 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgramming over Thinking: Efficient and Robust Multi-Constraint Planning
Jan 14, 2026Multi-constraint planning involves identifying, evaluating, and refining candidate plans while satisfying multiple, potentially conflicting constraints. Existing large language model (LLM) approaches face fundamental limitations in this domain. Pure reasoning paradigms, which rely on long natural language chains, are prone to inconsistency, error accumulation, and prohibitive cost as constraints compound. Conversely, LLMs combined with coding- or solver-based strategies lack flexibility: they often generate problem-specific code from scratch or depend on fixed solvers, failing to capture generalizable logic across diverse problems. To address these challenges, we introduce the Scalable COde Planning Engine (SCOPE), a framework that disentangles query-specific reasoning from generic code execution. By separating reasoning from execution, SCOPE produces solver functions that are consistent, deterministic, and reusable across queries while requiring only minimal changes to input parameters. SCOPE achieves state-of-the-art performance while lowering cost and latency. For example, with GPT-4o, it reaches 93.1% success on TravelPlanner, a 61.6% gain over the best baseline (CoT) while cutting inference cost by 1.4x and time by ~4.67x. Code is available at https://github.com/DerrickGXD/SCOPE.
Meta-Task Planning for Language Agents
May 28, 2024



The rapid advancement of neural language models has sparked a new surge of intelligent agent research. Unlike traditional agents, large language model-based agents (LLM agents) have emerged as a promising paradigm for achieving artificial general intelligence (AGI) due to their superior reasoning and generalization capabilities. Effective planning is crucial for the success of LLM agents in real-world tasks, making it a highly pursued topic in the community. Current planning methods typically translate tasks into executable action sequences. However, determining a feasible or optimal sequence for complex tasks at fine granularity, which often requires compositing long chains of heterogeneous actions, remains challenging. This paper introduces Meta-Task Planning (MTP), a zero-shot methodology for collaborative LLM-based multi-agent systems that simplifies complex task planning by decomposing it into a hierarchy of subordinate tasks, or meta-tasks. Each meta-task is then mapped into executable actions. MTP was assessed on two rigorous benchmarks, TravelPlanner and API-Bank. Notably, MTP achieved an average $\sim40\%$ success rate on TravelPlanner, significantly higher than the state-of-the-art (SOTA) baseline ($2.92\%$), and outperforming $LLM_{api}$-4 with ReAct on API-Bank by $\sim14\%$, showing the immense potential of integrating LLM with multi-agent systems.
