 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNewclid: A User-Friendly Replacement for AlphaGeometry
Nov 18, 2024



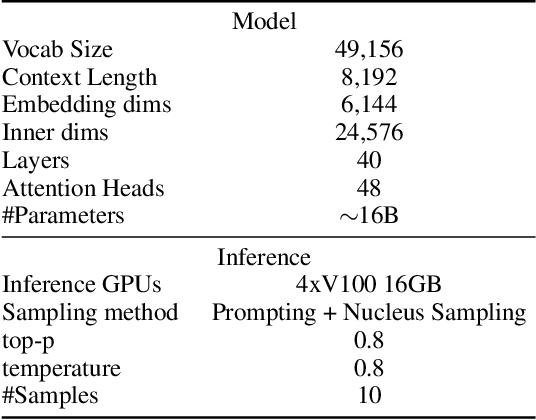
We introduce a new symbolic solver for geometry, called Newclid, which is based on AlphaGeometry. Newclid contains a symbolic solver called DDARN (derived from DDAR-Newclid), which is a significant refactoring and upgrade of AlphaGeometry's DDAR symbolic solver by being more user-friendly - both for the end user as well as for a programmer wishing to extend the codebase. For the programmer, improvements include a modularized codebase and new debugging and visualization tools. For the user, Newclid contains a new command line interface (CLI) that provides interfaces for agents to guide DDARN. DDARN is flexible with respect to its internal reasoning, which can be steered by agents. Further, we support input from GeoGebra to make Newclid accessible for educational contexts. Further, the scope of problems that Newclid can solve has been expanded to include the ability to have an improved understanding of metric geometry concepts (length, angle) and to use theorems such as the Pythagorean theorem in proofs. Bugs have been fixed, and reproducibility has been improved. Lastly, we re-evaluated the five remaining problems from the original AG-30 dataset that AlphaGeometry was not able to solve and contrasted them with the abilities of DDARN, running in breadth-first-search agentic mode (which corresponds to how DDARN runs by default), finding that DDARN solves an additional problem. We have open-sourced our code under: https://github.com/LMCRC/Newclid
$α$VIL: Learning to Leverage Auxiliary Tasks for Multitask Learning
May 13, 2024



Multitask Learning is a Machine Learning paradigm that aims to train a range of (usually related) tasks with the help of a shared model. While the goal is often to improve the joint performance of all training tasks, another approach is to focus on the performance of a specific target task, while treating the remaining ones as auxiliary data from which to possibly leverage positive transfer towards the target during training. In such settings, it becomes important to estimate the positive or negative influence auxiliary tasks will have on the target. While many ways have been proposed to estimate task weights before or during training they typically rely on heuristics or extensive search of the weighting space. We propose a novel method called $\alpha$-Variable Importance Learning ($\alpha$VIL) that is able to adjust task weights dynamically during model training, by making direct use of task-specific updates of the underlying model's parameters between training epochs. Experiments indicate that $\alpha$VIL is able to outperform other Multitask Learning approaches in a variety of settings. To our knowledge, this is the first attempt at making direct use of model updates for task weight estimation.
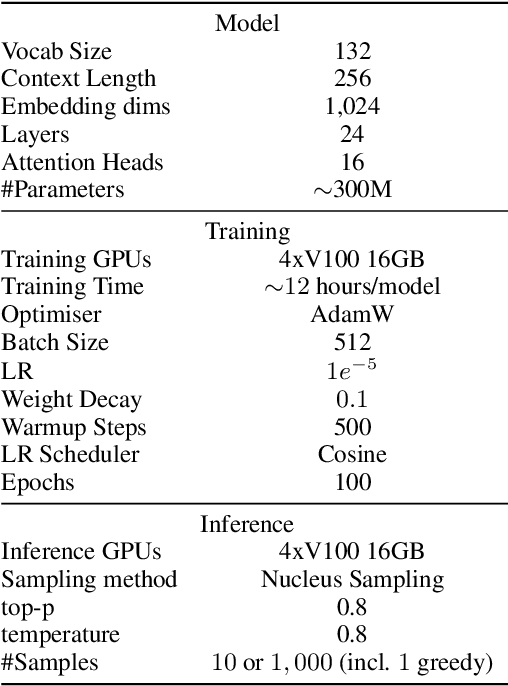
Automatic Unit Test Data Generation and Actor-Critic Reinforcement Learning for Code Synthesis
