 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHorizonMath: Measuring AI Progress Toward Mathematical Discovery with Automatic Verification
Mar 16, 2026Can AI make progress on important, unsolved mathematical problems? Large language models are now capable of sophisticated mathematical and scientific reasoning, but whether they can perform novel research is still widely debated and underexplored. We introduce HorizonMath, a benchmark of over 100 predominantly unsolved problems spanning 8 domains in computational and applied mathematics, paired with an open-source evaluation framework for automated verification. Our benchmark targets a class of problems where discovery is hard, requiring meaningful mathematical insight, but verification is computationally efficient and simple. Because these solutions are unknown, HorizonMath is immune to data contamination, and most state-of-the-art models score near 0%. Existing research-level benchmarks instead rely on formal proof verification or manual review, both of which are expensive to scale. Using this platform, we find two problems for which GPT 5.4 Pro proposes solutions that improve on the best-known published results, representing potential novel contributions (pending expert review). We release HorizonMath as an open challenge and a growing community resource, where correct solutions to problems in the unsolved problem classes could constitute novel results in the mathematical literature.
MEG-XL: Data-Efficient Brain-to-Text via Long-Context Pre-Training
Feb 02, 2026Clinical brain-to-text interfaces are designed for paralysed patients who cannot provide extensive training recordings. Pre-training improves data-efficient generalisation by learning statistical priors across subjects, but these priors critically depend on context. While natural speech might unfold gradually over minutes, most methods pre-train with only a few seconds of context. Thus, we propose MEG-XL, a model pre-trained with 2.5 minutes of MEG context per sample, 5-300x longer than prior work, and equivalent to 191k tokens, capturing extended neural context. Fine-tuning on the task of word decoding from brain data, MEG-XL matches supervised performance with a fraction of the data (e.g. 1hr vs 50hrs) and outperforms brain foundation models. We find that models pre-trained with longer contexts learn representations that transfer better to word decoding. Our results indicate that long-context pre-training helps exploit extended neural context that other methods unnecessarily discard. Code, model weights, and instructions are available at https://github.com/neural-processing-lab/MEG-XL .
Training AI Co-Scientists Using Rubric Rewards
Dec 29, 2025AI co-scientists are emerging as a tool to assist human researchers in achieving their research goals. A crucial feature of these AI co-scientists is the ability to generate a research plan given a set of aims and constraints. The plan may be used by researchers for brainstorming, or may even be implemented after further refinement. However, language models currently struggle to generate research plans that follow all constraints and implicit requirements. In this work, we study how to leverage the vast corpus of existing research papers to train language models that generate better research plans. We build a scalable, diverse training corpus by automatically extracting research goals and goal-specific grading rubrics from papers across several domains. We then train models for research plan generation via reinforcement learning with self-grading. A frozen copy of the initial policy acts as the grader during training, with the rubrics creating a generator-verifier gap that enables improvements without external human supervision. To validate this approach, we conduct a study with human experts for machine learning research goals, spanning 225 hours. The experts prefer plans generated by our finetuned Qwen3-30B-A3B model over the initial model for 70% of research goals, and approve 84% of the automatically extracted goal-specific grading rubrics. To assess generality, we also extend our approach to research goals from medical papers, and new arXiv preprints, evaluating with a jury of frontier models. Our finetuning yields 12-22% relative improvements and significant cross-domain generalization, proving effective even in problem settings like medical research where execution feedback is infeasible. Together, these findings demonstrate the potential of a scalable, automated training recipe as a step towards improving general AI co-scientists.
