 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling New Frontiers: Insights into Large Recommendation Models
Dec 01, 2024



Recommendation systems are essential for filtering data and retrieving relevant information across various applications. Recent advancements have seen these systems incorporate increasingly large embedding tables, scaling up to tens of terabytes for industrial use. However, the expansion of network parameters in traditional recommendation models has plateaued at tens of millions, limiting further benefits from increased embedding parameters. Inspired by the success of large language models (LLMs), a new approach has emerged that scales network parameters using innovative structures, enabling continued performance improvements. A significant development in this area is Meta's generative recommendation model HSTU, which illustrates the scaling laws of recommendation systems by expanding parameters to thousands of billions. This new paradigm has achieved substantial performance gains in online experiments. In this paper, we aim to enhance the understanding of scaling laws by conducting comprehensive evaluations of large recommendation models. Firstly, we investigate the scaling laws across different backbone architectures of the large recommendation models. Secondly, we conduct comprehensive ablation studies to explore the origins of these scaling laws. We then further assess the performance of HSTU, as the representative of large recommendation models, on complex user behavior modeling tasks to evaluate its applicability. Notably, we also analyze its effectiveness in ranking tasks for the first time. Finally, we offer insights into future directions for large recommendation models. Supplementary materials for our research are available on GitHub at https://github.com/USTC-StarTeam/Large-Recommendation-Models.
Two-Stage Constrained Actor-Critic for Short Video Recommendation
Feb 06, 2023
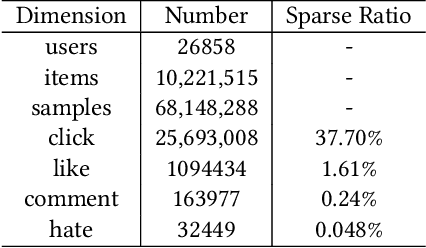
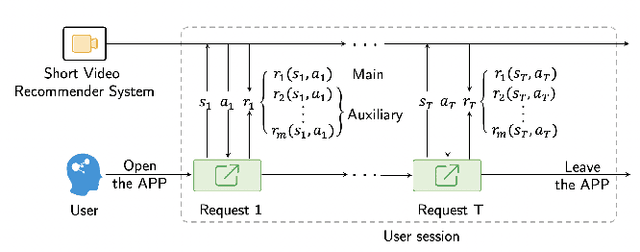
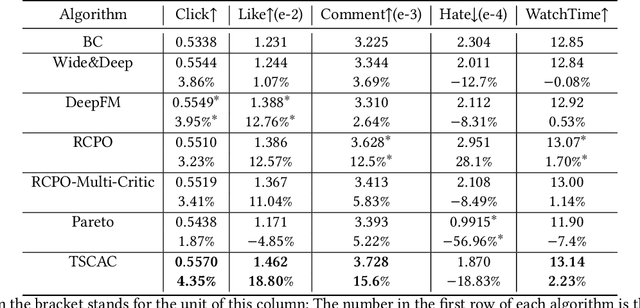
The wide popularity of short videos on social media poses new opportunities and challenges to optimize recommender systems on the video-sharing platforms. Users sequentially interact with the system and provide complex and multi-faceted responses, including watch time and various types of interactions with multiple videos. One the one hand, the platforms aims at optimizing the users' cumulative watch time (main goal) in long term, which can be effectively optimized by Reinforcement Learning. On the other hand, the platforms also needs to satisfy the constraint of accommodating the responses of multiple user interactions (auxiliary goals) such like, follow, share etc. In this paper, we formulate the problem of short video recommendation as a Constrained Markov Decision Process (CMDP). We find that traditional constrained reinforcement learning algorithms can not work well in this setting. We propose a novel two-stage constrained actor-critic method: At stage one, we learn individual policies to optimize each auxiliary signal. At stage two, we learn a policy to (i) optimize the main signal and (ii) stay close to policies learned at the first stage, which effectively guarantees the performance of this main policy on the auxiliaries. Through extensive offline evaluations, we demonstrate effectiveness of our method over alternatives in both optimizing the main goal as well as balancing the others. We further show the advantage of our method in live experiments of short video recommendations, where it significantly outperforms other baselines in terms of both watch time and interactions. Our approach has been fully launched in the production system to optimize user experiences on the platform.
