 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFundamental Limits of Perfect Concept Erasure
Mar 25, 2025Concept erasure is the task of erasing information about a concept (e.g., gender or race) from a representation set while retaining the maximum possible utility -- information from original representations. Concept erasure is useful in several applications, such as removing sensitive concepts to achieve fairness and interpreting the impact of specific concepts on a model's performance. Previous concept erasure techniques have prioritized robustly erasing concepts over retaining the utility of the resultant representations. However, there seems to be an inherent tradeoff between erasure and retaining utility, making it unclear how to achieve perfect concept erasure while maintaining high utility. In this paper, we offer a fresh perspective toward solving this problem by quantifying the fundamental limits of concept erasure through an information-theoretic lens. Using these results, we investigate constraints on the data distribution and the erasure functions required to achieve the limits of perfect concept erasure. Empirically, we show that the derived erasure functions achieve the optimal theoretical bounds. Additionally, we show that our approach outperforms existing methods on a range of synthetic and real-world datasets using GPT-4 representations.
Long-Range Tasks Using Short-Context LLMs: Incremental Reasoning With Structured Memories
Dec 25, 2024



Long-range tasks require reasoning over long inputs. Existing solutions either need large compute budgets, training data, access to model weights, or use complex, task-specific approaches. We present PRISM, which alleviates these concerns by processing information as a stream of chunks, maintaining a structured in-context memory specified by a typed hierarchy schema. This approach demonstrates superior performance to baselines on diverse tasks while using at least 4x smaller contexts than long-context models. Moreover, PRISM is token-efficient. By producing short outputs and efficiently leveraging key-value (KV) caches, it achieves up to 54% cost reduction when compared to alternative short-context approaches. The method also scales down to tiny information chunks (e.g., 500 tokens) without increasing the number of tokens encoded or sacrificing quality. Furthermore, we show that it is possible to generate schemas to generalize our approach to new tasks with minimal effort.
SIKeD: Self-guided Iterative Knowledge Distillation for mathematical reasoning
Oct 24, 2024

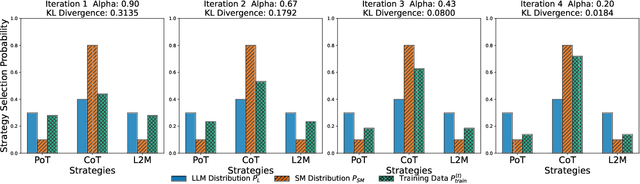