Oct 20, 2023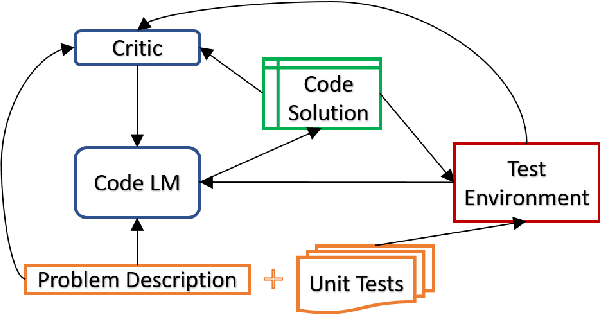
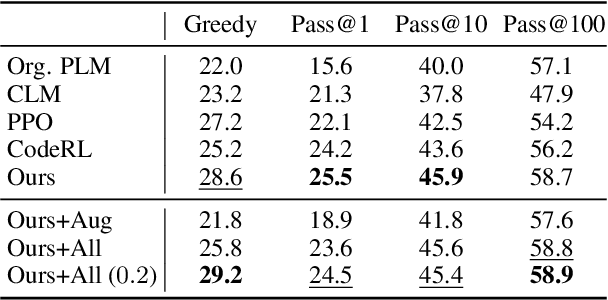

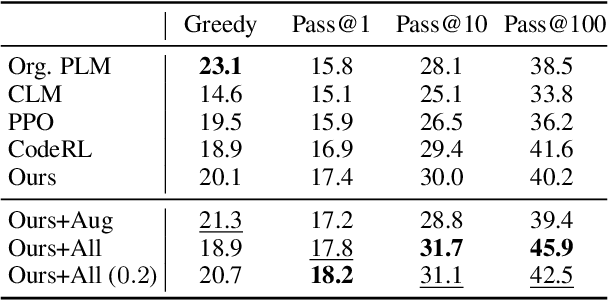
The advent of large pre-trained language models in the domain of Code Synthesis has shown remarkable performance on various benchmarks, treating the problem of Code Generation in a fashion similar to Natural Language Generation, trained with a Language Modelling (LM) objective. In addition, the property of programming language code being precisely evaluable with respect to its semantics -- through the use of Unit Tests to check its functional correctness -- lends itself to using Reinforcement Learning (RL) as a further training paradigm. Previous work has shown that RL can be applied as such to improve models' coding capabilities; however, such RL-based methods rely on a reward signal based on defined Unit Tests, which are much harder to obtain compared to the huge crawled code datasets used in LM objectives. In this work, we present a novel approach to automatically obtain data consisting of function signatures and associated Unit Tests, suitable for RL training of Code Synthesis models. We also introduce a straightforward, simple yet effective Actor-Critic RL training scheme and show that it, in conjunction with automatically generated training data, leads to improvement of a pre-trained code language model's performance by up to 9.9% improvement over the original underlying code synthesis LM, and up to 4.3% over RL-based models trained with standard PPO or CodeRL.
The Regular Expression Inference Challenge
Aug 15, 2023
We propose \emph{regular expression inference (REI)} as a challenge for code/language modelling, and the wider machine learning community. REI is a supervised machine learning (ML) and program synthesis task, and poses the problem of finding minimal regular expressions from examples: Given two finite sets of strings $P$ and $N$ and a cost function $\text{cost}(\cdot)$, the task is to generate an expression $r$ that accepts all strings in $P$ and rejects all strings in $N$, while no other such expression $r'$ exists with $\text{cost}(r')<\text{cost}(r)$. REI has advantages as a challenge problem: (i) regular expressions are well-known, widely used, and a natural idealisation of code; (ii) REI's asymptotic worst-case complexity is well understood; (iii) REI has a small number of easy to understand parameters (e.g.~$P$ or $N$ cardinality, string lengths of examples, or the cost function); this lets us easily finetune REI-hardness; (iv) REI is an unsolved problem for deep learning based ML. Recently, an REI solver was implemented on GPUs, using program synthesis techniques. This enabled, for the first time, fast generation of minimal expressions for complex REI instances. Building on this advance, we generate and publish the first large-scale datasets for REI, and devise and evaluate several initial heuristic and machine learning baselines. We invite the community to participate and explore ML methods that learn to solve REI problems. We believe that progress in REI directly translates to code/language modelling.
