 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDReSD: Dense Retrieval for Speculative Decoding
Feb 21, 2025



Speculative decoding (SD) accelerates Large Language Model (LLM) generation by using an efficient draft model to propose the next few tokens, which are verified by the LLM in a single forward call, reducing latency while preserving its outputs. We focus on retrieval-based SD where the draft model retrieves the next tokens from a non-parametric datastore. Sparse retrieval (REST), which operates on the surface form of strings, is currently the dominant paradigm due to its simplicity and scalability. However, its effectiveness is limited due to the usage of short contexts and exact string matching. Instead, we introduce Dense Retrieval for Speculative Decoding (DReSD), a novel framework that uses approximate nearest neighbour search with contextualised token embeddings to retrieve the most semantically relevant token sequences for SD. Extensive experiments show that DReSD achieves (on average) 87% higher acceptance rates, 65% longer accepted tokens and 19% faster generation speeds compared to sparse retrieval (REST).
Mixture of Attentions For Speculative Decoding
Oct 04, 2024The growth in the number of parameters of Large Language Models (LLMs) has led to a significant surge in computational requirements, making them challenging and costly to deploy. Speculative decoding (SD) leverages smaller models to efficiently propose future tokens, which are then verified by the LLM in parallel. Small models that utilise activations from the LLM currently achieve the fastest decoding speeds. However, we identify several limitations of SD models including the lack of on-policyness during training and partial observability. To address these shortcomings, we propose a more grounded architecture for small models by introducing a Mixture of Attentions for SD. Our novel architecture can be applied in two scenarios: a conventional single device deployment and a novel client-server deployment where the small model is hosted on a consumer device and the LLM on a server. In a single-device scenario, we demonstrate state-of-the-art speedups improving EAGLE-2 by 9.5% and its acceptance length by 25%. In a client-server setting, our experiments demonstrate: 1) state-of-the-art latencies with minimal calls to the server for different network conditions, and 2) in the event of a complete disconnection, our approach can maintain higher accuracy compared to other SD methods and demonstrates advantages over API calls to LLMs, which would otherwise be unable to continue the generation process.
Code-Optimise: Self-Generated Preference Data for Correctness and Efficiency
Jun 18, 2024Code Language Models have been trained to generate accurate solutions, typically with no regard for runtime. On the other hand, previous works that explored execution optimisation have observed corresponding drops in functional correctness. To that end, we introduce Code-Optimise, a framework that incorporates both correctness (passed, failed) and runtime (quick, slow) as learning signals via self-generated preference data. Our framework is both lightweight and robust as it dynamically selects solutions to reduce overfitting while avoiding a reliance on larger models for learning signals. Code-Optimise achieves significant improvements in pass@k while decreasing the competitive baseline runtimes by an additional 6% for in-domain data and up to 3% for out-of-domain data. As a byproduct, the average length of the generated solutions is reduced by up to 48% on MBPP and 23% on HumanEval, resulting in faster and cheaper inference. The generated data and codebase will be open-sourced at www.open-source.link.
HumanRankEval: Automatic Evaluation of LMs as Conversational Assistants
May 15, 2024



Language models (LMs) as conversational assistants recently became popular tools that help people accomplish a variety of tasks. These typically result from adapting LMs pretrained on general domain text sequences through further instruction-tuning and possibly preference optimisation methods. The evaluation of such LMs would ideally be performed using human judgement, however, this is not scalable. On the other hand, automatic evaluation featuring auxiliary LMs as judges and/or knowledge-based tasks is scalable but struggles with assessing conversational ability and adherence to instructions. To help accelerate the development of LMs as conversational assistants, we propose a novel automatic evaluation task: HumanRankEval (HRE). It consists of a large-scale, diverse and high-quality set of questions, each with several answers authored and scored by humans. To perform evaluation, HRE ranks these answers based on their log-likelihood under the LM's distribution, and subsequently calculates their correlation with the corresponding human rankings. We support HRE's efficacy by investigating how efficiently it separates pretrained and instruction-tuned LMs of various sizes. We show that HRE correlates well with human judgements and is particularly responsive to model changes following instruction-tuning.