Large Language Models (LLMs) can transfer their reasoning skills to smaller models by teaching them to generate the intermediate reasoning process required to solve multistep reasoning tasks. While LLMs can accurately solve reasoning tasks through a variety of strategies, even without fine-tuning, smaller models are not expressive enough to fit the LLMs distribution on all strategies when distilled and tend to prioritize one strategy over the others. This reliance on one strategy poses a challenge for smaller models when attempting to solve reasoning tasks that may be difficult with their preferred strategy. To address this, we propose a distillation method SIKeD (Self-guided Iterative Knowledge Distillation for mathematical reasoning), where the LLM teaches the smaller model to approach a task using different strategies and the smaller model uses its self-generated on-policy outputs to choose the most suitable strategy for the given task. The training continues in a self-guided iterative manner, where for each training iteration, a decision is made on how to combine the LLM data with the self-generated outputs. Unlike traditional distillation methods, SIKeD allows the smaller model to learn which strategy is suitable for a given task while continuously learning to solve a task using different strategies. Our experiments on various mathematical reasoning datasets show that SIKeD significantly outperforms traditional distillation techniques across smaller models of different sizes. Our code is available at: https://github.com/kumar-shridhar/SIKeD
A Fresh Take on Stale Embeddings: Improving Dense Retriever Training with Corrector Networks
Sep 03, 2024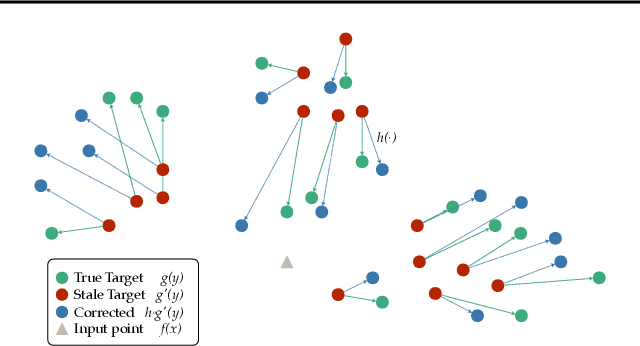
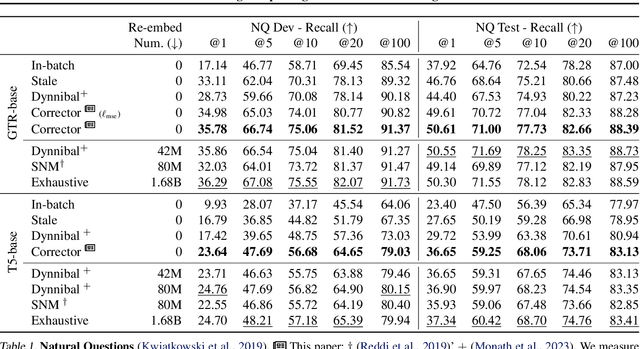
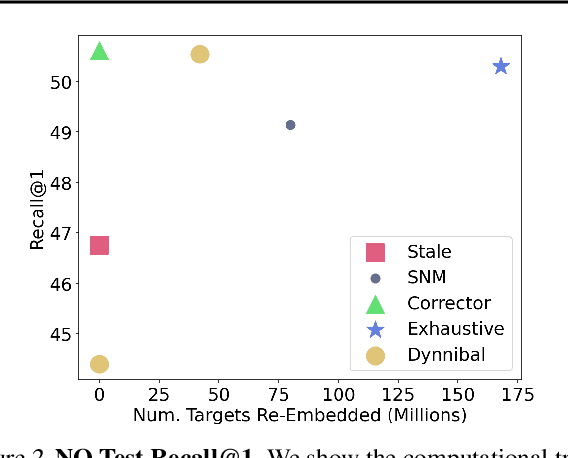
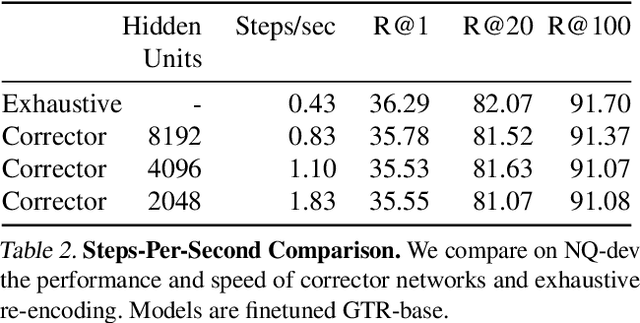
In dense retrieval, deep encoders provide embeddings for both inputs and targets, and the softmax function is used to parameterize a distribution over a large number of candidate targets (e.g., textual passages for information retrieval). Significant challenges arise in training such encoders in the increasingly prevalent scenario of (1) a large number of targets, (2) a computationally expensive target encoder model, (3) cached target embeddings that are out-of-date due to ongoing training of target encoder parameters. This paper presents a simple and highly scalable response to these challenges by training a small parametric corrector network that adjusts stale cached target embeddings, enabling an accurate softmax approximation and thereby sampling of up-to-date high scoring "hard negatives." We theoretically investigate the generalization properties of our proposed target corrector, relating the complexity of the network, staleness of cached representations, and the amount of training data. We present experimental results on large benchmark dense retrieval datasets as well as on QA with retrieval augmented language models. Our approach matches state-of-the-art results even when no target embedding updates are made during training beyond an initial cache from the unsupervised pre-trained model, providing a 4-80x reduction in re-embedding computational cost.
