 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe 2025 PNPL Competition: Speech Detection and Phoneme Classification in the LibriBrain Dataset
Jun 11, 2025The advance of speech decoding from non-invasive brain data holds the potential for profound societal impact. Among its most promising applications is the restoration of communication to paralysed individuals affected by speech deficits such as dysarthria, without the need for high-risk surgical interventions. The ultimate aim of the 2025 PNPL competition is to produce the conditions for an "ImageNet moment" or breakthrough in non-invasive neural decoding, by harnessing the collective power of the machine learning community. To facilitate this vision we present the largest within-subject MEG dataset recorded to date (LibriBrain) together with a user-friendly Python library (pnpl) for easy data access and integration with deep learning frameworks. For the competition we define two foundational tasks (i.e. Speech Detection and Phoneme Classification from brain data), complete with standardised data splits and evaluation metrics, illustrative benchmark models, online tutorial code, a community discussion board, and public leaderboard for submissions. To promote accessibility and participation the competition features a Standard track that emphasises algorithmic innovation, as well as an Extended track that is expected to reward larger-scale computing, accelerating progress toward a non-invasive brain-computer interface for speech.
Language Models as Zero-Shot Trajectory Generators
Oct 17, 2023Large Language Models (LLMs) have recently shown promise as high-level planners for robots when given access to a selection of low-level skills. However, it is often assumed that LLMs do not possess sufficient knowledge to be used for the low-level trajectories themselves. In this work, we address this assumption thoroughly, and investigate if an LLM (GPT-4) can directly predict a dense sequence of end-effector poses for manipulation skills, when given access to only object detection and segmentation vision models. We study how well a single task-agnostic prompt, without any in-context examples, motion primitives, or external trajectory optimisers, can perform across 26 real-world language-based tasks, such as "open the bottle cap" and "wipe the plate with the sponge", and we investigate which design choices in this prompt are the most effective. Our conclusions raise the assumed limit of LLMs for robotics, and we reveal for the first time that LLMs do indeed possess an understanding of low-level robot control sufficient for a range of common tasks, and that they can additionally detect failures and then re-plan trajectories accordingly. Videos, code, and prompts are available at: https://www.robot-learning.uk/language-models-trajectory-generators.
CO-STAR: Conceptualisation of Stereotypes for Analysis and Reasoning
Dec 01, 2021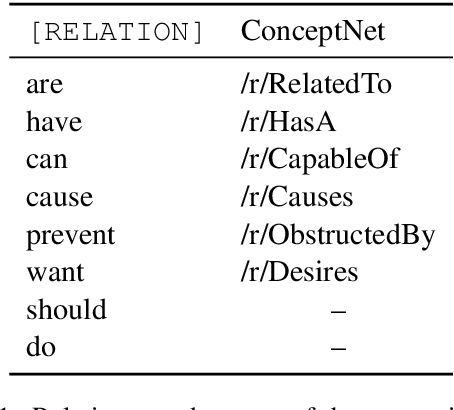


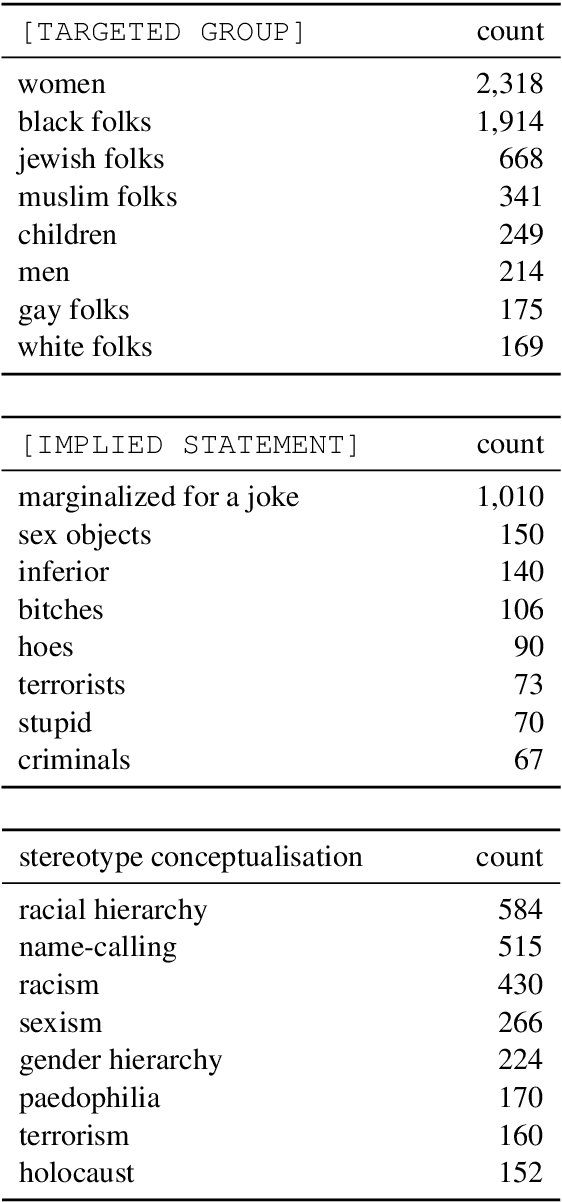
Warning: this paper contains material which may be offensive or upsetting. While much of recent work has focused on the detection of hate speech and overtly offensive content, very little research has explored the more subtle but equally harmful language in the form of implied stereotypes. This is a challenging domain, made even more so by the fact that humans often struggle to understand and reason about stereotypes. We build on existing literature and present CO-STAR (COnceptualisation of STereotypes for Analysis and Reasoning), a novel framework which encodes the underlying concepts of implied stereotypes. We also introduce the CO-STAR training data set, which contains just over 12K structured annotations of implied stereotypes and stereotype conceptualisations, and achieve state-of-the-art results after training and manual evaluation. The CO-STAR models are, however, limited in their ability to understand more complex and subtly worded stereotypes, and our research motivates future work in developing models with more sophisticated methods for encoding common-sense knowledge.