 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe 2025 PNPL Competition: Speech Detection and Phoneme Classification in the LibriBrain Dataset
Jun 11, 2025The advance of speech decoding from non-invasive brain data holds the potential for profound societal impact. Among its most promising applications is the restoration of communication to paralysed individuals affected by speech deficits such as dysarthria, without the need for high-risk surgical interventions. The ultimate aim of the 2025 PNPL competition is to produce the conditions for an "ImageNet moment" or breakthrough in non-invasive neural decoding, by harnessing the collective power of the machine learning community. To facilitate this vision we present the largest within-subject MEG dataset recorded to date (LibriBrain) together with a user-friendly Python library (pnpl) for easy data access and integration with deep learning frameworks. For the competition we define two foundational tasks (i.e. Speech Detection and Phoneme Classification from brain data), complete with standardised data splits and evaluation metrics, illustrative benchmark models, online tutorial code, a community discussion board, and public leaderboard for submissions. To promote accessibility and participation the competition features a Standard track that emphasises algorithmic innovation, as well as an Extended track that is expected to reward larger-scale computing, accelerating progress toward a non-invasive brain-computer interface for speech.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
The Brain's Bitter Lesson: Scaling Speech Decoding With Self-Supervised Learning
Jun 06, 2024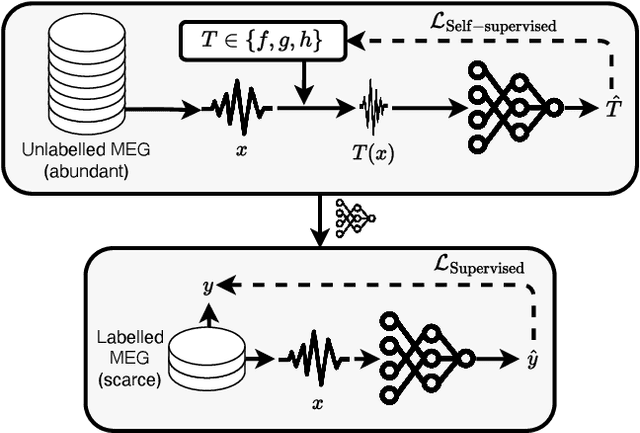
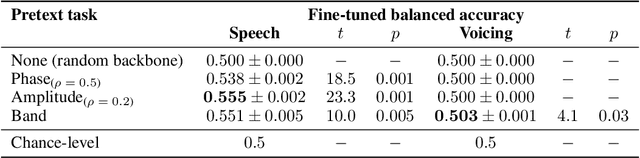
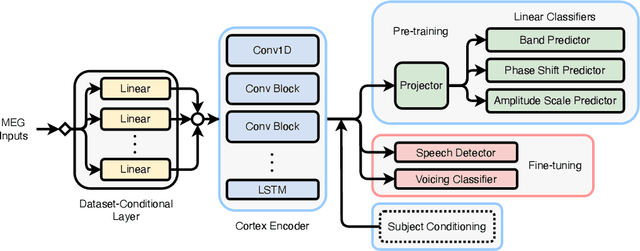
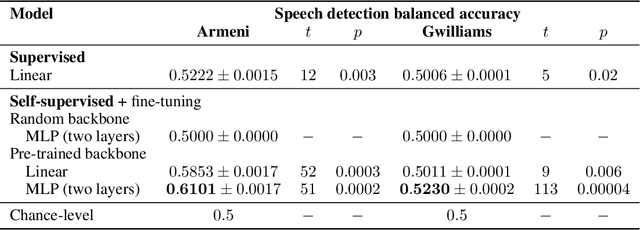
The past few years have produced a series of spectacular advances in the decoding of speech from brain activity. The engine of these advances has been the acquisition of labelled data, with increasingly large datasets acquired from single subjects. However, participants exhibit anatomical and other individual differences, and datasets use varied scanners and task designs. As a result, prior work has struggled to leverage data from multiple subjects, multiple datasets, multiple tasks, and unlabelled datasets. In turn, the field has not benefited from the rapidly growing number of open neural data repositories to exploit large-scale data and deep learning. To address this, we develop an initial set of neuroscience-inspired self-supervised objectives, together with a neural architecture, for representation learning from heterogeneous and unlabelled neural recordings. Experimental results show that representations learned with these objectives generalise across subjects, datasets, and tasks, and are also learned faster than using only labelled data. In addition, we set new benchmarks for two foundational speech decoding tasks. Taken together, these methods now unlock the potential for training speech decoding models with orders of magnitude more existing data.