A Systematic Study of Performance Disparities in Multilingual Task-Oriented Dialogue Systems
Oct 19, 2023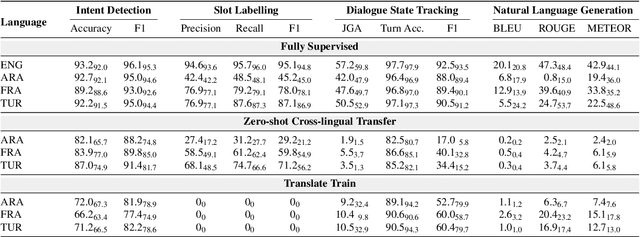
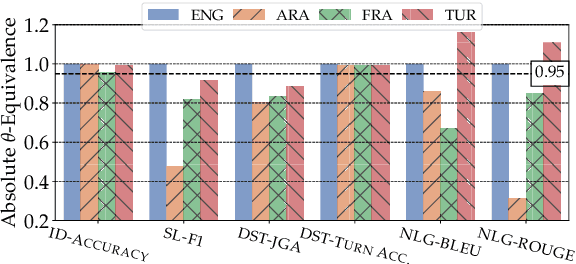
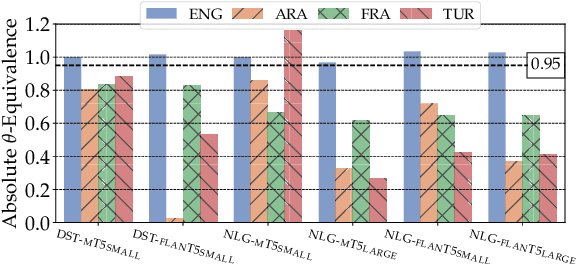
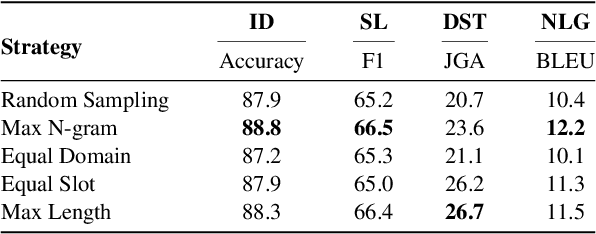
Achieving robust language technologies that can perform well across the world's many languages is a central goal of multilingual NLP. In this work, we take stock of and empirically analyse task performance disparities that exist between multilingual task-oriented dialogue (ToD) systems. We first define new quantitative measures of absolute and relative equivalence in system performance, capturing disparities across languages and within individual languages. Through a series of controlled experiments, we demonstrate that performance disparities depend on a number of factors: the nature of the ToD task at hand, the underlying pretrained language model, the target language, and the amount of ToD annotated data. We empirically prove the existence of the adaptation and intrinsic biases in current ToD systems: e.g., ToD systems trained for Arabic or Turkish using annotated ToD data fully parallel to English ToD data still exhibit diminished ToD task performance. Beyond providing a series of insights into the performance disparities of ToD systems in different languages, our analyses offer practical tips on how to approach ToD data collection and system development for new languages.
Multi3WOZ: A Multilingual, Multi-Domain, Multi-Parallel Dataset for Training and Evaluating Culturally Adapted Task-Oriented Dialog Systems
Jul 26, 2023Creating high-quality annotated data for task-oriented dialog (ToD) is known to be notoriously difficult, and the challenges are amplified when the goal is to create equitable, culturally adapted, and large-scale ToD datasets for multiple languages. Therefore, the current datasets are still very scarce and suffer from limitations such as translation-based non-native dialogs with translation artefacts, small scale, or lack of cultural adaptation, among others. In this work, we first take stock of the current landscape of multilingual ToD datasets, offering a systematic overview of their properties and limitations. Aiming to reduce all the detected limitations, we then introduce Multi3WOZ, a novel multilingual, multi-domain, multi-parallel ToD dataset. It is large-scale and offers culturally adapted dialogs in 4 languages to enable training and evaluation of multilingual and cross-lingual ToD systems. We describe a complex bottom-up data collection process that yielded the final dataset, and offer the first sets of baseline scores across different ToD-related tasks for future reference, also highlighting its challenging nature.