Compute as Teacher: Turning Inference Compute Into Reference-Free Supervision
Sep 17, 2025Where do learning signals come from when there is no ground truth in post-training? We propose turning exploration into supervision through Compute as Teacher (CaT), which converts the model's own exploration at inference-time into reference-free supervision by synthesizing a single reference from a group of parallel rollouts and then optimizing toward it. Concretely, the current policy produces a group of rollouts; a frozen anchor (the initial policy) reconciles omissions and contradictions to estimate a reference, turning extra inference-time compute into a teacher signal. We turn this into rewards in two regimes: (i) verifiable tasks use programmatic equivalence on final answers; (ii) non-verifiable tasks use self-proposed rubrics-binary, auditable criteria scored by an independent LLM judge, with reward given by the fraction satisfied. Unlike selection methods (best-of-N, majority, perplexity, or judge scores), synthesis may disagree with the majority and be correct even when all rollouts are wrong; performance scales with the number of rollouts. As a test-time procedure, CaT improves Gemma 3 4B, Qwen 3 4B, and Llama 3.1 8B (up to +27% on MATH-500; +12% on HealthBench). With reinforcement learning (CaT-RL), we obtain further gains (up to +33% and +30%), with the trained policy surpassing the initial teacher signal.
The 2025 PNPL Competition: Speech Detection and Phoneme Classification in the LibriBrain Dataset
Jun 11, 2025The advance of speech decoding from non-invasive brain data holds the potential for profound societal impact. Among its most promising applications is the restoration of communication to paralysed individuals affected by speech deficits such as dysarthria, without the need for high-risk surgical interventions. The ultimate aim of the 2025 PNPL competition is to produce the conditions for an "ImageNet moment" or breakthrough in non-invasive neural decoding, by harnessing the collective power of the machine learning community. To facilitate this vision we present the largest within-subject MEG dataset recorded to date (LibriBrain) together with a user-friendly Python library (pnpl) for easy data access and integration with deep learning frameworks. For the competition we define two foundational tasks (i.e. Speech Detection and Phoneme Classification from brain data), complete with standardised data splits and evaluation metrics, illustrative benchmark models, online tutorial code, a community discussion board, and public leaderboard for submissions. To promote accessibility and participation the competition features a Standard track that emphasises algorithmic innovation, as well as an Extended track that is expected to reward larger-scale computing, accelerating progress toward a non-invasive brain-computer interface for speech.
Unlocking Non-Invasive Brain-to-Text
May 19, 2025Despite major advances in surgical brain-to-text (B2T), i.e. transcribing speech from invasive brain recordings, non-invasive alternatives have yet to surpass even chance on standard metrics. This remains a barrier to building a non-invasive brain-computer interface (BCI) capable of restoring communication in paralysed individuals without surgery. Here, we present the first non-invasive B2T result that significantly exceeds these critical baselines, raising BLEU by $1.4\mathrm{-}2.6\times$ over prior work. This result is driven by three contributions: (1) we extend recent word-classification models with LLM-based rescoring, transforming single-word predictors into closed-vocabulary B2T systems; (2) we introduce a predictive in-filling approach to handle out-of-vocabulary (OOV) words, substantially expanding the effective vocabulary; and (3) we demonstrate, for the first time, how to scale non-invasive B2T models across datasets, unlocking deep learning at scale and improving accuracy by $2.1\mathrm{-}2.3\times$. Through these contributions, we offer new insights into the roles of data quality and vocabulary size. Together, our results remove a major obstacle to realising practical non-invasive B2T systems.
Long-Range Tasks Using Short-Context LLMs: Incremental Reasoning With Structured Memories
Dec 25, 2024



Long-range tasks require reasoning over long inputs. Existing solutions either need large compute budgets, training data, access to model weights, or use complex, task-specific approaches. We present PRISM, which alleviates these concerns by processing information as a stream of chunks, maintaining a structured in-context memory specified by a typed hierarchy schema. This approach demonstrates superior performance to baselines on diverse tasks while using at least 4x smaller contexts than long-context models. Moreover, PRISM is token-efficient. By producing short outputs and efficiently leveraging key-value (KV) caches, it achieves up to 54% cost reduction when compared to alternative short-context approaches. The method also scales down to tiny information chunks (e.g., 500 tokens) without increasing the number of tokens encoded or sacrificing quality. Furthermore, we show that it is possible to generate schemas to generalize our approach to new tasks with minimal effort.
