 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task GRPO: Reliable LLM Reasoning Across Tasks
Feb 05, 2026RL-based post-training with GRPO is widely used to improve large language models on individual reasoning tasks. However, real-world deployment requires reliable performance across diverse tasks. A straightforward multi-task adaptation of GRPO often leads to imbalanced outcomes, with some tasks dominating optimization while others stagnate. Moreover, tasks can vary widely in how frequently prompts yield zero advantages (and thus zero gradients), which further distorts their effective contribution to the optimization signal. To address these issues, we propose a novel Multi-Task GRPO (MT-GRPO) algorithm that (i) dynamically adapts task weights to explicitly optimize worst-task performance and promote balanced progress across tasks, and (ii) introduces a ratio-preserving sampler to ensure task-wise policy gradients reflect the adapted weights. Experiments on both 3-task and 9-task settings show that MT-GRPO consistently outperforms baselines in worst-task accuracy. In particular, MT-GRPO achieves 16-28% and 6% absolute improvement on worst-task performance over standard GRPO and DAPO, respectively, while maintaining competitive average accuracy. Moreover, MT-GRPO requires 50% fewer training steps to reach 50% worst-task accuracy in the 3-task setting, demonstrating substantially improved efficiency in achieving reliable performance across tasks.
Scalable Power Sampling: Unlocking Efficient, Training-Free Reasoning for LLMs via Distribution Sharpening
Jan 29, 2026Reinforcement learning (RL) post-training is a dominant approach for improving the reasoning performance of large language models (LLMs), yet growing evidence suggests that its gains arise primarily from distribution sharpening rather than the acquisition of new capabilities. Recent work has shown that sampling from the power distribution of LLMs using Markov chain Monte Carlo (MCMC) can recover performance comparable to RL post-training without relying on external rewards; however, the high computational cost of MCMC makes such approaches impractical for widespread adoption. In this work, we propose a theoretically grounded alternative that eliminates the need for iterative MCMC. We derive a novel formulation showing that the global power distribution can be approximated by a token-level scaled low-temperature one, where the scaling factor captures future trajectory quality. Leveraging this insight, we introduce a training-free and verifier-free algorithm that sharpens the base model's generative distribution autoregressively. Empirically, we evaluate our method on math, QA, and code tasks across four LLMs, and show that our method matches or surpasses one-shot GRPO without relying on any external rewards, while reducing inference latency by over 10x compared to MCMC-based sampling.
Bourbaki: Self-Generated and Goal-Conditioned MDPs for Theorem Proving
Jul 03, 2025Reasoning remains a challenging task for large language models (LLMs), especially within the logically constrained environment of automated theorem proving (ATP), due to sparse rewards and the vast scale of proofs. These challenges are amplified in benchmarks like PutnamBench, which contains university-level problems requiring complex, multi-step reasoning. To address this, we introduce self-generated goal-conditioned MDPs (sG-MDPs), a new framework in which agents generate and pursue their subgoals based on the evolving proof state. Given this more structured generation of goals, the resulting problem becomes more amenable to search. We then apply Monte Carlo Tree Search (MCTS)-like algorithms to solve the sG-MDP, instantiating our approach in Bourbaki (7B), a modular system that can ensemble multiple 7B LLMs for subgoal generation and tactic synthesis. On PutnamBench, Bourbaki (7B) solves 26 problems, achieving new state-of-the-art results with models at this scale.
Almost Surely Safe Alignment of Large Language Models at Inference-Time
Feb 03, 2025Even highly capable large language models (LLMs) can produce biased or unsafe responses, and alignment techniques, such as RLHF, aimed at mitigating this issue, are expensive and prone to overfitting as they retrain the LLM. This paper introduces a novel inference-time alignment approach that ensures LLMs generate safe responses almost surely, i.e., with a probability approaching one. We achieve this by framing the safe generation of inference-time responses as a constrained Markov decision process within the LLM's latent space. Crucially, we augment a safety state that tracks the evolution of safety constraints and enables us to demonstrate formal safety guarantees upon solving the MDP in the latent space. Building on this foundation, we propose InferenceGuard, a practical implementation that safely aligns LLMs without modifying the model weights. Empirically, we demonstrate InferenceGuard effectively balances safety and task performance, outperforming existing inference-time alignment methods in generating safe and aligned responses.