Analysis of Plan-based Retrieval for Grounded Text Generation
Aug 20, 2024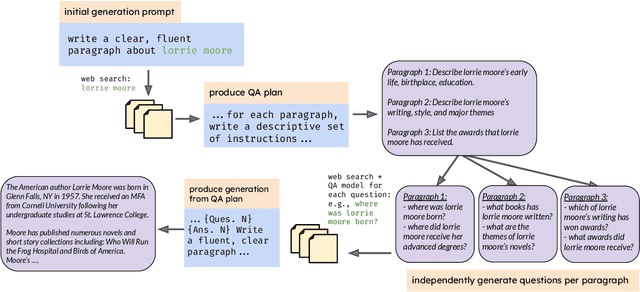
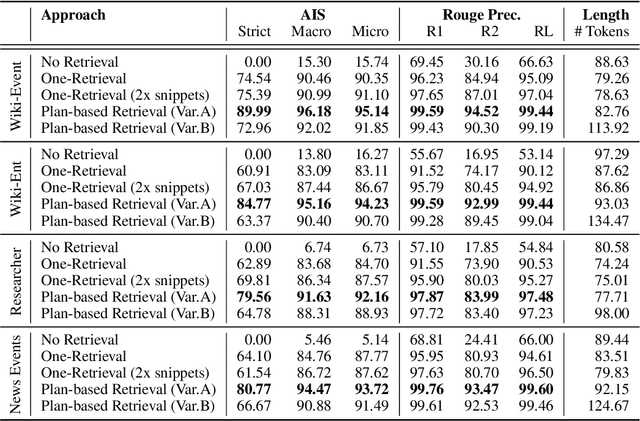

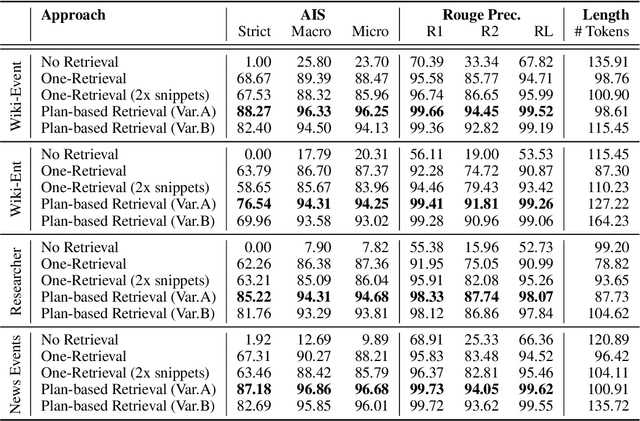
In text generation, hallucinations refer to the generation of seemingly coherent text that contradicts established knowledge. One compelling hypothesis is that hallucinations occur when a language model is given a generation task outside its parametric knowledge (due to rarity, recency, domain, etc.). A common strategy to address this limitation is to infuse the language models with retrieval mechanisms, providing the model with relevant knowledge for the task. In this paper, we leverage the planning capabilities of instruction-tuned LLMs and analyze how planning can be used to guide retrieval to further reduce the frequency of hallucinations. We empirically evaluate several variations of our proposed approach on long-form text generation tasks. By improving the coverage of relevant facts, plan-guided retrieval and generation can produce more informative responses while providing a higher rate of attribution to source documents.
Adaptive Retrieval and Scalable Indexing for k-NN Search with Cross-Encoders
May 06, 2024Cross-encoder (CE) models which compute similarity by jointly encoding a query-item pair perform better than embedding-based models (dual-encoders) at estimating query-item relevance. Existing approaches perform k-NN search with CE by approximating the CE similarity with a vector embedding space fit either with dual-encoders (DE) or CUR matrix factorization. DE-based retrieve-and-rerank approaches suffer from poor recall on new domains and the retrieval with DE is decoupled from the CE. While CUR-based approaches can be more accurate than the DE-based approach, they require a prohibitively large number of CE calls to compute item embeddings, thus making it impractical for deployment at scale. In this paper, we address these shortcomings with our proposed sparse-matrix factorization based method that efficiently computes latent query and item embeddings to approximate CE scores and performs k-NN search with the approximate CE similarity. We compute item embeddings offline by factorizing a sparse matrix containing query-item CE scores for a set of train queries. Our method produces a high-quality approximation while requiring only a fraction of CE calls as compared to CUR-based methods, and allows for leveraging DE to initialize the embedding space while avoiding compute- and resource-intensive finetuning of DE via distillation. At test time, the item embeddings remain fixed and retrieval occurs over rounds, alternating between a) estimating the test query embedding by minimizing error in approximating CE scores of items retrieved thus far, and b) using the updated test query embedding for retrieving more items. Our k-NN search method improves recall by up to 5% (k=1) and 54% (k=100) over DE-based approaches. Additionally, our indexing approach achieves a speedup of up to 100x over CUR-based and 5x over DE distillation methods, while matching or improving k-NN search recall over baselines.