Graph Attention with Hierarchies for Multi-hop Question Answering
Jan 27, 2023Multi-hop QA (Question Answering) is the task of finding the answer to a question across multiple documents. In recent years, a number of Deep Learning-based approaches have been proposed to tackle this complex task, as well as a few standard benchmarks to assess models Multi-hop QA capabilities. In this paper, we focus on the well-established HotpotQA benchmark dataset, which requires models to perform answer span extraction as well as support sentence prediction. We present two extensions to the SOTA Graph Neural Network (GNN) based model for HotpotQA, Hierarchical Graph Network (HGN): (i) we complete the original hierarchical structure by introducing new edges between the query and context sentence nodes; (ii) in the graph propagation step, we propose a novel extension to Hierarchical Graph Attention Network GATH (Graph ATtention with Hierarchies) that makes use of the graph hierarchy to update the node representations in a sequential fashion. Experiments on HotpotQA demonstrate the efficiency of the proposed modifications and support our assumptions about the effects of model related variables.
Relational Graph Convolutional Neural Networks for Multihop Reasoning: A Comparative Study
Oct 13, 2022
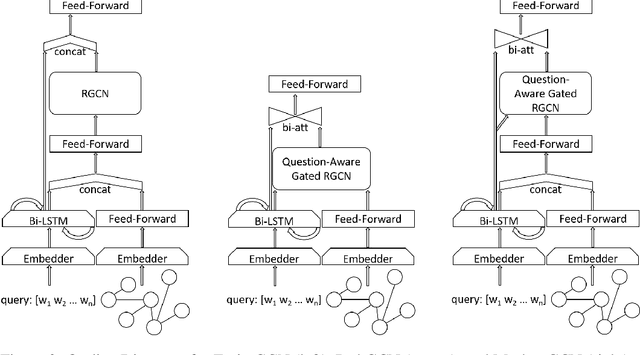


Multihop Question Answering is a complex Natural Language Processing task that requires multiple steps of reasoning to find the correct answer to a given question. Previous research has explored the use of models based on Graph Neural Networks for tackling this task. Various architectures have been proposed, including Relational Graph Convolutional Networks (RGCN). For these many node types and relations between them have been introduced, such as simple entity co-occurrences, modelling coreferences, or "reasoning paths" from questions to answers via intermediary entities. Nevertheless, a thoughtful analysis on which relations, node types, embeddings and architecture are the most beneficial for this task is still missing. In this paper we explore a number of RGCN-based Multihop QA models, graph relations, and node embeddings, and empirically explore the influence of each on Multihop QA performance on the WikiHop dataset.
Structured Q-learning For Antibody Design
Sep 13, 2022
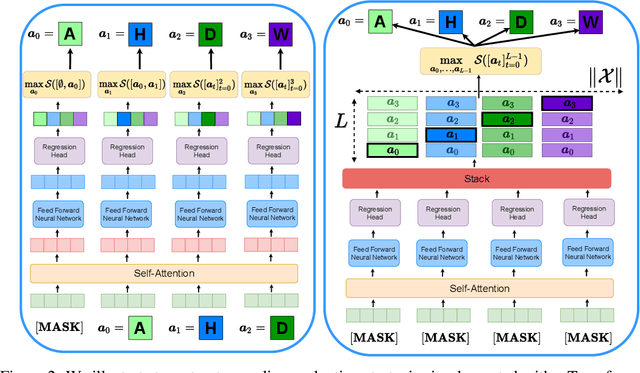
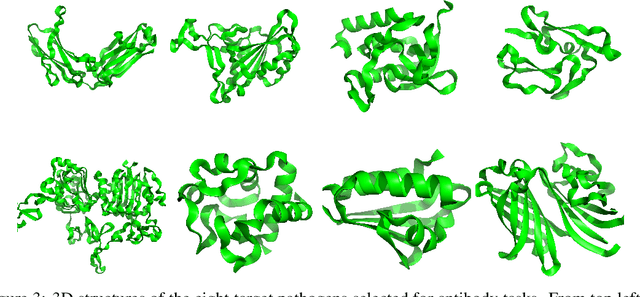
Optimizing combinatorial structures is core to many real-world problems, such as those encountered in life sciences. For example, one of the crucial steps involved in antibody design is to find an arrangement of amino acids in a protein sequence that improves its binding with a pathogen. Combinatorial optimization of antibodies is difficult due to extremely large search spaces and non-linear objectives. Even for modest antibody design problems, where proteins have a sequence length of eleven, we are faced with searching over 2.05 x 10^14 structures. Applying traditional Reinforcement Learning algorithms such as Q-learning to combinatorial optimization results in poor performance. We propose Structured Q-learning (SQL), an extension of Q-learning that incorporates structural priors for combinatorial optimization. Using a molecular docking simulator, we demonstrate that SQL finds high binding energy sequences and performs favourably against baselines on eight challenging antibody design tasks, including designing antibodies for SARS-COV.
