 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multilingual Virtual Guide for Self-Attachment Technique
Oct 25, 2023In this work, we propose a computational framework that leverages existing out-of-language data to create a conversational agent for the delivery of Self-Attachment Technique (SAT) in Mandarin. Our framework does not require large-scale human translations, yet it achieves a comparable performance whilst also maintaining safety and reliability. We propose two different methods of augmenting available response data through empathetic rewriting. We evaluate our chatbot against a previous, English-only SAT chatbot through non-clinical human trials (N=42), each lasting five days, and quantitatively show that we are able to attain a comparable level of performance to the English SAT chatbot. We provide qualitative analysis on the limitations of our study and suggestions with the aim of guiding future improvements.
CO-STAR: Conceptualisation of Stereotypes for Analysis and Reasoning
Dec 01, 2021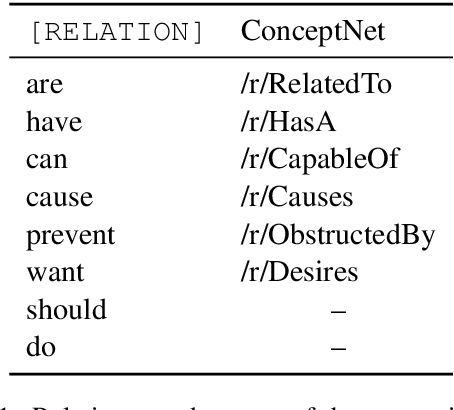


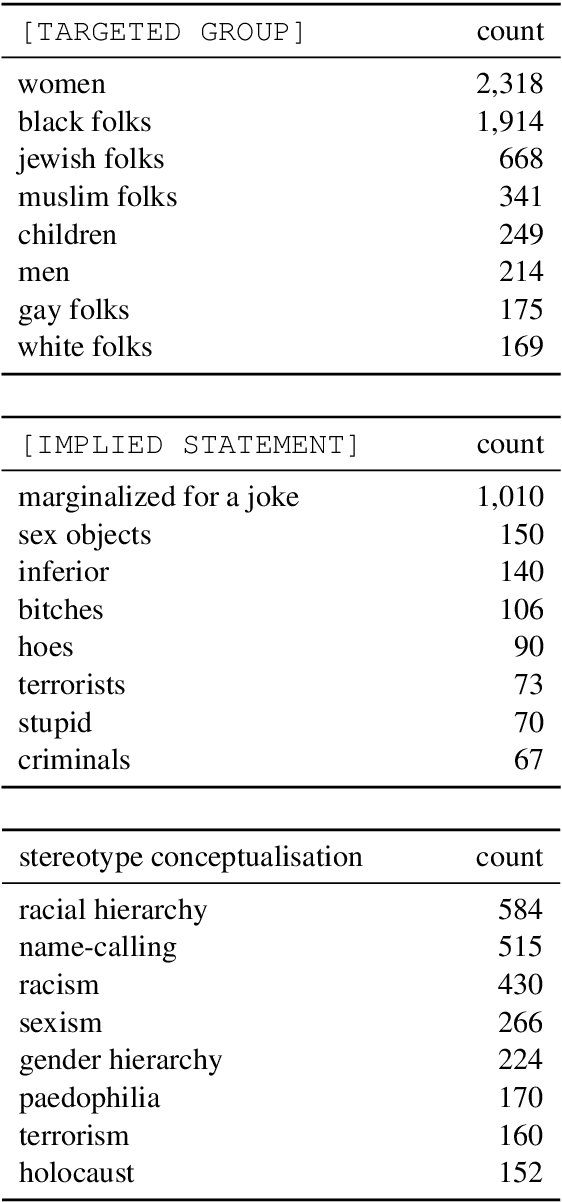
Warning: this paper contains material which may be offensive or upsetting. While much of recent work has focused on the detection of hate speech and overtly offensive content, very little research has explored the more subtle but equally harmful language in the form of implied stereotypes. This is a challenging domain, made even more so by the fact that humans often struggle to understand and reason about stereotypes. We build on existing literature and present CO-STAR (COnceptualisation of STereotypes for Analysis and Reasoning), a novel framework which encodes the underlying concepts of implied stereotypes. We also introduce the CO-STAR training data set, which contains just over 12K structured annotations of implied stereotypes and stereotype conceptualisations, and achieve state-of-the-art results after training and manual evaluation. The CO-STAR models are, however, limited in their ability to understand more complex and subtly worded stereotypes, and our research motivates future work in developing models with more sophisticated methods for encoding common-sense knowledge.