 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Description-Augmented Dataless Intent Classification
Jul 25, 2024In this work, we introduce several schemes to leverage description-augmented embedding similarity for dataless intent classification using current state-of-the-art (SOTA) text embedding models. We report results of our methods on four commonly used intent classification datasets and compare against previous works of a similar nature. Our work shows promising results for dataless classification scaling to a large number of unseen intents. We show competitive results and significant improvements (+6.12\% Avg.) over strong zero-shot baselines, all without training on labelled or task-specific data. Furthermore, we provide qualitative error analysis of the shortfalls of this methodology to help guide future research in this area.
A Multilingual Virtual Guide for Self-Attachment Technique
Oct 25, 2023In this work, we propose a computational framework that leverages existing out-of-language data to create a conversational agent for the delivery of Self-Attachment Technique (SAT) in Mandarin. Our framework does not require large-scale human translations, yet it achieves a comparable performance whilst also maintaining safety and reliability. We propose two different methods of augmenting available response data through empathetic rewriting. We evaluate our chatbot against a previous, English-only SAT chatbot through non-clinical human trials (N=42), each lasting five days, and quantitatively show that we are able to attain a comparable level of performance to the English SAT chatbot. We provide qualitative analysis on the limitations of our study and suggestions with the aim of guiding future improvements.
From Words and Exercises to Wellness: Farsi Chatbot for Self-Attachment Technique
Oct 13, 2023In the wake of the post-pandemic era, marked by social isolation and surging rates of depression and anxiety, conversational agents based on digital psychotherapy can play an influential role compared to traditional therapy sessions. In this work, we develop a voice-capable chatbot in Farsi to guide users through Self-Attachment (SAT), a novel, self-administered, holistic psychological technique based on attachment theory. Our chatbot uses a dynamic array of rule-based and classification-based modules to comprehend user input throughout the conversation and navigates a dialogue flowchart accordingly, recommending appropriate SAT exercises that depend on the user's emotional and mental state. In particular, we collect a dataset of over 6,000 utterances and develop a novel sentiment-analysis module that classifies user sentiment into 12 classes, with accuracy above 92%. To keep the conversation novel and engaging, the chatbot's responses are retrieved from a large dataset of utterances created with the aid of Farsi GPT-2 and a reinforcement learning approach, thus requiring minimal human annotation. Our chatbot also offers a question-answering module, called SAT Teacher, to answer users' questions about the principles of Self-Attachment. Finally, we design a cross-platform application as the bot's user interface. We evaluate our platform in a ten-day human study with N=52 volunteers from the non-clinical population, who have had over 2,000 dialogues in total with the chatbot. The results indicate that the platform was engaging to most users (75%), 72% felt better after the interactions, and 74% were satisfied with the SAT Teacher's performance.
CrossAligner & Co: Zero-Shot Transfer Methods for Task-Oriented Cross-lingual Natural Language Understanding
Mar 18, 2022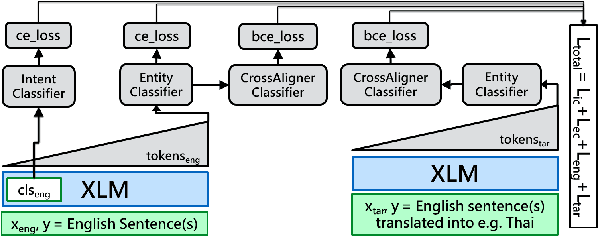
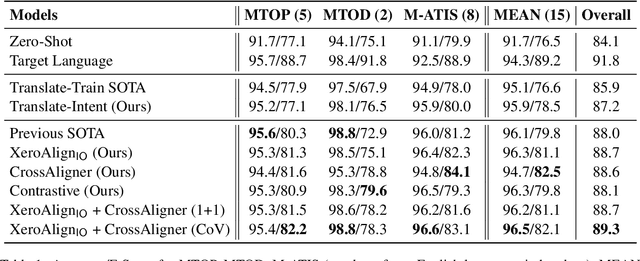
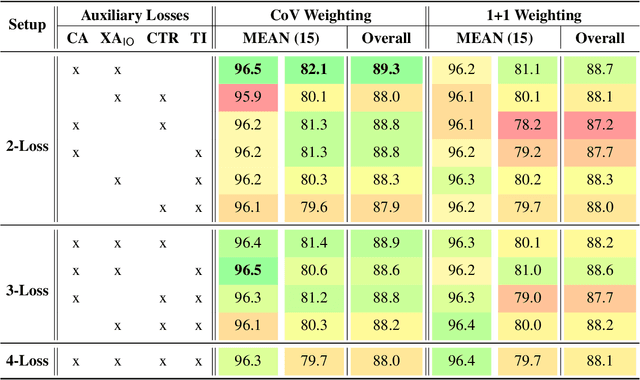
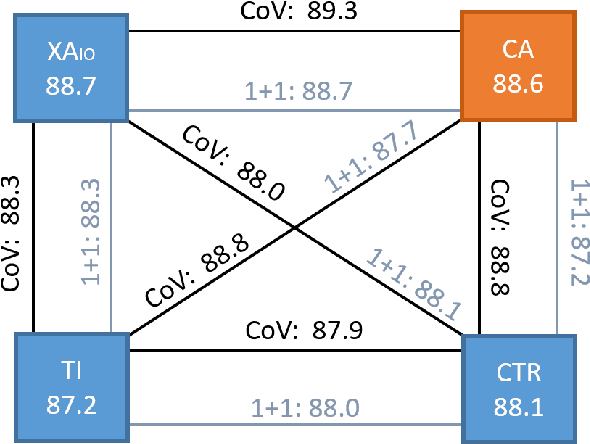
Task-oriented personal assistants enable people to interact with a host of devices and services using natural language. One of the challenges of making neural dialogue systems available to more users is the lack of training data for all but a few languages. Zero-shot methods try to solve this issue by acquiring task knowledge in a high-resource language such as English with the aim of transferring it to the low-resource language(s). To this end, we introduce CrossAligner, the principal method of a variety of effective approaches for zero-shot cross-lingual transfer based on learning alignment from unlabelled parallel data. We present a quantitative analysis of individual methods as well as their weighted combinations, several of which exceed state-of-the-art (SOTA) scores as evaluated across nine languages, fifteen test sets and three benchmark multilingual datasets. A detailed qualitative error analysis of the best methods shows that our fine-tuned language models can zero-shot transfer the task knowledge better than anticipated.