 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe 2025 PNPL Competition: Speech Detection and Phoneme Classification in the LibriBrain Dataset
Jun 11, 2025The advance of speech decoding from non-invasive brain data holds the potential for profound societal impact. Among its most promising applications is the restoration of communication to paralysed individuals affected by speech deficits such as dysarthria, without the need for high-risk surgical interventions. The ultimate aim of the 2025 PNPL competition is to produce the conditions for an "ImageNet moment" or breakthrough in non-invasive neural decoding, by harnessing the collective power of the machine learning community. To facilitate this vision we present the largest within-subject MEG dataset recorded to date (LibriBrain) together with a user-friendly Python library (pnpl) for easy data access and integration with deep learning frameworks. For the competition we define two foundational tasks (i.e. Speech Detection and Phoneme Classification from brain data), complete with standardised data splits and evaluation metrics, illustrative benchmark models, online tutorial code, a community discussion board, and public leaderboard for submissions. To promote accessibility and participation the competition features a Standard track that emphasises algorithmic innovation, as well as an Extended track that is expected to reward larger-scale computing, accelerating progress toward a non-invasive brain-computer interface for speech.
Unlocking Non-Invasive Brain-to-Text
May 19, 2025Despite major advances in surgical brain-to-text (B2T), i.e. transcribing speech from invasive brain recordings, non-invasive alternatives have yet to surpass even chance on standard metrics. This remains a barrier to building a non-invasive brain-computer interface (BCI) capable of restoring communication in paralysed individuals without surgery. Here, we present the first non-invasive B2T result that significantly exceeds these critical baselines, raising BLEU by $1.4\mathrm{-}2.6\times$ over prior work. This result is driven by three contributions: (1) we extend recent word-classification models with LLM-based rescoring, transforming single-word predictors into closed-vocabulary B2T systems; (2) we introduce a predictive in-filling approach to handle out-of-vocabulary (OOV) words, substantially expanding the effective vocabulary; and (3) we demonstrate, for the first time, how to scale non-invasive B2T models across datasets, unlocking deep learning at scale and improving accuracy by $2.1\mathrm{-}2.3\times$. Through these contributions, we offer new insights into the roles of data quality and vocabulary size. Together, our results remove a major obstacle to realising practical non-invasive B2T systems.
The Brain's Bitter Lesson: Scaling Speech Decoding With Self-Supervised Learning
Jun 06, 2024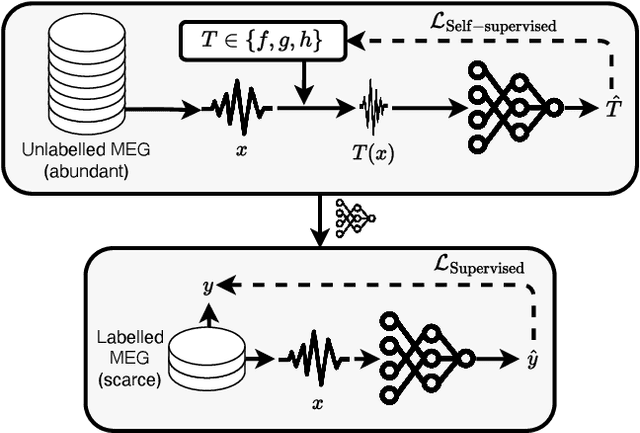
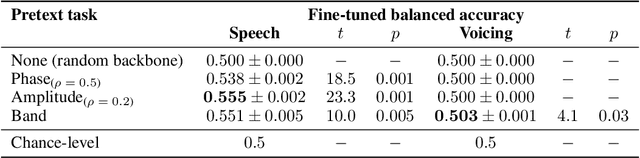
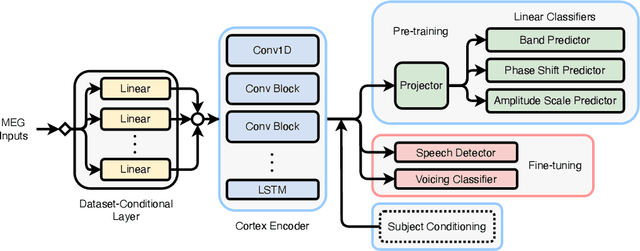
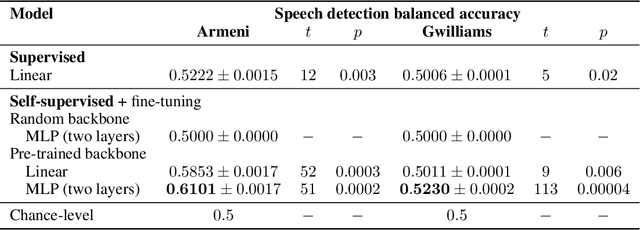
The past few years have produced a series of spectacular advances in the decoding of speech from brain activity. The engine of these advances has been the acquisition of labelled data, with increasingly large datasets acquired from single subjects. However, participants exhibit anatomical and other individual differences, and datasets use varied scanners and task designs. As a result, prior work has struggled to leverage data from multiple subjects, multiple datasets, multiple tasks, and unlabelled datasets. In turn, the field has not benefited from the rapidly growing number of open neural data repositories to exploit large-scale data and deep learning. To address this, we develop an initial set of neuroscience-inspired self-supervised objectives, together with a neural architecture, for representation learning from heterogeneous and unlabelled neural recordings. Experimental results show that representations learned with these objectives generalise across subjects, datasets, and tasks, and are also learned faster than using only labelled data. In addition, we set new benchmarks for two foundational speech decoding tasks. Taken together, these methods now unlock the potential for training speech decoding models with orders of magnitude more existing data.