Improving Commonsense Causal Reasoning by Adversarial Training and Data Augmentation
Jan 13, 2021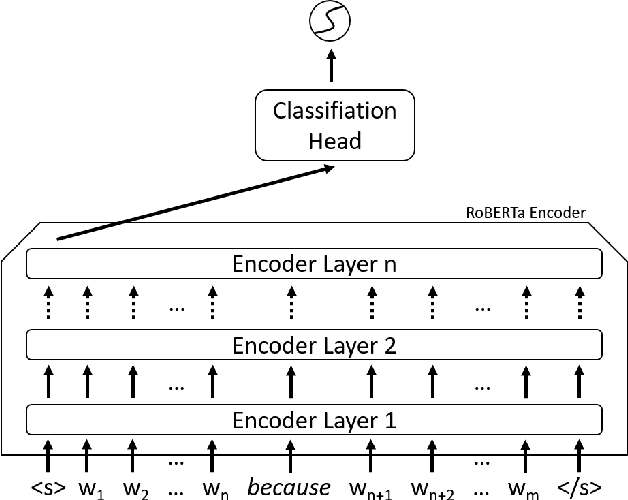
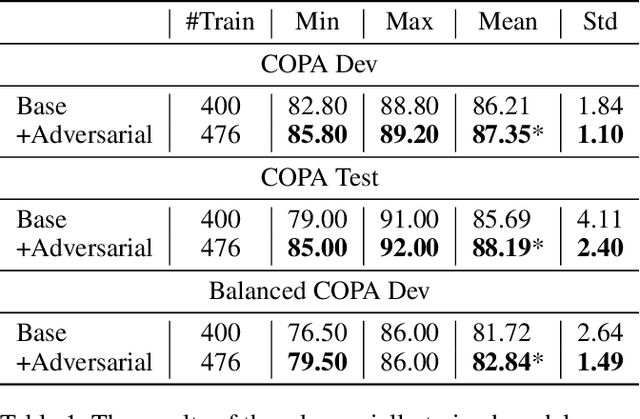
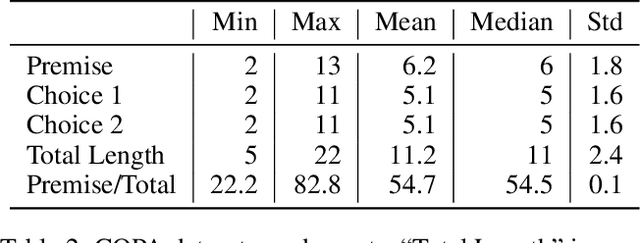
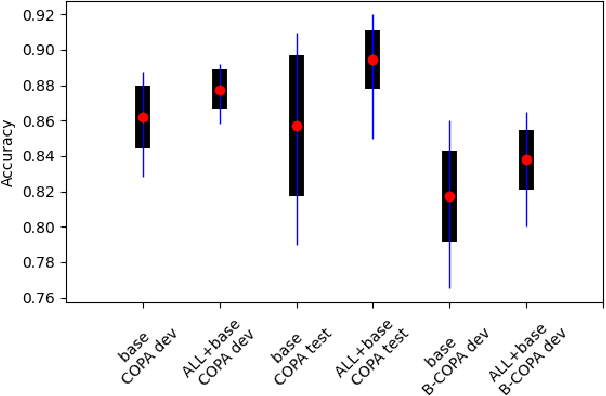
Determining the plausibility of causal relations between clauses is a commonsense reasoning task that requires complex inference ability. The general approach to this task is to train a large pretrained language model on a specific dataset. However, the available training data for the task is often scarce, which leads to instability of model training or reliance on the shallow features of the dataset. This paper presents a number of techniques for making models more robust in the domain of causal reasoning. Firstly, we perform adversarial training by generating perturbed inputs through synonym substitution. Secondly, based on a linguistic theory of discourse connectives, we perform data augmentation using a discourse parser for detecting causally linked clauses in large text, and a generative language model for generating distractors. Both methods boost model performance on the Choice of Plausible Alternatives (COPA) dataset, as well as on a Balanced COPA dataset, which is a modified version of the original data that has been developed to avoid superficial cues, leading to a more challenging benchmark. We show a statistically significant improvement in performance and robustness on both datasets, even with only a small number of additionally generated data points.