More than Words: In-the-Wild Visually-Driven Prosody for Text-to-Speech
Nov 19, 2021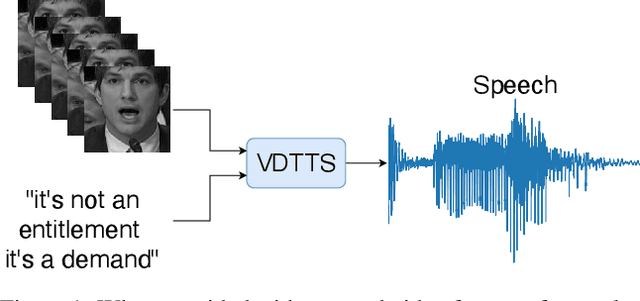
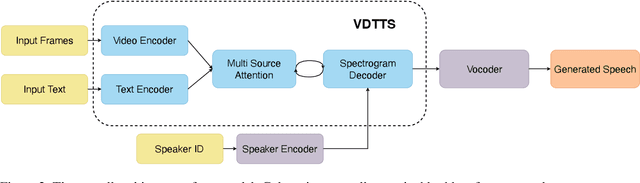
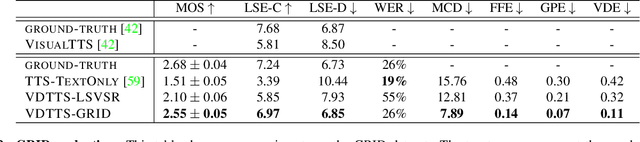
In this paper we present VDTTS, a Visually-Driven Text-to-Speech model. Motivated by dubbing, VDTTS takes advantage of video frames as an additional input alongside text, and generates speech that matches the video signal. We demonstrate how this allows VDTTS to, unlike plain TTS models, generate speech that not only has prosodic variations like natural pauses and pitch, but is also synchronized to the input video. Experimentally, we show our model produces well synchronized outputs, approaching the video-speech synchronization quality of the ground-truth, on several challenging benchmarks including "in-the-wild" content from VoxCeleb2. We encourage the reader to view the demo videos demonstrating video-speech synchronization, robustness to speaker ID swapping, and prosody.
Interactive decoding of words from visual speech recognition models
Jul 01, 2021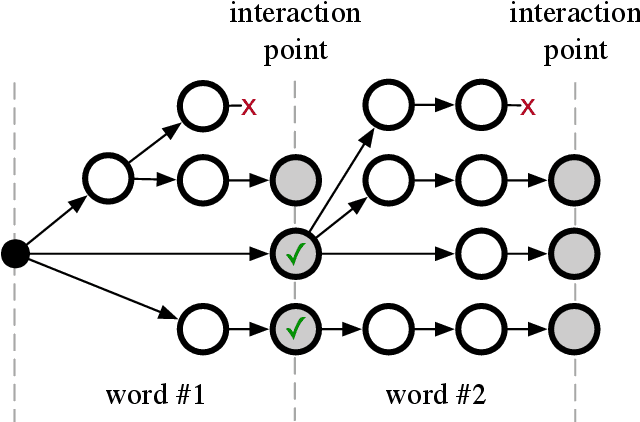

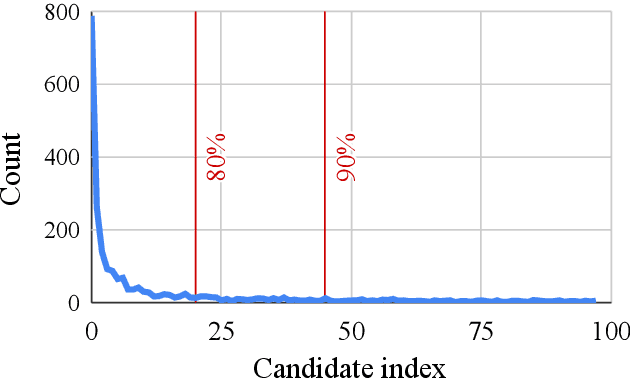

This work describes an interactive decoding method to improve the performance of visual speech recognition systems using user input to compensate for the inherent ambiguity of the task. Unlike most phoneme-to-word decoding pipelines, which produce phonemes and feed these through a finite state transducer, our method instead expands words in lockstep, facilitating the insertion of interaction points at each word position. Interaction points enable us to solicit input during decoding, allowing users to interactively direct the decoding process. We simulate the behavior of user input using an oracle to give an automated evaluation, and show promise for the use of this method for text input.