The Brain's Bitter Lesson: Scaling Speech Decoding With Self-Supervised Learning
Jun 06, 2024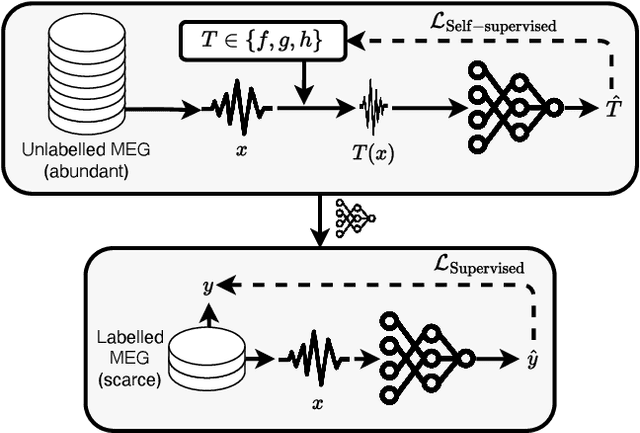
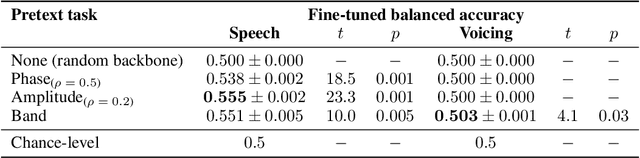
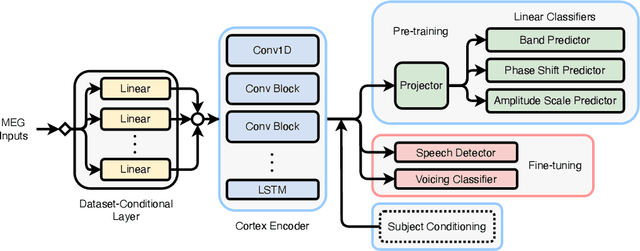
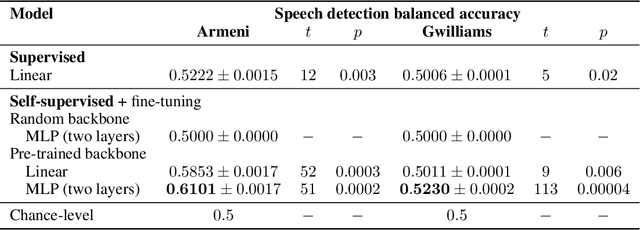
The past few years have produced a series of spectacular advances in the decoding of speech from brain activity. The engine of these advances has been the acquisition of labelled data, with increasingly large datasets acquired from single subjects. However, participants exhibit anatomical and other individual differences, and datasets use varied scanners and task designs. As a result, prior work has struggled to leverage data from multiple subjects, multiple datasets, multiple tasks, and unlabelled datasets. In turn, the field has not benefited from the rapidly growing number of open neural data repositories to exploit large-scale data and deep learning. To address this, we develop an initial set of neuroscience-inspired self-supervised objectives, together with a neural architecture, for representation learning from heterogeneous and unlabelled neural recordings. Experimental results show that representations learned with these objectives generalise across subjects, datasets, and tasks, and are also learned faster than using only labelled data. In addition, we set new benchmarks for two foundational speech decoding tasks. Taken together, these methods now unlock the potential for training speech decoding models with orders of magnitude more existing data.
Generalising Multi-Agent Cooperation through Task-Agnostic Communication
Mar 11, 2024Existing communication methods for multi-agent reinforcement learning (MARL) in cooperative multi-robot problems are almost exclusively task-specific, training new communication strategies for each unique task. We address this inefficiency by introducing a communication strategy applicable to any task within a given environment. We pre-train the communication strategy without task-specific reward guidance in a self-supervised manner using a set autoencoder. Our objective is to learn a fixed-size latent Markov state from a variable number of agent observations. Under mild assumptions, we prove that policies using our latent representations are guaranteed to converge, and upper bound the value error introduced by our Markov state approximation. Our method enables seamless adaptation to novel tasks without fine-tuning the communication strategy, gracefully supports scaling to more agents than present during training, and detects out-of-distribution events in an environment. Empirical results on diverse MARL scenarios validate the effectiveness of our approach, surpassing task-specific communication strategies in unseen tasks. Our implementation of this work is available at https://github.com/proroklab/task-agnostic-comms.