Improving End-to-End Speech-to-Intent Classification with Reptile
Aug 05, 2020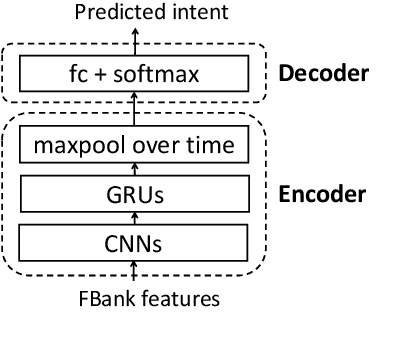
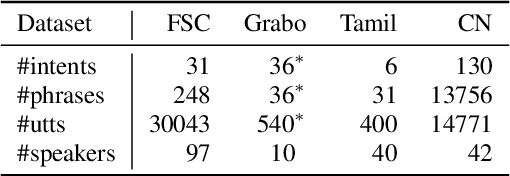
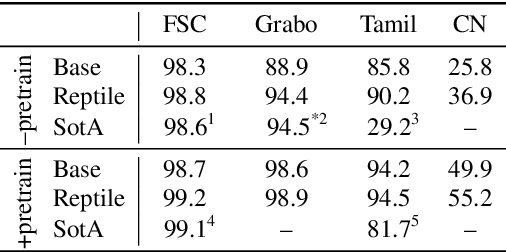
End-to-end spoken language understanding (SLU) systems have many advantages over conventional pipeline systems, but collecting in-domain speech data to train an end-to-end system is costly and time consuming. One question arises from this: how to train an end-to-end SLU with limited amounts of data? Many researchers have explored approaches that make use of other related data resources, typically by pre-training parts of the model on high-resource speech recognition. In this paper, we suggest improving the generalization performance of SLU models with a non-standard learning algorithm, Reptile. Though Reptile was originally proposed for model-agnostic meta learning, we argue that it can also be used to directly learn a target task and result in better generalization than conventional gradient descent. In this work, we employ Reptile to the task of end-to-end spoken intent classification. Experiments on four datasets of different languages and domains show improvement of intent prediction accuracy, both when Reptile is used alone and used in addition to pre-training.
Learning Dialog Policies from Weak Demonstrations
Apr 23, 2020
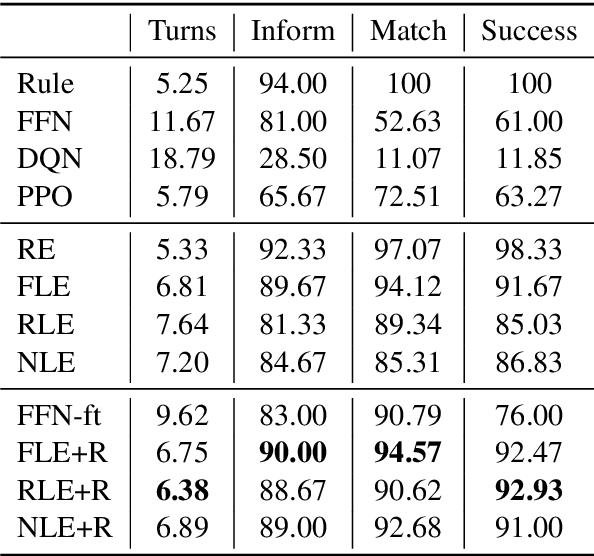
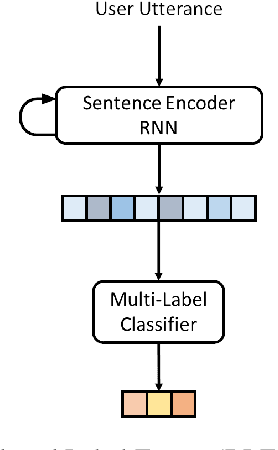
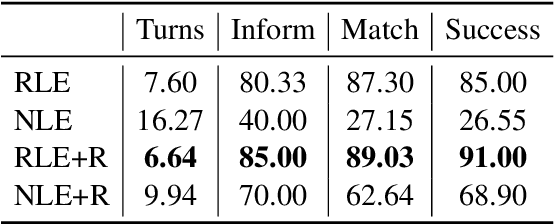
Deep reinforcement learning is a promising approach to training a dialog manager, but current methods struggle with the large state and action spaces of multi-domain dialog systems. Building upon Deep Q-learning from Demonstrations (DQfD), an algorithm that scores highly in difficult Atari games, we leverage dialog data to guide the agent to successfully respond to a user's requests. We make progressively fewer assumptions about the data needed, using labeled, reduced-labeled, and even unlabeled data to train expert demonstrators. We introduce Reinforced Fine-tune Learning, an extension to DQfD, enabling us to overcome the domain gap between the datasets and the environment. Experiments in a challenging multi-domain dialog system framework validate our approaches, and get high success rates even when trained on out-of-domain data.