 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Range Tasks Using Short-Context LLMs: Incremental Reasoning With Structured Memories
Dec 25, 2024



Long-range tasks require reasoning over long inputs. Existing solutions either need large compute budgets, training data, access to model weights, or use complex, task-specific approaches. We present PRISM, which alleviates these concerns by processing information as a stream of chunks, maintaining a structured in-context memory specified by a typed hierarchy schema. This approach demonstrates superior performance to baselines on diverse tasks while using at least 4x smaller contexts than long-context models. Moreover, PRISM is token-efficient. By producing short outputs and efficiently leveraging key-value (KV) caches, it achieves up to 54% cost reduction when compared to alternative short-context approaches. The method also scales down to tiny information chunks (e.g., 500 tokens) without increasing the number of tokens encoded or sacrificing quality. Furthermore, we show that it is possible to generate schemas to generalize our approach to new tasks with minimal effort.
Enhancing Incremental Summarization with Structured Representations
Jul 21, 2024



Large language models (LLMs) often struggle with processing extensive input contexts, which can lead to redundant, inaccurate, or incoherent summaries. Recent methods have used unstructured memory to incrementally process these contexts, but they still suffer from information overload due to the volume of unstructured data handled. In our study, we introduce structured knowledge representations ($GU_{json}$), which significantly improve summarization performance by 40% and 14% across two public datasets. Most notably, we propose the Chain-of-Key strategy ($CoK_{json}$) that dynamically updates or augments these representations with new information, rather than recreating the structured memory for each new source. This method further enhances performance by 7% and 4% on the datasets.
SUMIE: A Synthetic Benchmark for Incremental Entity Summarization
Jun 07, 2024
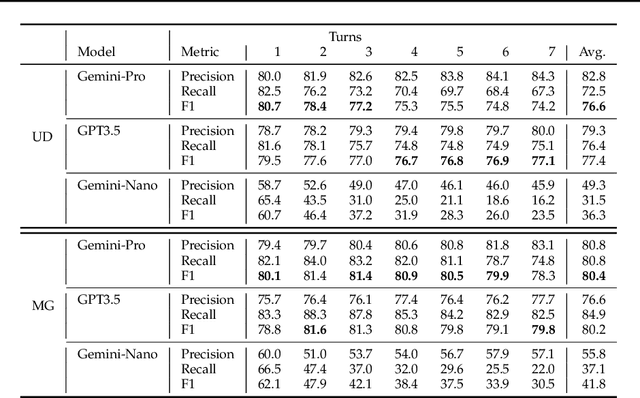
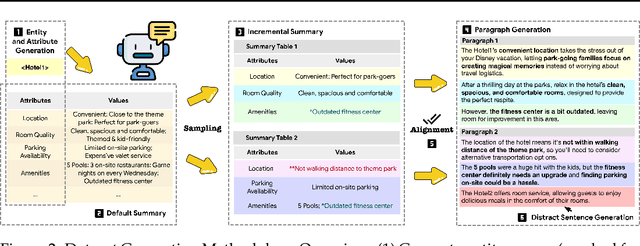
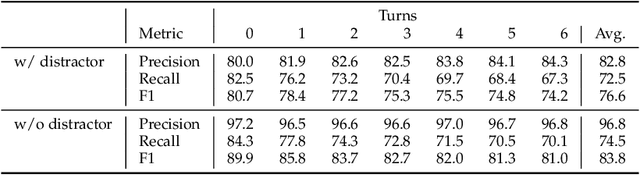
No existing dataset adequately tests how well language models can incrementally update entity summaries - a crucial ability as these models rapidly advance. The Incremental Entity Summarization (IES) task is vital for maintaining accurate, up-to-date knowledge. To address this, we introduce SUMIE, a fully synthetic dataset designed to expose real-world IES challenges. This dataset effectively highlights problems like incorrect entity association and incomplete information presentation. Unlike common synthetic datasets, ours captures the complexity and nuances found in real-world data. We generate informative and diverse attributes, summaries, and unstructured paragraphs in sequence, ensuring high quality. The alignment between generated summaries and paragraphs exceeds 96%, confirming the dataset's quality. Extensive experiments demonstrate the dataset's difficulty - state-of-the-art LLMs struggle to update summaries with an F1 higher than 80.4%. We will open source the benchmark and the evaluation metrics to help the community make progress on IES tasks.