Does Double Descent Occur in Self-Supervised Learning?
Jul 15, 2023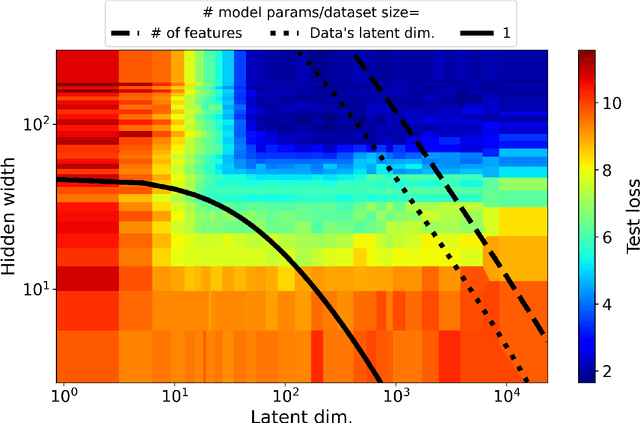
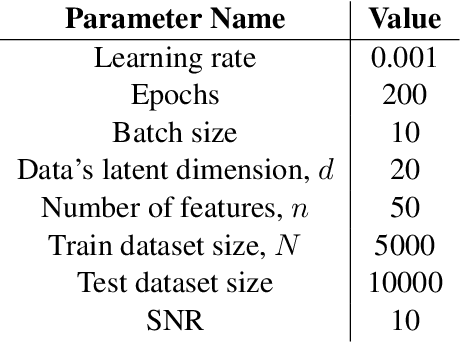
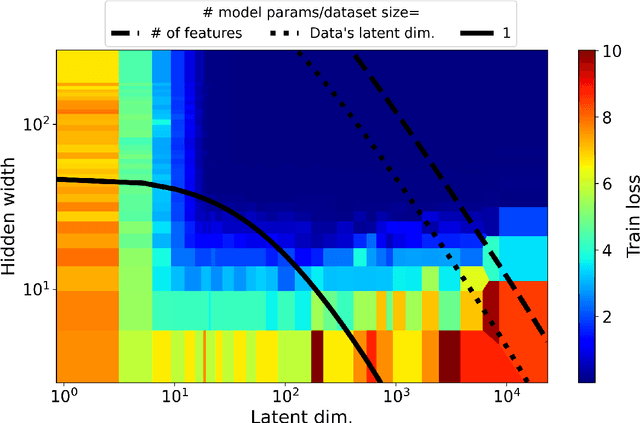
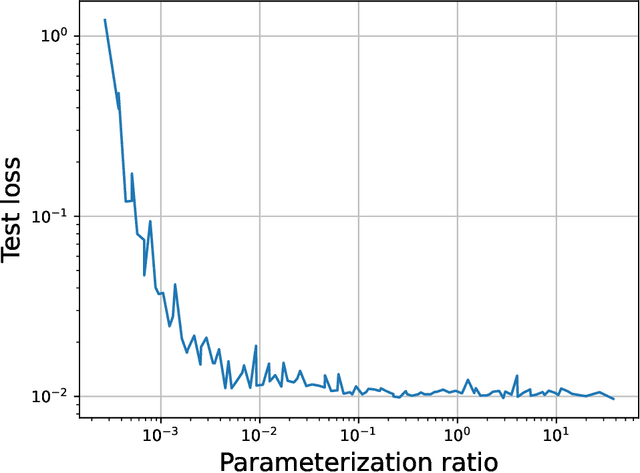
Most investigations into double descent have focused on supervised models while the few works studying self-supervised settings find a surprising lack of the phenomenon. These results imply that double descent may not exist in self-supervised models. We show this empirically using a standard and linear autoencoder, two previously unstudied settings. The test loss is found to have either a classical U-shape or to monotonically decrease instead of exhibiting a double-descent curve. We hope that further work on this will help elucidate the theoretical underpinnings of this phenomenon.