Efficient Reinforcement Learning with Large Language Model Priors
Oct 10, 2024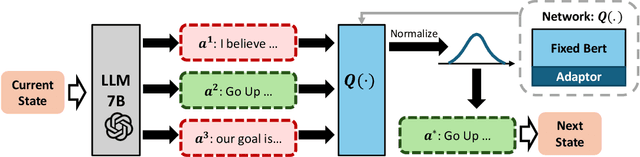
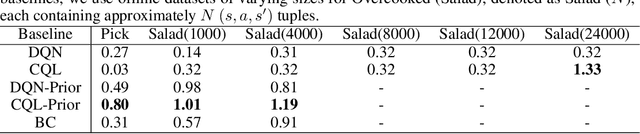
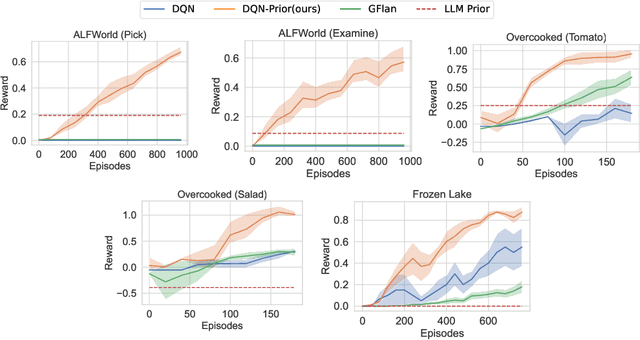
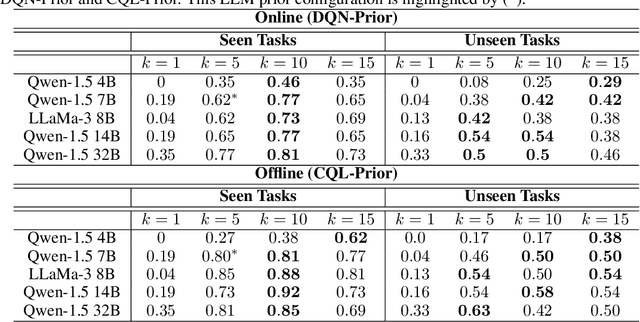
In sequential decision-making (SDM) tasks, methods like reinforcement learning (RL) and heuristic search have made notable advances in specific cases. However, they often require extensive exploration and face challenges in generalizing across diverse environments due to their limited grasp of the underlying decision dynamics. In contrast, large language models (LLMs) have recently emerged as powerful general-purpose tools, due to their capacity to maintain vast amounts of domain-specific knowledge. To harness this rich prior knowledge for efficiently solving complex SDM tasks, we propose treating LLMs as prior action distributions and integrating them into RL frameworks through Bayesian inference methods, making use of variational inference and direct posterior sampling. The proposed approaches facilitate the seamless incorporation of fixed LLM priors into both policy-based and value-based RL frameworks. Our experiments show that incorporating LLM-based action priors significantly reduces exploration and optimization complexity, substantially improving sample efficiency compared to traditional RL techniques, e.g., using LLM priors decreases the number of required samples by over 90% in offline learning scenarios.
Mixture of Attentions For Speculative Decoding
Oct 04, 2024The growth in the number of parameters of Large Language Models (LLMs) has led to a significant surge in computational requirements, making them challenging and costly to deploy. Speculative decoding (SD) leverages smaller models to efficiently propose future tokens, which are then verified by the LLM in parallel. Small models that utilise activations from the LLM currently achieve the fastest decoding speeds. However, we identify several limitations of SD models including the lack of on-policyness during training and partial observability. To address these shortcomings, we propose a more grounded architecture for small models by introducing a Mixture of Attentions for SD. Our novel architecture can be applied in two scenarios: a conventional single device deployment and a novel client-server deployment where the small model is hosted on a consumer device and the LLM on a server. In a single-device scenario, we demonstrate state-of-the-art speedups improving EAGLE-2 by 9.5% and its acceptance length by 25%. In a client-server setting, our experiments demonstrate: 1) state-of-the-art latencies with minimal calls to the server for different network conditions, and 2) in the event of a complete disconnection, our approach can maintain higher accuracy compared to other SD methods and demonstrates advantages over API calls to LLMs, which would otherwise be unable to continue the generation process.
