 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKilling Two Birds with One Stone: Unifying Retrieval and Ranking with a Single Generative Recommendation Model
Apr 23, 2025In recommendation systems, the traditional multi-stage paradigm, which includes retrieval and ranking, often suffers from information loss between stages and diminishes performance. Recent advances in generative models, inspired by natural language processing, suggest the potential for unifying these stages to mitigate such loss. This paper presents the Unified Generative Recommendation Framework (UniGRF), a novel approach that integrates retrieval and ranking into a single generative model. By treating both stages as sequence generation tasks, UniGRF enables sufficient information sharing without additional computational costs, while remaining model-agnostic. To enhance inter-stage collaboration, UniGRF introduces a ranking-driven enhancer module that leverages the precision of the ranking stage to refine retrieval processes, creating an enhancement loop. Besides, a gradient-guided adaptive weighter is incorporated to dynamically balance the optimization of retrieval and ranking, ensuring synchronized performance improvements. Extensive experiments demonstrate that UniGRF significantly outperforms existing models on benchmark datasets, confirming its effectiveness in facilitating information transfer. Ablation studies and further experiments reveal that UniGRF not only promotes efficient collaboration between stages but also achieves synchronized optimization. UniGRF provides an effective, scalable, and compatible framework for generative recommendation systems.
Scaling New Frontiers: Insights into Large Recommendation Models
Dec 01, 2024



Recommendation systems are essential for filtering data and retrieving relevant information across various applications. Recent advancements have seen these systems incorporate increasingly large embedding tables, scaling up to tens of terabytes for industrial use. However, the expansion of network parameters in traditional recommendation models has plateaued at tens of millions, limiting further benefits from increased embedding parameters. Inspired by the success of large language models (LLMs), a new approach has emerged that scales network parameters using innovative structures, enabling continued performance improvements. A significant development in this area is Meta's generative recommendation model HSTU, which illustrates the scaling laws of recommendation systems by expanding parameters to thousands of billions. This new paradigm has achieved substantial performance gains in online experiments. In this paper, we aim to enhance the understanding of scaling laws by conducting comprehensive evaluations of large recommendation models. Firstly, we investigate the scaling laws across different backbone architectures of the large recommendation models. Secondly, we conduct comprehensive ablation studies to explore the origins of these scaling laws. We then further assess the performance of HSTU, as the representative of large recommendation models, on complex user behavior modeling tasks to evaluate its applicability. Notably, we also analyze its effectiveness in ranking tasks for the first time. Finally, we offer insights into future directions for large recommendation models. Supplementary materials for our research are available on GitHub at https://github.com/USTC-StarTeam/Large-Recommendation-Models.
CoIR: A Comprehensive Benchmark for Code Information Retrieval Models
Jul 03, 2024



Despite the substantial success of Information Retrieval (IR) in various NLP tasks, most IR systems predominantly handle queries and corpora in natural language, neglecting the domain of code retrieval. Code retrieval is critically important yet remains under-explored, with existing methods and benchmarks inadequately representing the diversity of code in various domains and tasks. Addressing this gap, we present \textbf{\name} (\textbf{Co}de \textbf{I}nformation \textbf{R}etrieval Benchmark), a robust and comprehensive benchmark specifically designed to assess code retrieval capabilities. \name comprises \textbf{ten} meticulously curated code datasets, spanning \textbf{eight} distinctive retrieval tasks across \textbf{seven} diverse domains. We first discuss the construction of \name and its diverse dataset composition. Further, we evaluate nine widely used retrieval models using \name, uncovering significant difficulties in performing code retrieval tasks even with state-of-the-art systems. To facilitate easy adoption and integration within existing research workflows, \name has been developed as a user-friendly Python framework, readily installable via pip. It shares same data schema as other popular benchmarks like MTEB and BEIR, enabling seamless cross-benchmark evaluations. Through \name, we aim to invigorate research in the code retrieval domain, providing a versatile benchmarking tool that encourages further development and exploration of code retrieval systems\footnote{\url{ https://github.com/CoIR-team/coir}}.
CtrlA: Adaptive Retrieval-Augmented Generation via Probe-Guided Control
May 29, 2024