* arXiv admin note: substantial text overlap with arXiv:2205.13248
Reinforcement Learning from Diverse Human Preferences
Jan 30, 2023The complexity of designing reward functions has been a major obstacle to the wide application of deep reinforcement learning (RL) techniques. Describing an agent's desired behaviors and properties can be difficult, even for experts. A new paradigm called reinforcement learning from human preferences (or preference-based RL) has emerged as a promising solution, in which reward functions are learned from human preference labels among behavior trajectories. However, existing methods for preference-based RL are limited by the need for accurate oracle preference labels. This paper addresses this limitation by developing a method for crowd-sourcing preference labels and learning from diverse human preferences. The key idea is to stabilize reward learning through regularization and correction in a latent space. To ensure temporal consistency, a strong constraint is imposed on the reward model that forces its latent space to be close to the prior distribution. Additionally, a confidence-based reward model ensembling method is designed to generate more stable and reliable predictions. The proposed method is tested on a variety of tasks in DMcontrol and Meta-world and has shown consistent and significant improvements over existing preference-based RL algorithms when learning from diverse feedback, paving the way for real-world applications of RL methods.
PrefRec: Preference-based Recommender Systems for Reinforcing Long-term User Engagement
Dec 06, 2022



Current advances in recommender systems have been remarkably successful in optimizing immediate engagement. However, long-term user engagement, a more desirable performance metric, remains difficult to improve. Meanwhile, recent reinforcement learning (RL) algorithms have shown their effectiveness in a variety of long-term goal optimization tasks. For this reason, RL is widely considered as a promising framework for optimizing long-term user engagement in recommendation. Despite being a promising approach, the application of RL heavily relies on well-designed rewards, but designing rewards related to long-term user engagement is quite difficult. To mitigate the problem, we propose a novel paradigm, Preference-based Recommender systems (PrefRec), which allows RL recommender systems to learn from preferences about users' historical behaviors rather than explicitly defined rewards. Such preferences are easily accessible through techniques such as crowdsourcing, as they do not require any expert knowledge. With PrefRec, we can fully exploit the advantages of RL in optimizing long-term goals, while avoiding complex reward engineering. PrefRec uses the preferences to automatically train a reward function in an end-to-end manner. The reward function is then used to generate learning signals to train the recommendation policy. Furthermore, we design an effective optimization method for PrefRec, which uses an additional value function, expectile regression and reward model pre-training to improve the performance. Extensive experiments are conducted on a variety of long-term user engagement optimization tasks. The results show that PrefRec significantly outperforms previous state-of-the-art methods in all the tasks.