Multi-view Content-aware Indexing for Long Document Retrieval
Apr 23, 2024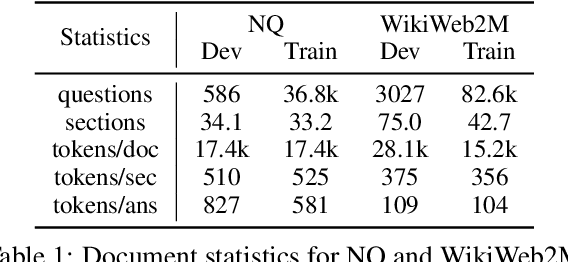
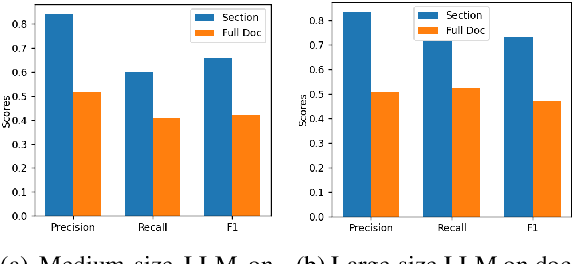
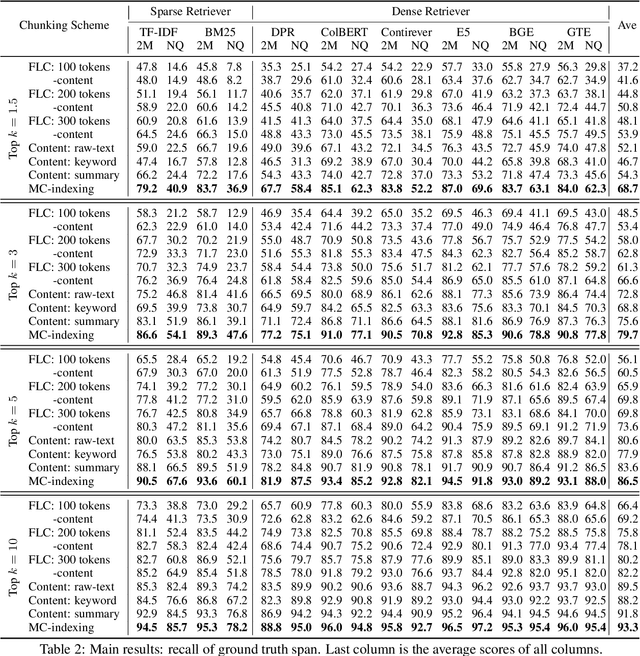
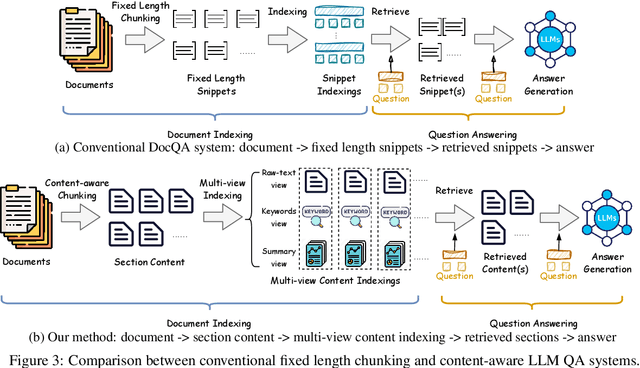
Long document question answering (DocQA) aims to answer questions from long documents over 10k words. They usually contain content structures such as sections, sub-sections, and paragraph demarcations. However, the indexing methods of long documents remain under-explored, while existing systems generally employ fixed-length chunking. As they do not consider content structures, the resultant chunks can exclude vital information or include irrelevant content. Motivated by this, we propose the Multi-view Content-aware indexing (MC-indexing) for more effective long DocQA via (i) segment structured document into content chunks, and (ii) represent each content chunk in raw-text, keywords, and summary views. We highlight that MC-indexing requires neither training nor fine-tuning. Having plug-and-play capability, it can be seamlessly integrated with any retrievers to boost their performance. Besides, we propose a long DocQA dataset that includes not only question-answer pair, but also document structure and answer scope. When compared to state-of-art chunking schemes, MC-indexing has significantly increased the recall by 42.8%, 30.0%, 23.9%, and 16.3% via top k= 1.5, 3, 5, and 10 respectively. These improved scores are the average of 8 widely used retrievers (2 sparse and 6 dense) via extensive experiments.
Aligning Crowd Feedback via Distributional Preference Reward Modeling
Feb 21, 2024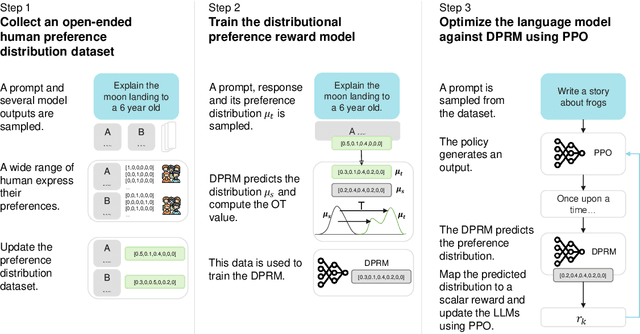



Deep Reinforcement Learning is widely used for aligning Large Language Models (LLM) with human preference. However, the conventional reward modelling has predominantly depended on human annotations provided by a select cohort of individuals. Such dependence may unintentionally result in models that are skewed to reflect the inclinations of these annotators, thereby failing to represent the expectations of the wider population adequately. In this paper, we introduce the Distributional Preference Reward Model (DPRM), a simple yet effective framework to align large language models with a diverse set of human preferences. To this end, we characterize the preferences by a beta distribution, which can dynamically adapt to fluctuations in preference trends. On top of that, we design an optimal-transportation-based loss to calibrate DPRM to align with the preference distribution. Finally, the expected reward is utilized to fine-tune an LLM policy to generate responses favoured by the population. Our experiments show that DPRM significantly enhances the alignment of LLMs with population preference, yielding more accurate, unbiased, and contextually appropriate responses.
