 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Bayesian Reinforcement Learning for Spacecraft Proximity Maneuvers and Docking
Nov 07, 2023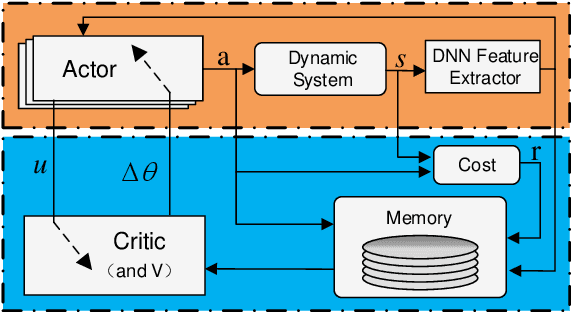

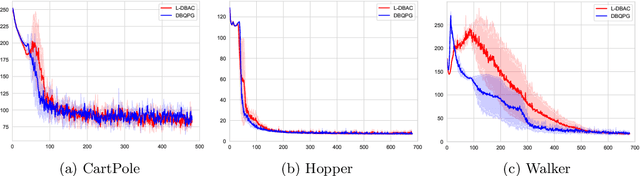
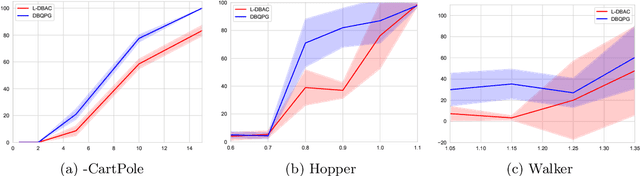
In the pursuit of autonomous spacecraft proximity maneuvers and docking(PMD), we introduce a novel Bayesian actor-critic reinforcement learning algorithm to learn a control policy with the stability guarantee. The PMD task is formulated as a Markov decision process that reflects the relative dynamic model, the docking cone and the cost function. Drawing from the principles of Lyapunov theory, we frame the temporal difference learning as a constrained Gaussian process regression problem. This innovative approach allows the state-value function to be expressed as a Lyapunov function, leveraging the Gaussian process and deep kernel learning. We develop a novel Bayesian quadrature policy optimization procedure to analytically compute the policy gradient while integrating Lyapunov-based stability constraints. This integration is pivotal in satisfying the rigorous safety demands of spaceflight missions. The proposed algorithm has been experimentally evaluated on a spacecraft air-bearing testbed and shows impressive and promising performance.
Reinforcement Learning for Safe Robot Control using Control Lyapunov Barrier Functions
May 16, 2023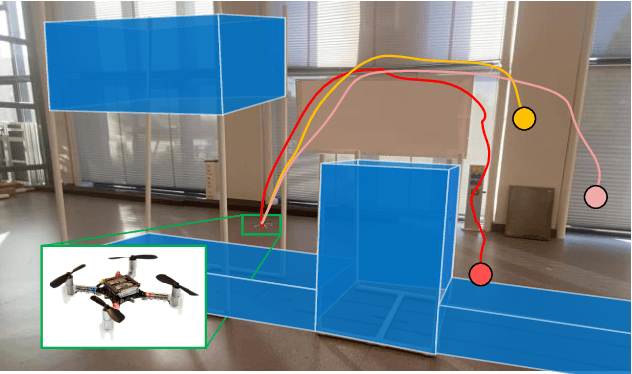

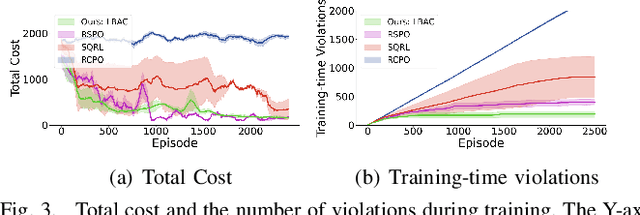
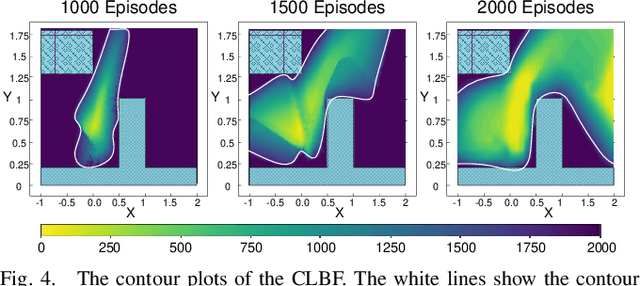
Reinforcement learning (RL) exhibits impressive performance when managing complicated control tasks for robots. However, its wide application to physical robots is limited by the absence of strong safety guarantees. To overcome this challenge, this paper explores the control Lyapunov barrier function (CLBF) to analyze the safety and reachability solely based on data without explicitly employing a dynamic model. We also proposed the Lyapunov barrier actor-critic (LBAC), a model-free RL algorithm, to search for a controller that satisfies the data-based approximation of the safety and reachability conditions. The proposed approach is demonstrated through simulation and real-world robot control experiments, i.e., a 2D quadrotor navigation task. The experimental findings reveal this approach's effectiveness in reachability and safety, surpassing other model-free RL methods.