ResAct: Reinforcing Long-term Engagement in Sequential Recommendation with Residual Actor
Jun 01, 2022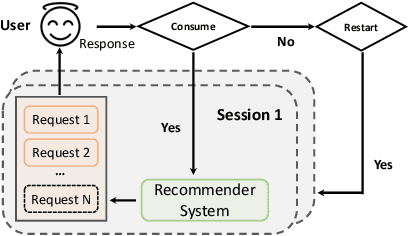
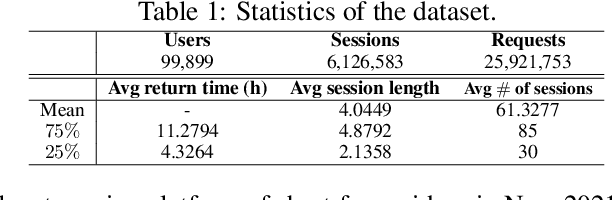
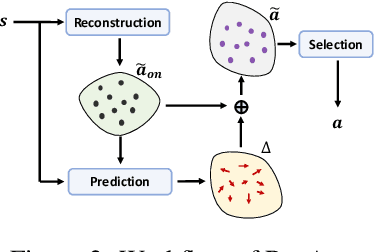

Long-term engagement is preferred over immediate engagement in sequential recommendation as it directly affects product operational metrics such as daily active users (DAUs) and dwell time. Meanwhile, reinforcement learning (RL) is widely regarded as a promising framework for optimizing long-term engagement in sequential recommendation. However, due to expensive online interactions, it is very difficult for RL algorithms to perform state-action value estimation, exploration and feature extraction when optimizing long-term engagement. In this paper, we propose ResAct which seeks a policy that is close to, but better than, the online-serving policy. In this way, we can collect sufficient data near the learned policy so that state-action values can be properly estimated, and there is no need to perform online exploration. Directly optimizing this policy is difficult due to the huge policy space. ResAct instead solves it by first reconstructing the online behaviors and then improving it. Our main contributions are fourfold. First, we design a generative model which reconstructs behaviors of the online-serving policy by sampling multiple action estimators. Second, we design an effective learning paradigm to train the residual actor which can output the residual for action improvement. Third, we facilitate the extraction of features with two information theoretical regularizers to confirm the expressiveness and conciseness of features. Fourth, we conduct extensive experiments on a real world dataset consisting of millions of sessions, and our method significantly outperforms the state-of-the-art baselines in various of long term engagement optimization tasks.
NSGZero: Efficiently Learning Non-Exploitable Policy in Large-Scale Network Security Games with Neural Monte Carlo Tree Search
Jan 17, 2022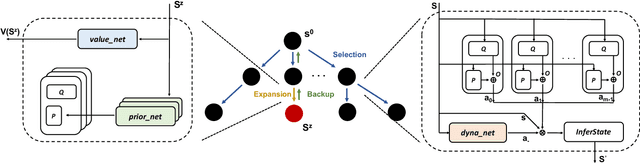

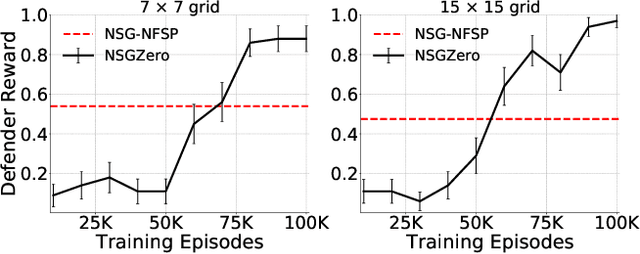
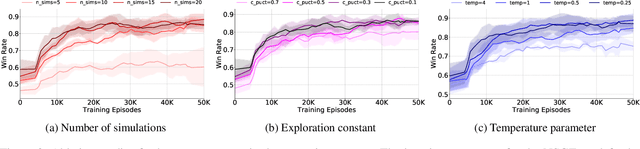
How resources are deployed to secure critical targets in networks can be modelled by Network Security Games (NSGs). While recent advances in deep learning (DL) provide a powerful approach to dealing with large-scale NSGs, DL methods such as NSG-NFSP suffer from the problem of data inefficiency. Furthermore, due to centralized control, they cannot scale to scenarios with a large number of resources. In this paper, we propose a novel DL-based method, NSGZero, to learn a non-exploitable policy in NSGs. NSGZero improves data efficiency by performing planning with neural Monte Carlo Tree Search (MCTS). Our main contributions are threefold. First, we design deep neural networks (DNNs) to perform neural MCTS in NSGs. Second, we enable neural MCTS with decentralized control, making NSGZero applicable to NSGs with many resources. Third, we provide an efficient learning paradigm, to achieve joint training of the DNNs in NSGZero. Compared to state-of-the-art algorithms, our method achieves significantly better data efficiency and scalability.