Large-scale multilingual audio visual dubbing
Nov 06, 2020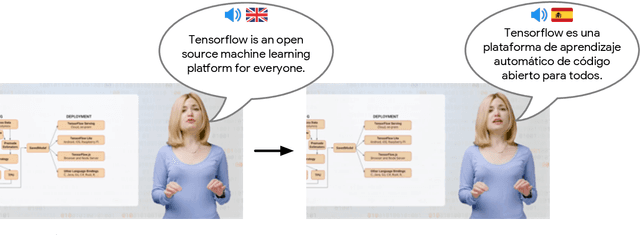
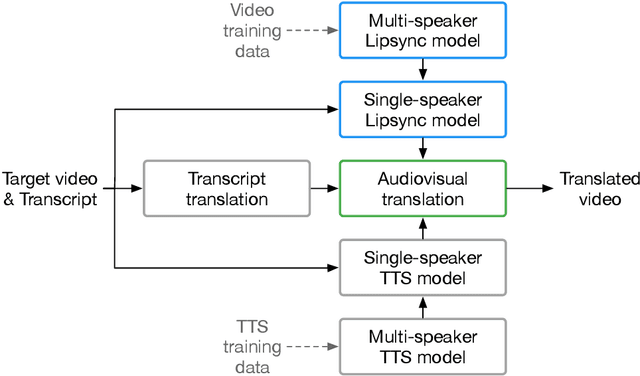
We describe a system for large-scale audiovisual translation and dubbing, which translates videos from one language to another. The source language's speech content is transcribed to text, translated, and automatically synthesized into target language speech using the original speaker's voice. The visual content is translated by synthesizing lip movements for the speaker to match the translated audio, creating a seamless audiovisual experience in the target language. The audio and visual translation subsystems each contain a large-scale generic synthesis model trained on thousands of hours of data in the corresponding domain. These generic models are fine-tuned to a specific speaker before translation, either using an auxiliary corpus of data from the target speaker, or using the video to be translated itself as the input to the fine-tuning process. This report gives an architectural overview of the full system, as well as an in-depth discussion of the video dubbing component. The role of the audio and text components in relation to the full system is outlined, but their design is not discussed in detail. Translated and dubbed demo videos generated using our system can be viewed at https://www.youtube.com/playlist?list=PLSi232j2ZA6_1Exhof5vndzyfbxAhhEs5
Recurrent Neural Network Transducer for Audio-Visual Speech Recognition
Nov 08, 2019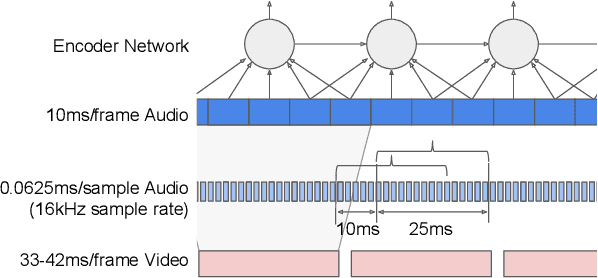
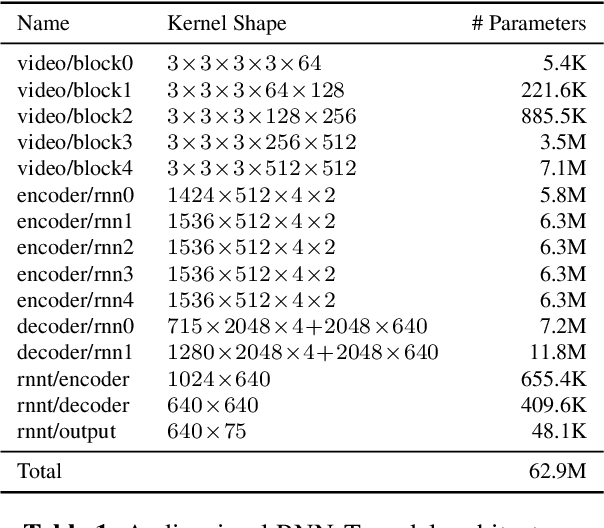
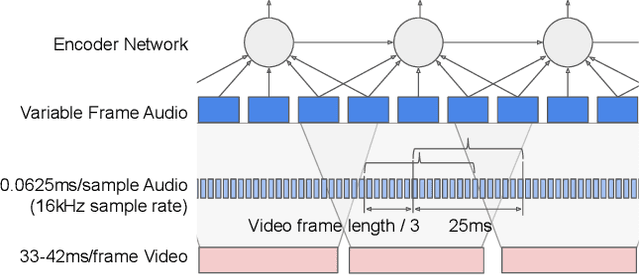