Group Robust Preference Optimization in Reward-free RLHF
May 30, 2024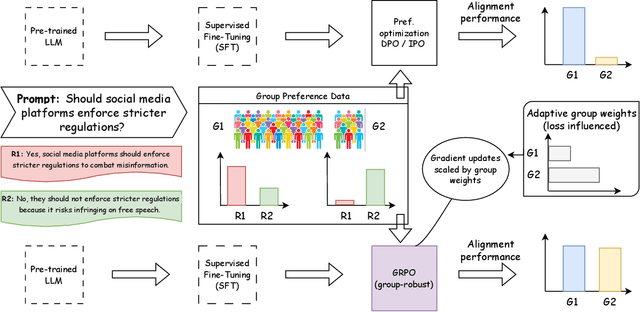
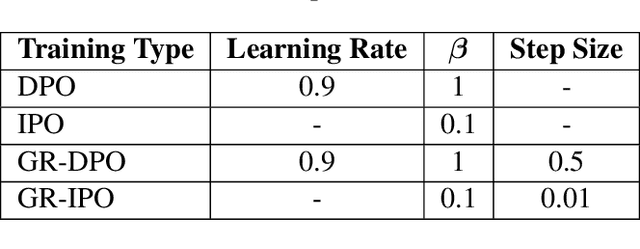
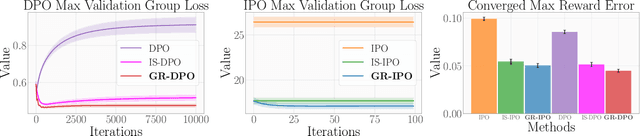

Adapting large language models (LLMs) for specific tasks usually involves fine-tuning through reinforcement learning with human feedback (RLHF) on preference data. While these data often come from diverse labelers' groups (e.g., different demographics, ethnicities, company teams, etc.), traditional RLHF approaches adopt a "one-size-fits-all" approach, i.e., they indiscriminately assume and optimize a single preference model, thus not being robust to unique characteristics and needs of the various groups. To address this limitation, we propose a novel Group Robust Preference Optimization (GRPO) method to align LLMs to individual groups' preferences robustly. Our approach builds upon reward-free direct preference optimization methods, but unlike previous approaches, it seeks a robust policy which maximizes the worst-case group performance. To achieve this, GRPO adaptively and sequentially weights the importance of different groups, prioritizing groups with worse cumulative loss. We theoretically study the feasibility of GRPO and analyze its convergence for the log-linear policy class. By fine-tuning LLMs with GRPO using diverse group-based global opinion data, we significantly improved performance for the worst-performing groups, reduced loss imbalances across groups, and improved probability accuracies compared to non-robust baselines.
Framework and Benchmarks for Combinatorial and Mixed-variable Bayesian Optimization
Jun 16, 2023This paper introduces a modular framework for Mixed-variable and Combinatorial Bayesian Optimization (MCBO) to address the lack of systematic benchmarking and standardized evaluation in the field. Current MCBO papers often introduce non-diverse or non-standard benchmarks to evaluate their methods, impeding the proper assessment of different MCBO primitives and their combinations. Additionally, papers introducing a solution for a single MCBO primitive often omit benchmarking against baselines that utilize the same methods for the remaining primitives. This omission is primarily due to the significant implementation overhead involved, resulting in a lack of controlled assessments and an inability to showcase the merits of a contribution effectively. To overcome these challenges, our proposed framework enables an effortless combination of Bayesian Optimization components, and provides a diverse set of synthetic and real-world benchmarking tasks. Leveraging this flexibility, we implement 47 novel MCBO algorithms and benchmark them against seven existing MCBO solvers and five standard black-box optimization algorithms on ten tasks, conducting over 4000 experiments. Our findings reveal a superior combination of MCBO primitives outperforming existing approaches and illustrate the significance of model fit and the use of a trust region. We make our MCBO library available under the MIT license at \url{https://github.com/huawei-noah/HEBO/tree/master/MCBO}.