Mis-spoke or mis-lead: Achieving Robustness in Multi-Agent Communicative Reinforcement Learning
Aug 09, 2021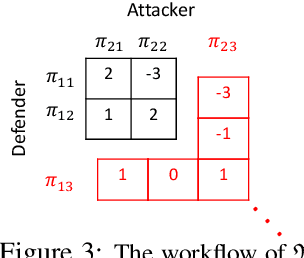
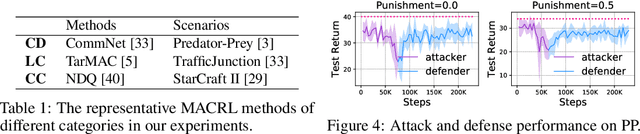
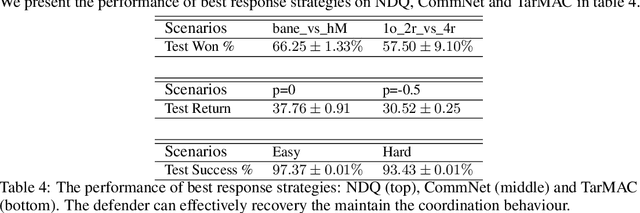

Recent studies in multi-agent communicative reinforcement learning (MACRL) demonstrate that multi-agent coordination can be significantly improved when communication between agents is allowed. Meanwhile, advances in adversarial machine learning (ML) have shown that ML and reinforcement learning (RL) models are vulnerable to a variety of attacks that significantly degrade the performance of learned behaviours. However, despite the obvious and growing importance, the combination of adversarial ML and MACRL remains largely uninvestigated. In this paper, we make the first step towards conducting message attacks on MACRL methods. In our formulation, one agent in the cooperating group is taken over by an adversary and can send malicious messages to disrupt a deployed MACRL-based coordinated strategy during the deployment phase. We further our study by developing a defence method via message reconstruction. Finally, we address the resulting arms race, i.e., we consider the ability of the malicious agent to adapt to the changing and improving defensive communicative policies of the benign agents. Specifically, we model the adversarial MACRL problem as a two-player zero-sum game and then utilize Policy-Space Response Oracle to achieve communication robustness. Empirically, we demonstrate that MACRL methods are vulnerable to message attacks while our defence method the game-theoretic framework can effectively improve the robustness of MACRL.
Solving Large-Scale Extensive-Form Network Security Games via Neural Fictitious Self-Play
Jun 02, 2021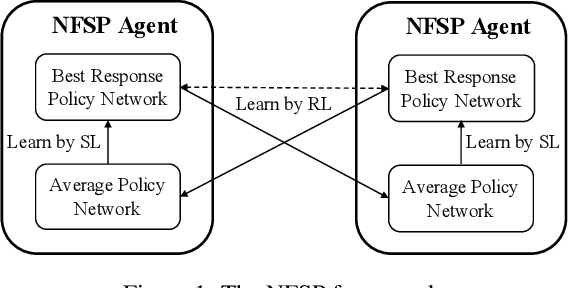
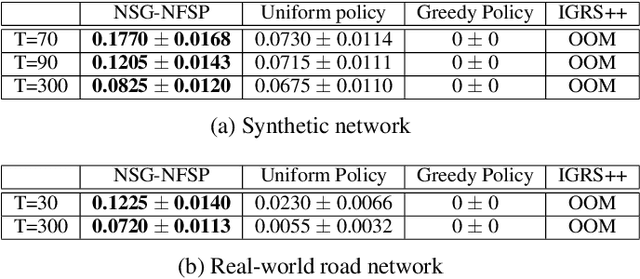
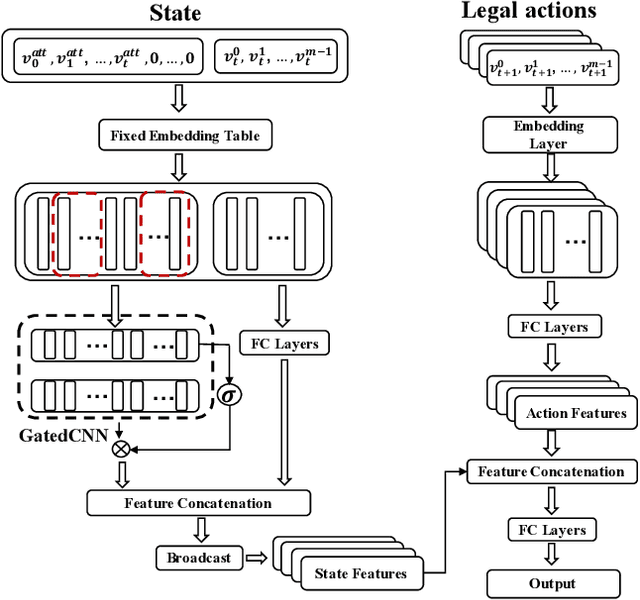