This work presents a large-scale audio-visual speech recognition system based on a recurrent neural network transducer (RNN-T) architecture. To support the development of such a system, we built a large audio-visual (A/V) dataset of segmented utterances extracted from YouTube public videos, leading to 31k hours of audio-visual training content. The performance of an audio-only, visual-only, and audio-visual system are compared on two large-vocabulary test sets: a set of utterance segments from public YouTube videos called YTDEV18 and the publicly available LRS3-TED set. To highlight the contribution of the visual modality, we also evaluated the performance of our system on the YTDEV18 set artificially corrupted with background noise and overlapping speech. To the best of our knowledge, our system significantly improves the state-of-the-art on the LRS3-TED set.
Make Up Your Mind! Adversarial Generation of Inconsistent Natural Language Explanations
Oct 09, 2019
To increase trust in artificial intelligence systems, a growing amount of works are enhancing these systems with the capability of producing natural language explanations that support their predictions. In this work, we show that such appealing frameworks are nonetheless prone to generating inconsistent explanations, such as "A dog is an animal" and "A dog is not an animal", which are likely to decrease users' trust in these systems. To detect such inconsistencies, we introduce a simple but effective adversarial framework for generating a complete target sequence, a scenario that has not been addressed so far. Finally, we apply our framework to a state-of-the-art neural model that provides natural language explanations on SNLI, and we show that this model is capable of generating a significant amount of inconsistencies.