End-to-End Meta-Bayesian Optimisation with Transformer Neural Processes
May 25, 2023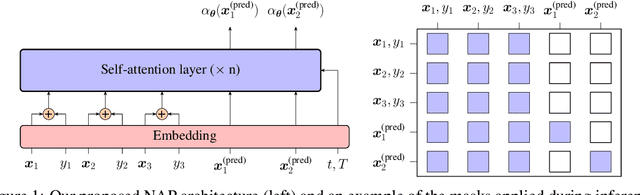
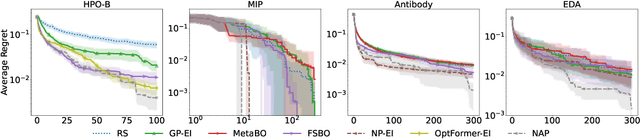
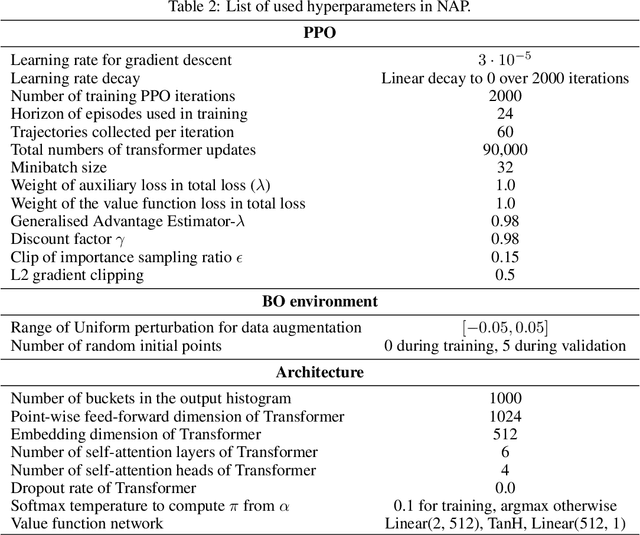
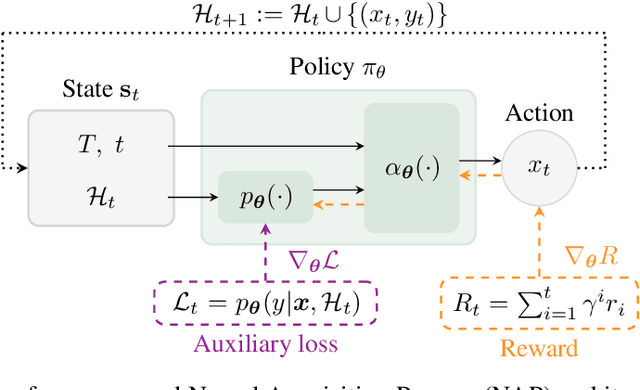
Meta-Bayesian optimisation (meta-BO) aims to improve the sample efficiency of Bayesian optimisation by leveraging data from related tasks. While previous methods successfully meta-learn either a surrogate model or an acquisition function independently, joint training of both components remains an open challenge. This paper proposes the first end-to-end differentiable meta-BO framework that generalises neural processes to learn acquisition functions via transformer architectures. We enable this end-to-end framework with reinforcement learning (RL) to tackle the lack of labelled acquisition data. Early on, we notice that training transformer-based neural processes from scratch with RL is challenging due to insufficient supervision, especially when rewards are sparse. We formalise this claim with a combinatorial analysis showing that the widely used notion of regret as a reward signal exhibits a logarithmic sparsity pattern in trajectory lengths. To tackle this problem, we augment the RL objective with an auxiliary task that guides part of the architecture to learn a valid probabilistic model as an inductive bias. We demonstrate that our method achieves state-of-the-art regret results against various baselines in experiments on standard hyperparameter optimisation tasks and also outperforms others in the real-world problems of mixed-integer programming tuning, antibody design, and logic synthesis for electronic design automation.
Reinforcement Learning for Safe Robot Control using Control Lyapunov Barrier Functions
May 16, 2023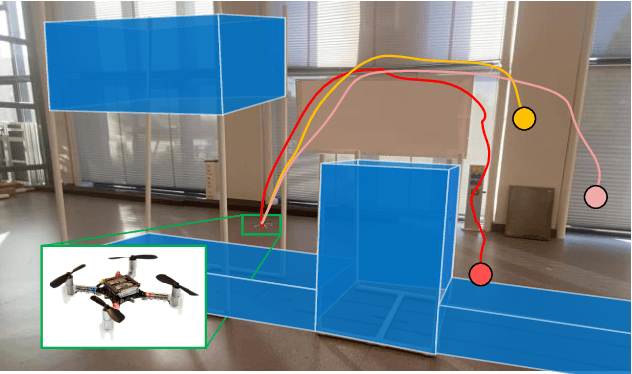

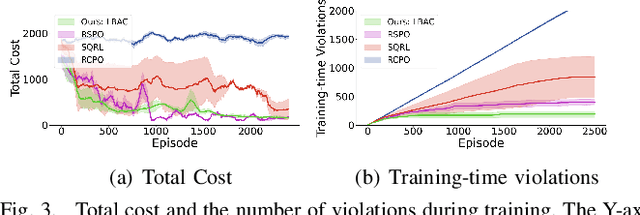
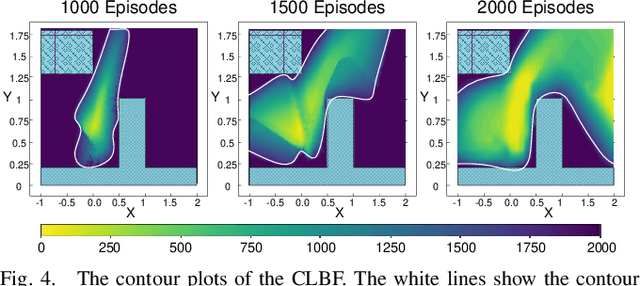
Reinforcement learning (RL) exhibits impressive performance when managing complicated control tasks for robots. However, its wide application to physical robots is limited by the absence of strong safety guarantees. To overcome this challenge, this paper explores the control Lyapunov barrier function (CLBF) to analyze the safety and reachability solely based on data without explicitly employing a dynamic model. We also proposed the Lyapunov barrier actor-critic (LBAC), a model-free RL algorithm, to search for a controller that satisfies the data-based approximation of the safety and reachability conditions. The proposed approach is demonstrated through simulation and real-world robot control experiments, i.e., a 2D quadrotor navigation task. The experimental findings reveal this approach's effectiveness in reachability and safety, surpassing other model-free RL methods.