Securing networked infrastructures is important in the real world. The problem of deploying security resources to protect against an attacker in networked domains can be modeled as Network Security Games (NSGs). Unfortunately, existing approaches, including the deep learning-based approaches, are inefficient to solve large-scale extensive-form NSGs. In this paper, we propose a novel learning paradigm, NSG-NFSP, to solve large-scale extensive-form NSGs based on Neural Fictitious Self-Play (NFSP). Our main contributions include: i) reforming the best response (BR) policy network in NFSP to be a mapping from action-state pair to action-value, to make the calculation of BR possible in NSGs; ii) converting the average policy network of an NFSP agent into a metric-based classifier, helping the agent to assign distributions only on legal actions rather than all actions; iii) enabling NFSP with high-level actions, which can benefit training efficiency and stability in NSGs; and iv) leveraging information contained in graphs of NSGs by learning efficient graph node embeddings. Our algorithm significantly outperforms state-of-the-art algorithms in both scalability and solution quality.
CFR-MIX: Solving Imperfect Information Extensive-Form Games with Combinatorial Action Space
May 18, 2021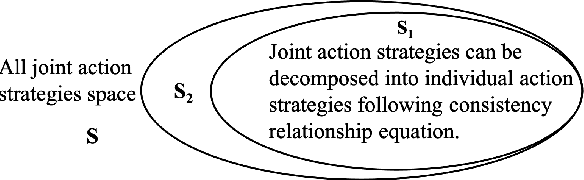
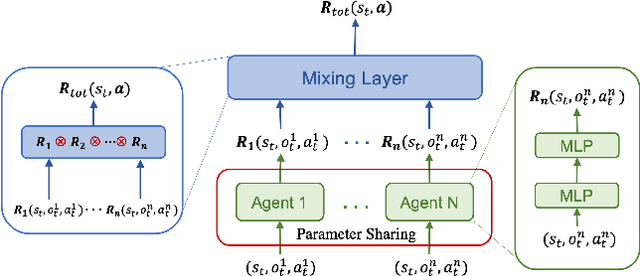
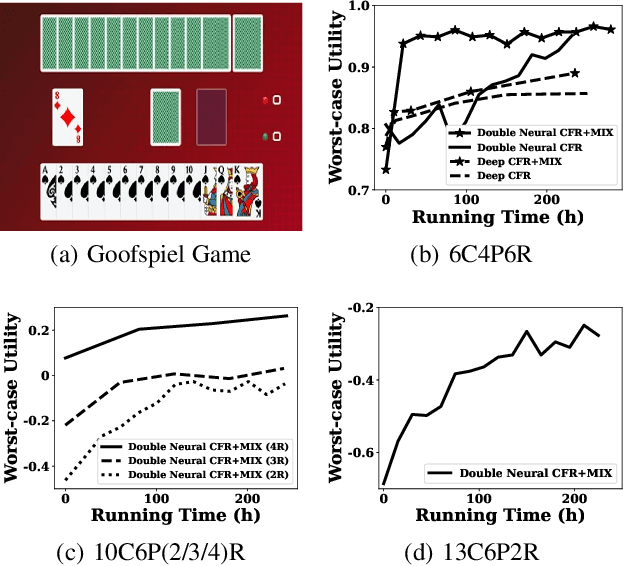
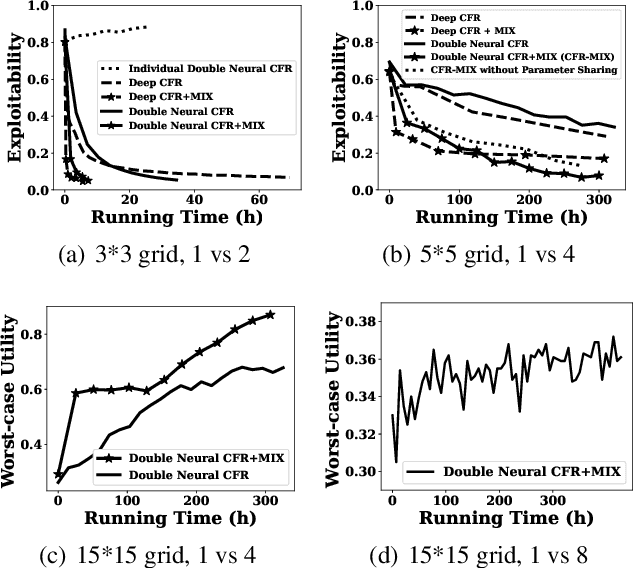
In many real-world scenarios, a team of agents coordinate with each other to compete against an opponent. The challenge of solving this type of game is that the team's joint action space grows exponentially with the number of agents, which results in the inefficiency of the existing algorithms, e.g., Counterfactual Regret Minimization (CFR). To address this problem, we propose a new framework of CFR: CFR-MIX. Firstly, we propose a new strategy representation that represents a joint action strategy using individual strategies of all agents and a consistency relationship to maintain the cooperation between agents. To compute the equilibrium with individual strategies under the CFR framework, we transform