PanGu-Coder: Program Synthesis with Function-Level Language Modeling
Jul 22, 2022
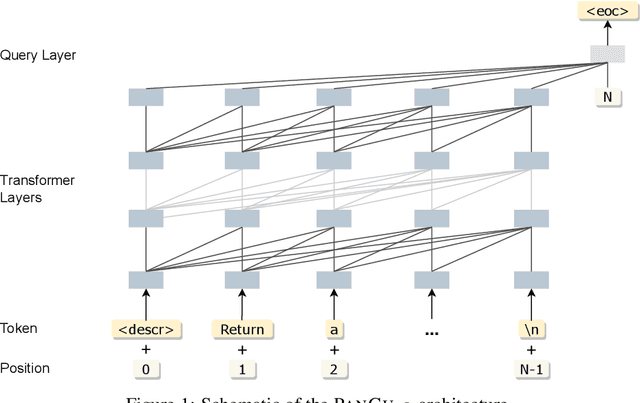
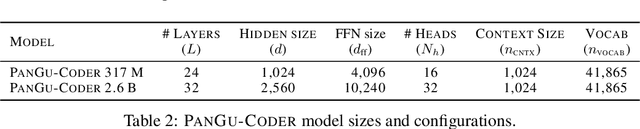
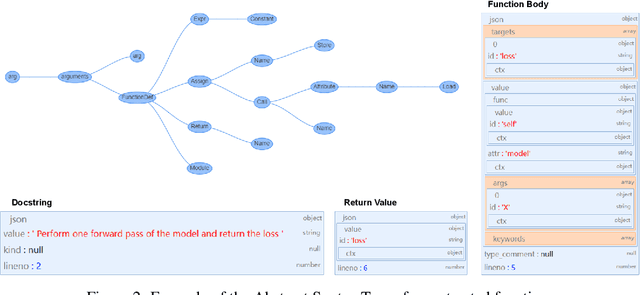
We present PanGu-Coder, a pretrained decoder-only language model adopting the PanGu-Alpha architecture for text-to-code generation, i.e. the synthesis of programming language solutions given a natural language problem description. We train PanGu-Coder using a two-stage strategy: the first stage employs Causal Language Modelling (CLM) to pre-train on raw programming language data, while the second stage uses a combination of Causal Language Modelling and Masked Language Modelling (MLM) training objectives that focus on the downstream task of text-to-code generation and train on loosely curated pairs of natural language program definitions and code functions. Finally, we discuss PanGu-Coder-FT, which is fine-tuned on a combination of competitive programming problems and code with continuous integration tests. We evaluate PanGu-Coder with a focus on whether it generates functionally correct programs and demonstrate that it achieves equivalent or better performance than similarly sized models, such as CodeX, while attending a smaller context window and training on less data.
CrossAligner & Co: Zero-Shot Transfer Methods for Task-Oriented Cross-lingual Natural Language Understanding
Mar 18, 2022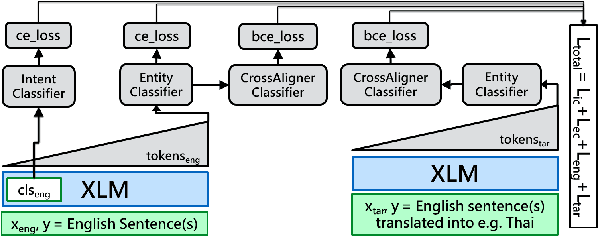
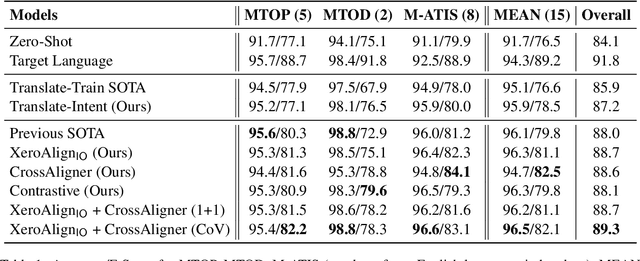
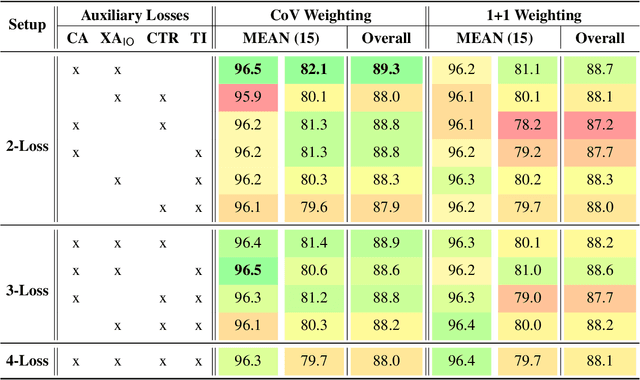
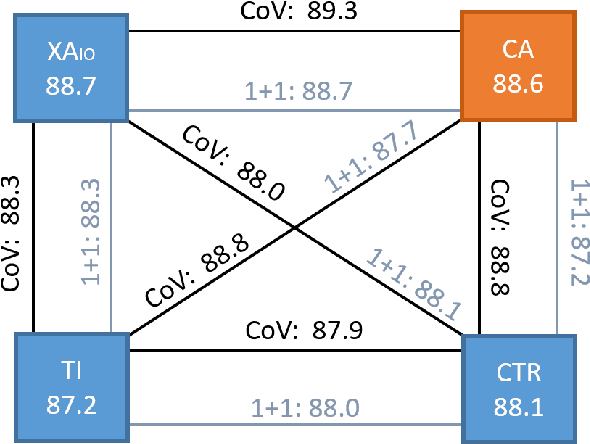
Task-oriented personal assistants enable people to interact with a host of devices and services using natural language. One of the challenges of making neural dialogue systems available to more users is the lack of training data for all but a few languages. Zero-shot methods try to solve this issue by acquiring task knowledge in a high-resource language such as English with the aim of transferring it to the low-resource language(s). To this end, we introduce CrossAligner, the principal method of a variety of effective approaches for zero-shot cross-lingual transfer based on learning alignment from unlabelled parallel data. We present a quantitative analysis of individual methods as well as their weighted combinations, several of which exceed state-of-the-art (SOTA) scores as evaluated across nine languages, fifteen test sets and three benchmark multilingual datasets. A detailed qualitative error analysis of the best methods shows that our fine-tuned language models can zero-shot transfer the task knowledge better than anticipated.
