-art baselines. We have fully launched our approach on Kuaishou App, which has substantially improved real-time video consumption due to more accurate watch-time predictions.
ResAct: Reinforcing Long-term Engagement in Sequential Recommendation with Residual Actor
Jun 01, 2022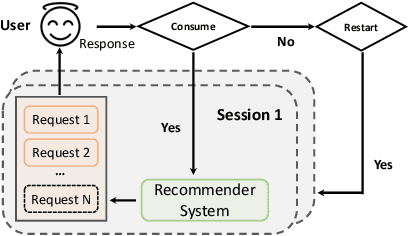
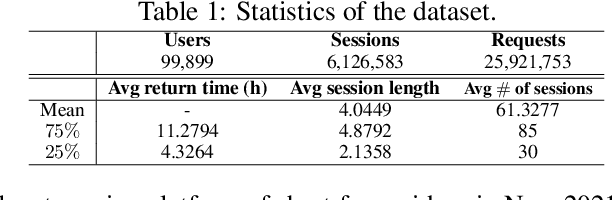
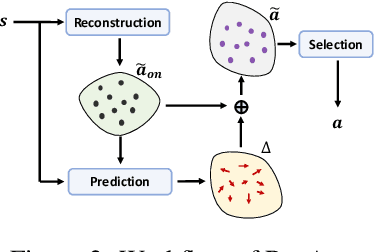

Long-term engagement is preferred over immediate engagement in sequential recommendation as it directly affects product operational metrics such as daily active users (DAUs) and dwell time. Meanwhile, reinforcement learning (RL) is widely regarded as a promising framework for optimizing long-term engagement in sequential recommendation. However, due to expensive online interactions, it is very difficult for RL algorithms to perform state-action value estimation, exploration and feature extraction when optimizing long-term engagement. In this paper, we propose ResAct which seeks a policy that is close to, but better than, the online-serving policy. In this way, we can collect sufficient data near the learned policy so that state-action values can be properly estimated, and there is no need to perform online exploration. Directly optimizing this policy is difficult due to the huge policy space. ResAct instead solves it by first reconstructing the online behaviors and then improving it. Our main contributions are fourfold. First, we design a generative model which reconstructs behaviors of the online-serving policy by sampling multiple action estimators. Second, we design an effective learning paradigm to train the residual actor which can output the residual for action improvement. Third, we facilitate the extraction of features with two information theoretical regularizers to confirm the expressiveness and conciseness of features. Fourth, we conduct extensive experiments on a real world dataset consisting of millions of sessions, and our method significantly outperforms the state-of-the-art baselines in various of long term engagement optimization tasks.
Constrained Reinforcement Learning for Short Video Recommendation
May 26, 2022
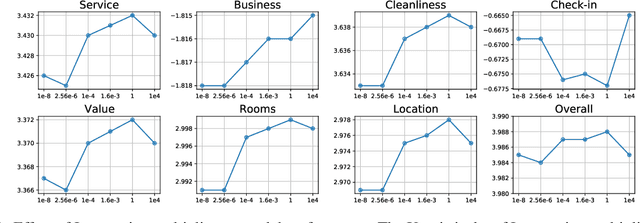
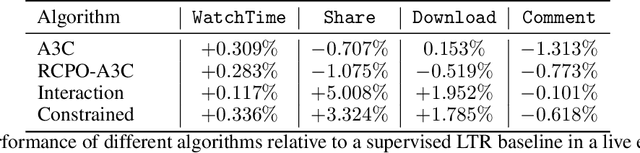
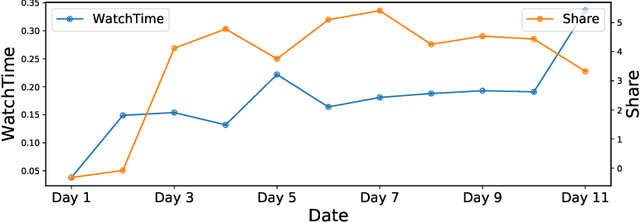
The wide popularity of short videos on social media poses new opportunities and challenges to optimize recommender systems on the video-sharing platforms. Users provide complex and multi-faceted responses towards recommendations, including watch time and various types of interactions with videos. As a result, established recommendation algorithms that concern a single objective are not adequate to meet this new demand of optimizing comprehensive user experiences. In this paper, we formulate the problem of short video recommendation as a constrained Markov Decision Process (MDP), where platforms want to optimize the main goal of user watch time in long term, with the constraint of accommodating the auxiliary responses of user interactions such as sharing/downloading videos. To solve the constrained MDP, we propose a two-stage reinforcement learning approach based on actor-critic framework. At stage one, we learn individual policies to optimize each auxiliary response. At stage two, we learn a policy to (i) optimize the main response and (ii) stay close to policies learned at the first stage, which effectively guarantees the performance of this main policy on the auxiliaries. Through extensive simulations, we demonstrate effectiveness of our approach over alternatives in both optimizing the main goal as well as balancing the others. We further show the advantage of our approach in live experiments of short video recommendations, where it significantly outperforms other baselines in terms of watch time and interactions from video views. Our approach has been fully launched in the production system to optimize user experiences on the platform.