the consistency relationship between strategies to the consistency relationship between the cumulative regret values. Furthermore, we propose a novel decomposition method over cumulative regret values to guarantee the consistency relationship between the cumulative regret values. Finally, we introduce our new algorithm CFR-MIX which employs a mixing layer to estimate cumulative regret values of joint actions as a non-linear combination of cumulative regret values of individual actions. Experimental results show that CFR-MIX outperforms existing algorithms on various games significantly.
One-Shot Image Classification by Learning to Restore Prototypes
May 04, 2020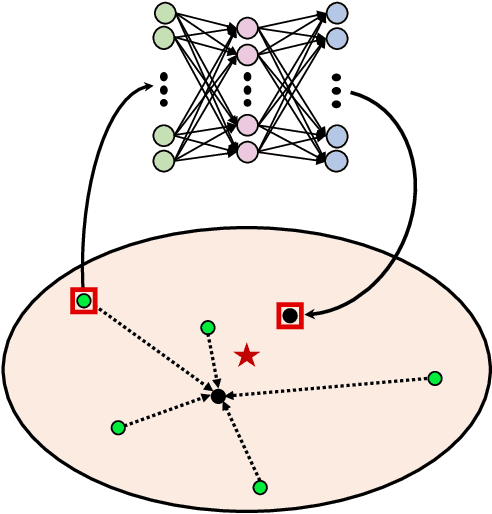



One-shot image classification aims to train image classifiers over the dataset with only one image per category. It is challenging for modern deep neural networks that typically require hundreds or thousands of images per class. In this paper, we adopt metric learning for this problem, which has been applied for few- and many-shot image classification by comparing the distance between the test image and the center of each class in the feature space. However, for one-shot learning, the existing metric learning approaches would suffer poor performance because the single training image may not be representative of the class. For example, if the image is far away from the class center in the feature space, the metric-learning based algorithms are unlikely to make correct predictions for the test images because the decision boundary is shifted by this noisy image. To address this issue, we propose a simple yet effective regression model, denoted by RestoreNet, which learns a class agnostic transformation on the image feature to move the image closer to the class center in the feature space. Experiments demonstrate that RestoreNet obtains superior performance over the state-of-the-art methods on a broad range of datasets. Moreover, RestoreNet can be easily combined with other methods to achieve further improvement.