Automatic Unit Test Data Generation and Actor-Critic Reinforcement Learning for Code Synthesis
Oct 20, 2023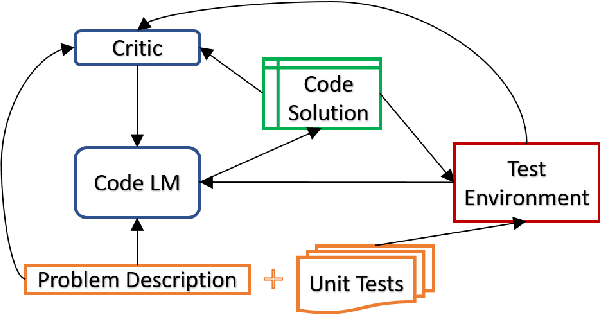
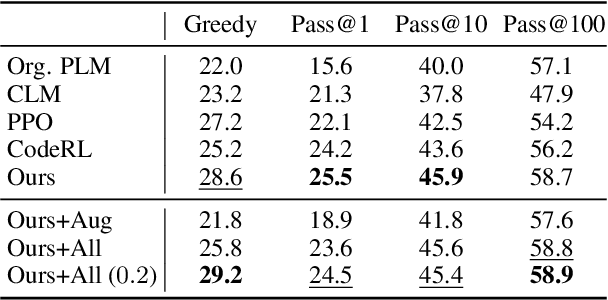

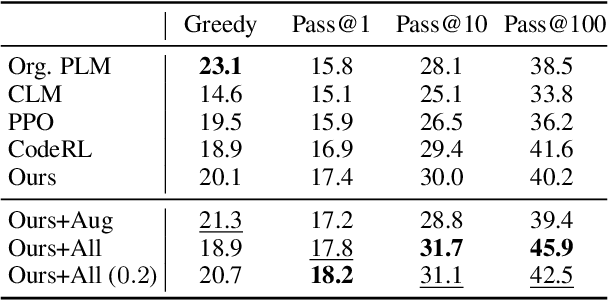
The advent of large pre-trained language models in the domain of Code Synthesis has shown remarkable performance on various benchmarks, treating the problem of Code Generation in a fashion similar to Natural Language Generation, trained with a Language Modelling (LM) objective. In addition, the property of programming language code being precisely evaluable with respect to its semantics -- through the use of Unit Tests to check its functional correctness -- lends itself to using Reinforcement Learning (RL) as a further training paradigm. Previous work has shown that RL can be applied as such to improve models' coding capabilities; however, such RL-based methods rely on a reward signal based on defined Unit Tests, which are much harder to obtain compared to the huge crawled code datasets used in LM objectives. In this work, we present a novel approach to automatically obtain data consisting of function signatures and associated Unit Tests, suitable for RL training of Code Synthesis models. We also introduce a straightforward, simple yet effective Actor-Critic RL training scheme and show that it, in conjunction with automatically generated training data, leads to improvement of a pre-trained code language model's performance by up to 9.9% improvement over the original underlying code synthesis LM, and up to 4.3% over RL-based models trained with standard PPO or CodeRL.