Incremental Extractive Opinion Summarization Using Cover Trees
Jan 16, 2024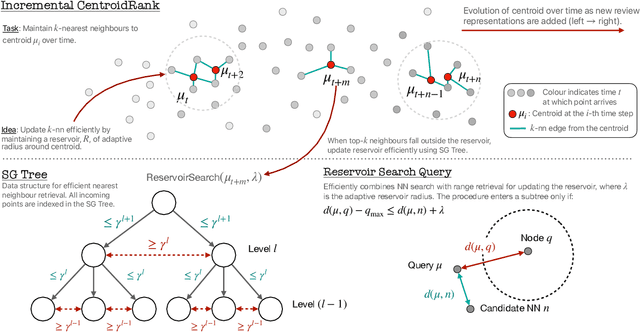
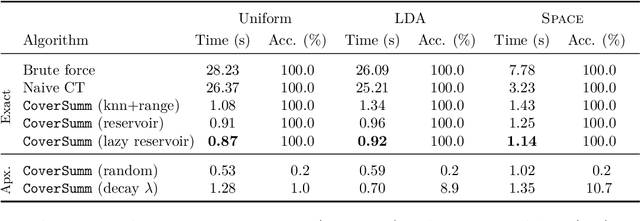
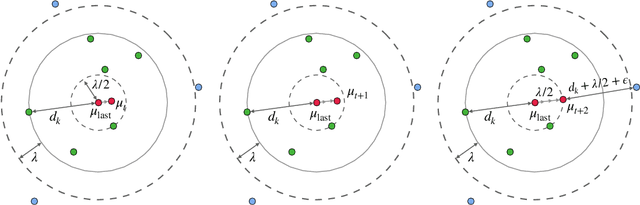
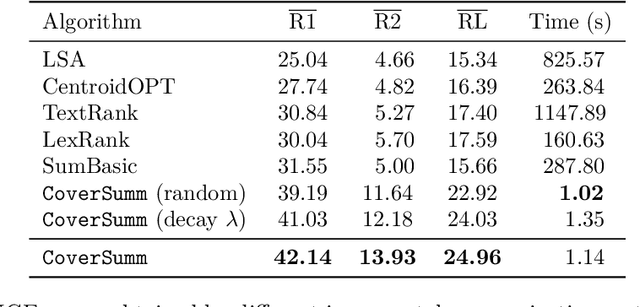
Extractive opinion summarization involves automatically producing a summary of text about an entity (e.g., a product's reviews) by extracting representative sentences that capture prevalent opinions in the review set. Typically, in online marketplaces user reviews accrue over time, and opinion summaries need to be updated periodically to provide customers with up-to-date information. In this work, we study the task of extractive opinion summarization in an incremental setting, where the underlying review set evolves over time. Many of the state-of-the-art extractive opinion summarization approaches are centrality-based, such as CentroidRank. CentroidRank performs extractive summarization by selecting a subset of review sentences closest to the centroid in the representation space as the summary. However, these methods are not capable of operating efficiently in an incremental setting, where reviews arrive one at a time. In this paper, we present an efficient algorithm for accurately computing the CentroidRank summaries in an incremental setting. Our approach, CoverSumm, relies on indexing review representations in a cover tree and maintaining a reservoir of candidate summary review sentences. CoverSumm's efficacy is supported by a theoretical and empirical analysis of running time. Empirically, on a diverse collection of data (both real and synthetically created to illustrate scaling considerations), we demonstrate that CoverSumm is up to 25x faster than baseline methods, and capable of adapting to nuanced changes in data distribution. We also conduct human evaluations of the generated summaries and find that CoverSumm is capable of producing informative summaries consistent with the underlying review set.
