 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-time Unlearning Using Conformal Prediction
Feb 03, 2026Machine unlearning is the process of efficiently removing specific information from a trained machine learning model without retraining from scratch. Existing unlearning methods, which often provide provable guarantees, typically involve retraining a subset of model parameters based on a forget set. While these approaches show promise in certain scenarios, their underlying assumptions are often challenged in real-world applications -- particularly when applied to generative models. Furthermore, updating parameters using these unlearning procedures often degrades the general-purpose capabilities the model acquired during pre-training. Motivated by these shortcomings, this paper considers the paradigm of inference time unlearning -- wherein, the generative model is equipped with an (approximately correct) verifier that judges whether the model's response satisfies appropriate unlearning guarantees. This paper introduces a framework that iteratively refines the quality of the generated responses using feedback from the verifier without updating the model parameters. The proposed framework leverages conformal prediction to reduce computational overhead and provide distribution-free unlearning guarantees. This paper's approach significantly outperforms existing state-of-the-art methods, reducing unlearning error by up to 93% across challenging unlearning benchmarks.
EUGens: Efficient, Unified, and General Dense Layers
Jan 30, 2026Efficient neural networks are essential for scaling machine learning models to real-time applications and resource-constrained environments. Fully-connected feedforward layers (FFLs) introduce computation and parameter count bottlenecks within neural network architectures. To address this challenge, in this work, we propose a new class of dense layers that generalize standard fully-connected feedforward layers, \textbf{E}fficient, \textbf{U}nified and \textbf{Gen}eral dense layers (EUGens). EUGens leverage random features to approximate standard FFLs and go beyond them by incorporating a direct dependence on the input norms in their computations. The proposed layers unify existing efficient FFL extensions and improve efficiency by reducing inference complexity from quadratic to linear time. They also lead to \textbf{the first} unbiased algorithms approximating FFLs with arbitrary polynomial activation functions. Furthermore, EuGens reduce the parameter count and computational overhead while preserving the expressive power and adaptability of FFLs. We also present a layer-wise knowledge transfer technique that bypasses backpropagation, enabling efficient adaptation of EUGens to pre-trained models. Empirically, we observe that integrating EUGens into Transformers and MLPs yields substantial improvements in inference speed (up to \textbf{27}\%) and memory efficiency (up to \textbf{30}\%) across a range of tasks, including image classification, language model pre-training, and 3D scene reconstruction. Overall, our results highlight the potential of EUGens for the scalable deployment of large-scale neural networks in real-world scenarios.
Fundamental Limits of Perfect Concept Erasure
Mar 25, 2025Concept erasure is the task of erasing information about a concept (e.g., gender or race) from a representation set while retaining the maximum possible utility -- information from original representations. Concept erasure is useful in several applications, such as removing sensitive concepts to achieve fairness and interpreting the impact of specific concepts on a model's performance. Previous concept erasure techniques have prioritized robustly erasing concepts over retaining the utility of the resultant representations. However, there seems to be an inherent tradeoff between erasure and retaining utility, making it unclear how to achieve perfect concept erasure while maintaining high utility. In this paper, we offer a fresh perspective toward solving this problem by quantifying the fundamental limits of concept erasure through an information-theoretic lens. Using these results, we investigate constraints on the data distribution and the erasure functions required to achieve the limits of perfect concept erasure. Empirically, we show that the derived erasure functions achieve the optimal theoretical bounds. Additionally, we show that our approach outperforms existing methods on a range of synthetic and real-world datasets using GPT-4 representations.