Retrieval-augmented generation (RAG) has emerged as a promising solution for mitigating hallucinations of large language models (LLMs) with retrieved external knowledge. Adaptive RAG enhances this approach by dynamically assessing the retrieval necessity, aiming to balance external and internal knowledge usage. However, existing adaptive RAG methods primarily realize retrieval on demand by relying on superficially verbalize-based or probability-based feedback of LLMs, or directly fine-tuning LLMs via carefully crafted datasets, resulting in unreliable retrieval necessity decisions, heavy extra costs, and sub-optimal response generation. We present the first attempts to delve into the internal states of LLMs to mitigate such issues by introducing an effective probe-guided adaptive RAG framework, termed CtrlA. Specifically, CtrlA employs an honesty probe to regulate the LLM's behavior by manipulating its representations for increased honesty, and a confidence probe to monitor the internal states of LLM and assess confidence levels, determining the retrieval necessity during generation. Experiments show that CtrlA is superior to existing adaptive RAG methods on a diverse set of tasks, the honesty control can effectively make LLMs more honest and confidence monitoring is proven to be a promising indicator of retrieval trigger. Our codes are available at https://github.com/HSLiu-Initial/CtrlA.git.
Multi-view Content-aware Indexing for Long Document Retrieval
Apr 23, 2024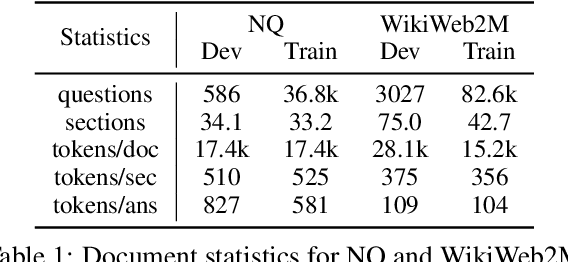
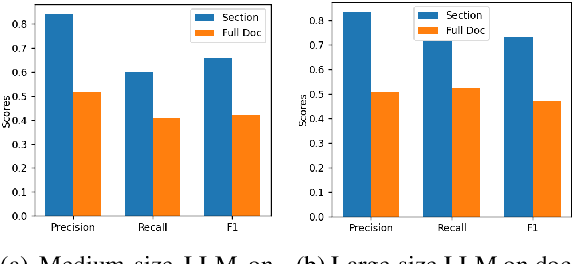
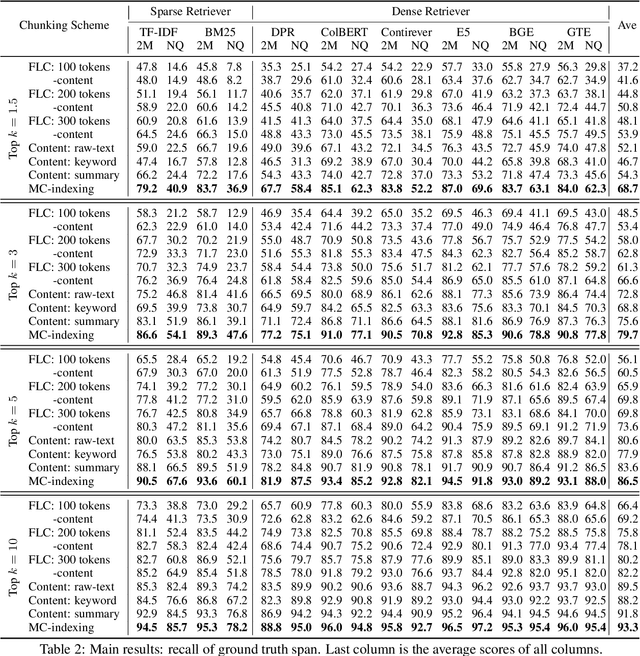
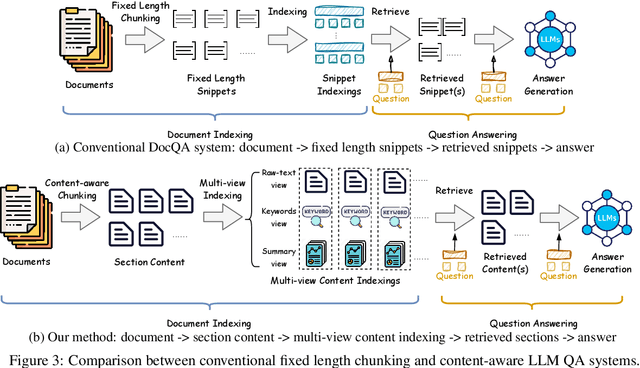
Long document question answering (DocQA) aims to answer questions from long documents over 10k words. They usually contain content structures such as sections, sub-sections, and paragraph demarcations. However, the indexing methods of long documents remain under-explored, while existing systems generally employ fixed-length chunking. As they do not consider content structures, the resultant chunks can exclude vital information or include irrelevant content. Motivated by this, we propose the Multi-view Content-aware indexing (MC-indexing) for more effective long DocQA via (i) segment structured document into content chunks, and (ii) represent each content chunk in raw-text, keywords, and summary views. We highlight that MC-indexing requires neither training nor fine-tuning. Having plug-and-play capability, it can be seamlessly integrated with any retrievers to boost their performance. Besides, we propose a long DocQA dataset that includes not only question-answer pair, but also document structure and answer scope. When compared to state-of-art chunking schemes, MC-indexing has significantly increased the recall by 42.8%, 30.0%, 23.9%, and 16.3% via top k= 1.5, 3, 5, and 10 respectively. These improved scores are the average of 8 widely used retrievers (2 sparse and 6 dense) via extensive experiments.