Robust Concept Erasure via Kernelized Rate-Distortion Maximization
Nov 30, 2023Distributed representations provide a vector space that captures meaningful relationships between data instances. The distributed nature of these representations, however, entangles together multiple attributes or concepts of data instances (e.g., the topic or sentiment of a text, characteristics of the author (age, gender, etc), etc). Recent work has proposed the task of concept erasure, in which rather than making a concept predictable, the goal is to remove an attribute from distributed representations while retaining other information from the original representation space as much as possible. In this paper, we propose a new distance metric learning-based objective, the Kernelized Rate-Distortion Maximizer (KRaM), for performing concept erasure. KRaM fits a transformation of representations to match a specified distance measure (defined by a labeled concept to erase) using a modified rate-distortion function. Specifically, KRaM's objective function aims to make instances with similar concept labels dissimilar in the learned representation space while retaining other information. We find that optimizing KRaM effectively erases various types of concepts: categorical, continuous, and vector-valued variables from data representations across diverse domains. We also provide a theoretical analysis of several properties of KRaM's objective. To assess the quality of the learned representations, we propose an alignment score to evaluate their similarity with the original representation space. Additionally, we conduct experiments to showcase KRaM's efficacy in various settings, from erasing binary gender variables in word embeddings to vector-valued variables in GPT-3 representations.
Enhancing Group Fairness in Online Settings Using Oblique Decision Forests
Oct 17, 2023Fairness, especially group fairness, is an important consideration in the context of machine learning systems. The most commonly adopted group fairness-enhancing techniques are in-processing methods that rely on a mixture of a fairness objective (e.g., demographic parity) and a task-specific objective (e.g., cross-entropy) during the training process. However, when data arrives in an online fashion -- one instance at a time -- optimizing such fairness objectives poses several challenges. In particular, group fairness objectives are defined using expectations of predictions across different demographic groups. In the online setting, where the algorithm has access to a single instance at a time, estimating the group fairness objective requires additional storage and significantly more computation (e.g., forward/backward passes) than the task-specific objective at every time step. In this paper, we propose Aranyani, an ensemble of oblique decision trees, to make fair decisions in online settings. The hierarchical tree structure of Aranyani enables parameter isolation and allows us to efficiently compute the fairness gradients using aggregate statistics of previous decisions, eliminating the need for additional storage and forward/backward passes. We also present an efficient framework to train Aranyani and theoretically analyze several of its properties. We conduct empirical evaluations on 5 publicly available benchmarks (including vision and language datasets) to show that Aranyani achieves a better accuracy-fairness trade-off compared to baseline approaches.
Adaptive Selection of Anchor Items for CUR-based k-NN search with Cross-Encoders
May 04, 2023



Cross-encoder models, which jointly encode and score a query-item pair, are typically prohibitively expensive for k-nearest neighbor search. Consequently, k-NN search is performed not with a cross-encoder, but with a heuristic retrieve (e.g., using BM25 or dual-encoder) and re-rank approach. Recent work proposes ANNCUR (Yadav et al., 2022) which uses CUR matrix factorization to produce an embedding space for efficient vector-based search that directly approximates the cross-encoder without the need for dual-encoders. ANNCUR defines this shared query-item embedding space by scoring the test query against anchor items which are sampled uniformly at random. While this minimizes average approximation error over all items, unsuitably high approximation error on top-k items remains and leads to poor recall of top-k (and especially top-1) items. Increasing the number of anchor items is a straightforward way of improving the approximation error and hence k-NN recall of ANNCUR but at the cost of increased inference latency. In this paper, we propose a new method for adaptively choosing anchor items that minimizes the approximation error for the practically important top-k neighbors for a query with minimal computational overhead. Our proposed method incrementally selects a suitable set of anchor items for a given test query over several rounds, using anchors chosen in previous rounds to inform selection of more anchor items. Empirically, our method consistently improves k-NN recall as compared to both ANNCUR and the widely-used dual-encoder-based retrieve-and-rerank approach.