Enhancing Transformers with Gradient Boosted Decision Trees for NLI Fine-Tuning
May 08, 2021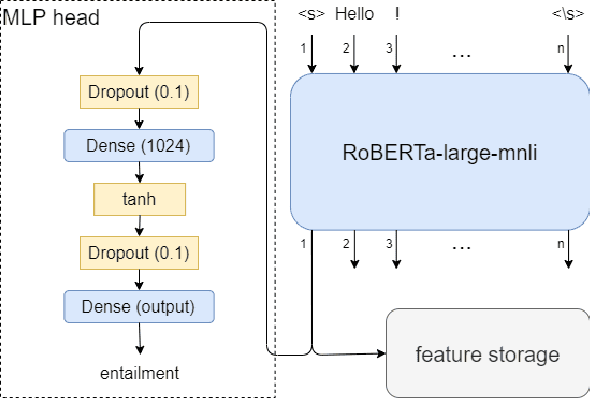
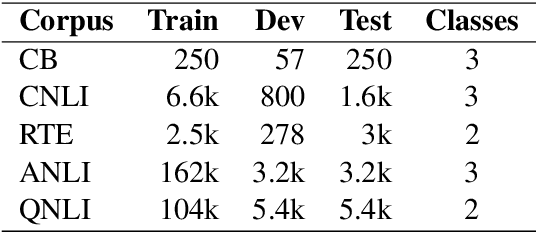


Transfer learning has become the dominant paradigm for many natural language processing tasks. In addition to models being pretrained on large datasets, they can be further trained on intermediate (supervised) tasks that are similar to the target task. For small Natural Language Inference (NLI) datasets, language modelling is typically followed by pretraining on a large (labelled) NLI dataset before fine-tuning with each NLI subtask. In this work, we explore Gradient Boosted Decision Trees (GBDTs) as an alternative to the commonly used Multi-Layer Perceptron (MLP) classification head. GBDTs have desirable properties such as good performance on dense, numerical features and are effective where the ratio of the number of samples w.r.t the number of features is low. We then introduce FreeGBDT, a method of fitting a GBDT head on the features computed during fine-tuning to increase performance without additional computation by the neural network. We demonstrate the effectiveness of our method on several NLI datasets using a strong baseline model (RoBERTa-large with MNLI pretraining). The FreeGBDT shows a consistent improvement over the MLP classification head.
XeroAlign: Zero-Shot Cross-lingual Transformer Alignment
May 06, 2021

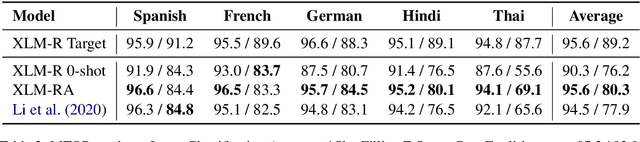

The introduction of pretrained cross-lingual language models brought decisive improvements to multilingual NLP tasks. However, the lack of labelled task data necessitates a variety of methods aiming to close the gap to high-resource languages. Zero-shot methods in particular, often use translated task data as a training signal to bridge the performance gap between the source and target language(s). We introduce XeroAlign, a simple method for task-specific alignment of cross-lingual pretrained transformers such as XLM-R. XeroAlign uses translated task data to encourage the model to generate similar sentence embeddings for different languages. The XeroAligned XLM-R, called XLM-RA, shows strong improvements over the baseline models to achieve state-of-the-art zero-shot results on three multilingual natural language understanding tasks. XLM-RA's text classification accuracy exceeds that of XLM-R trained with labelled data and performs on par with state-of-the-art models on a cross-lingual adversarial paraphrasing task.