Speech bandwidth extension with WaveNet
Jul 05, 2019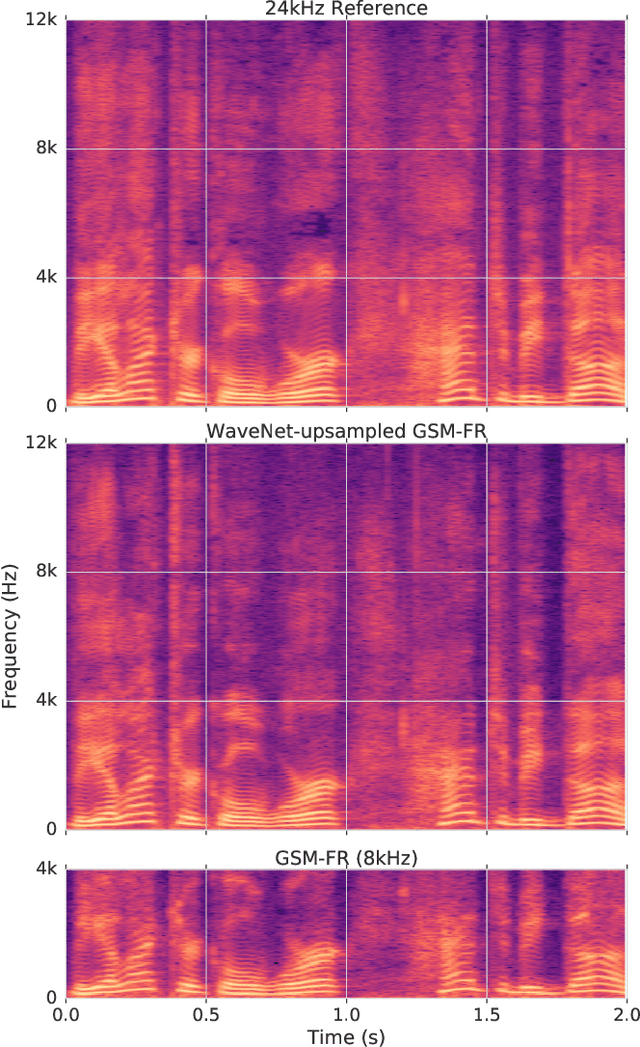
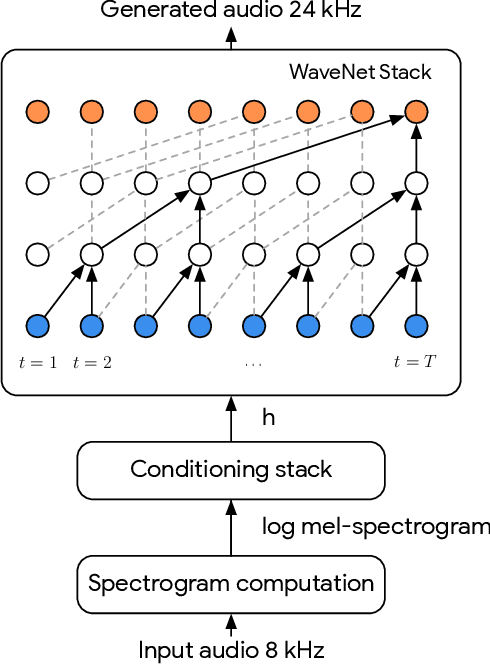
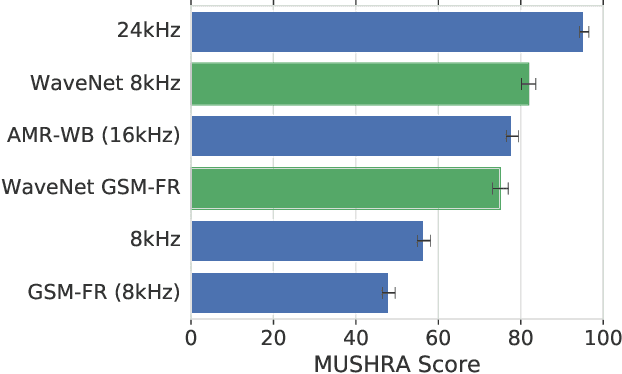
Large-scale mobile communication systems tend to contain legacy transmission channels with narrowband bottlenecks, resulting in characteristic "telephone-quality" audio. While higher quality codecs exist, due to the scale and heterogeneity of the networks, transmitting higher sample rate audio with modern high-quality audio codecs can be difficult in practice. This paper proposes an approach where a communication node can instead extend the bandwidth of a band-limited incoming speech signal that may have been passed through a low-rate codec. To this end, we propose a WaveNet-based model conditioned on a log-mel spectrogram representation of a bandwidth-constrained speech audio signal of 8 kHz and audio with artifacts from GSM full-rate (FR) compression to reconstruct the higher-resolution signal. In our experimental MUSHRA evaluation, we show that a model trained to upsample to 24kHz speech signals from audio passed through the 8kHz GSM-FR codec is able to reconstruct audio only slightly lower in quality to that of the Adaptive Multi-Rate Wideband audio codec (AMR-WB) codec at 16kHz, and closes around half the gap in perceptual quality between the original encoded signal and the original speech sampled at 24kHz. We further show that when the same model is passed 8kHz audio that has not been compressed, is able to again reconstruct audio of slightly better quality than 16kHz AMR-WB, in the same MUSHRA evaluation.
Large-Scale Visual Speech Recognition
Oct 01, 2018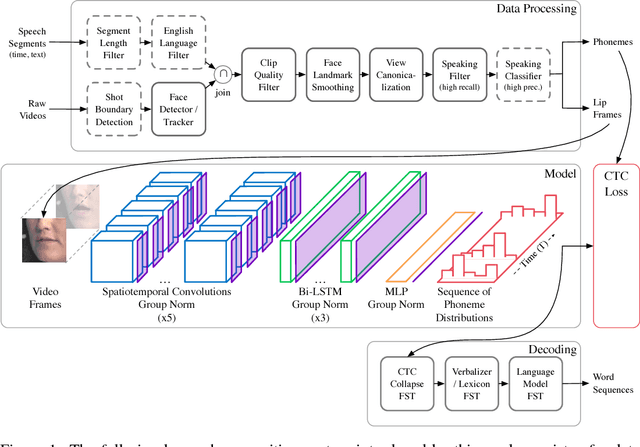
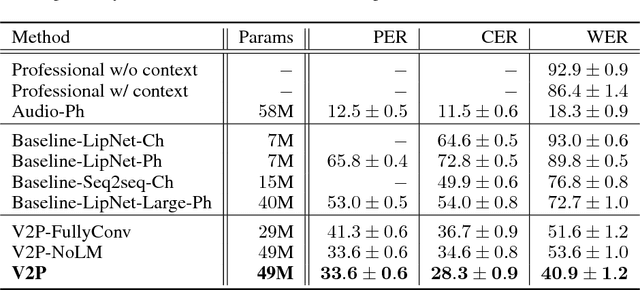


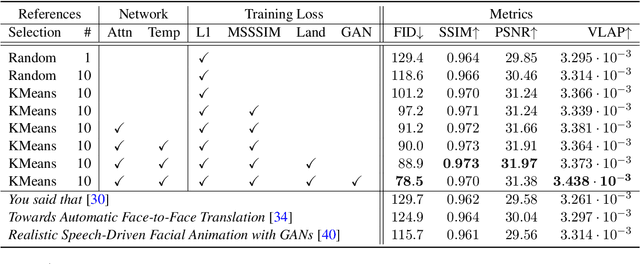
This work presents a scalable solution to open-vocabulary visual speech recognition. To achieve this, we constructed the largest existing visual speech recognition dataset, consisting of pairs of text and video clips of faces speaking (3,886 hours of video). In tandem, we designed and trained an integrated lipreading system, consisting of a video processing pipeline that maps raw video to stable videos of lips and sequences of phonemes, a scalable deep neural network that maps the lip videos to sequences of phoneme distributions, and a production-level speech decoder that outputs sequences of words. The proposed system achieves a word error rate (WER) of 40.9% as measured on a held-out set. In comparison, professional lipreaders achieve either 86.4% or 92.9% WER on the same dataset when having access to additional types of contextual information. Our approach significantly improves on other lipreading approaches, including variants of LipNet and of Watch, Attend, and Spell (WAS), which are only capable of 89.8% and 76.8% WER respectively.