Conditioned Language Policy: A General Framework for Steerable Multi-Objective Finetuning
Jul 22, 2024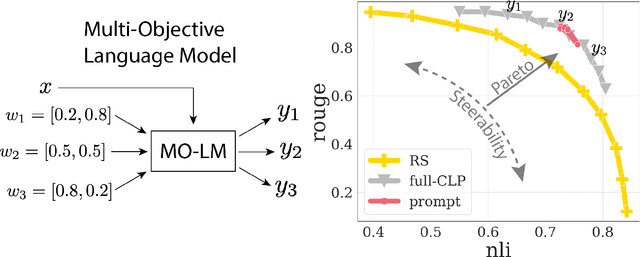
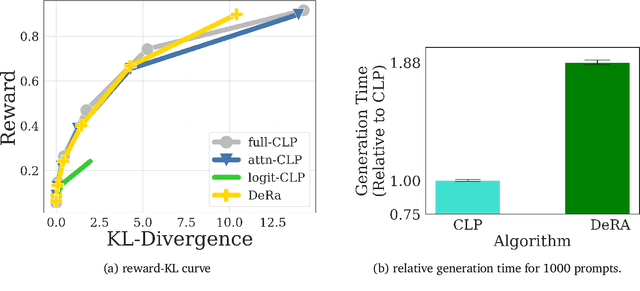
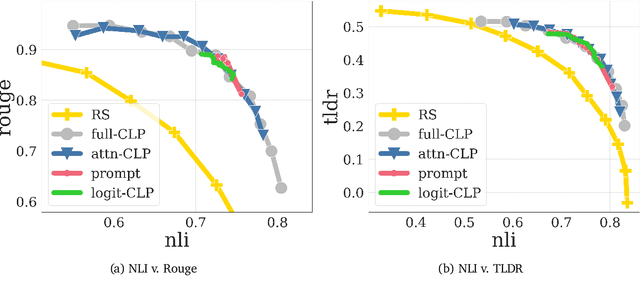
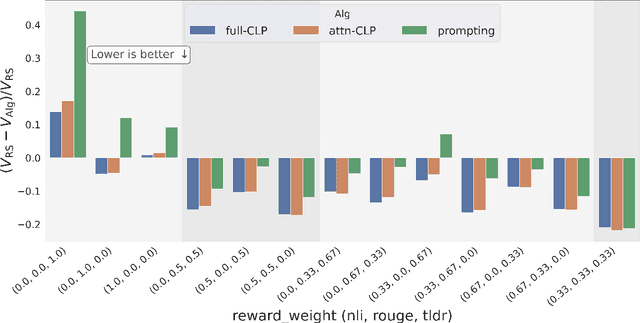
Reward-based finetuning is crucial for aligning language policies with intended behaviors (e.g., creativity and safety). A key challenge here is to develop steerable language models that trade-off multiple (conflicting) objectives in a flexible and efficient manner. This paper presents Conditioned Language Policy (CLP), a general framework for finetuning language models on multiple objectives. Building on techniques from multi-task training and parameter-efficient finetuning, CLP can learn steerable models that effectively trade-off conflicting objectives at inference time. Notably, this does not require training or maintaining multiple models to achieve different trade-offs between the objectives. Through an extensive set of experiments and ablations, we show that the CLP framework learns steerable models that outperform and Pareto-dominate the current state-of-the-art approaches for multi-objective finetuning.
Auctions with LLM Summaries
Apr 11, 2024We study an auction setting in which bidders bid for placement of their content within a summary generated by a large language model (LLM), e.g., an ad auction in which the display is a summary paragraph of multiple ads. This generalizes the classic ad settings such as position auctions to an LLM generated setting, which allows us to handle general display formats. We propose a novel factorized framework in which an auction module and an LLM module work together via a prediction model to provide welfare maximizing summary outputs in an incentive compatible manner. We provide a theoretical analysis of this framework and synthetic experiments to demonstrate the feasibility and validity of the system together with welfare comparisons.
A Minimaximalist Approach to Reinforcement Learning from Human Feedback
Jan 08, 2024We present Self-Play Preference Optimization (SPO), an algorithm for reinforcement learning from human feedback. Our approach is minimalist in that it does not require training a reward model nor unstable adversarial training and is therefore rather simple to implement. Our approach is maximalist in that it provably handles non-Markovian, intransitive, and stochastic preferences while being robust to the compounding errors that plague offline approaches to sequential prediction. To achieve the preceding qualities, we build upon the concept of a Minimax Winner (MW), a notion of preference aggregation from the social choice theory literature that frames learning from preferences as a zero-sum game between two policies. By leveraging the symmetry of this game, we prove that rather than using the traditional technique of dueling two policies to compute the MW, we can simply have a single agent play against itself while maintaining strong convergence guarantees. Practically, this corresponds to sampling multiple trajectories from a policy, asking a rater or preference model to compare them, and then using the proportion of wins as the reward for a particular trajectory. We demonstrate that on a suite of continuous control tasks, we are able to learn significantly more efficiently than reward-model based approaches while maintaining robustness to the intransitive and stochastic preferences that frequently occur in practice when aggregating human judgments.
Enhancing Group Fairness in Online Settings Using Oblique Decision Forests
Oct 17, 2023Fairness, especially group fairness, is an important consideration in the context of machine learning systems. The most commonly adopted group fairness-enhancing techniques are in-processing methods that rely on a mixture of a fairness objective (e.g., demographic parity) and a task-specific objective (e.g., cross-entropy) during the training process. However, when data arrives in an online fashion -- one instance at a time -- optimizing such fairness objectives poses several challenges. In particular, group fairness objectives are defined using expectations of predictions across different demographic groups. In the online setting, where the algorithm has access to a single instance at a time, estimating the group fairness objective requires additional storage and significantly more computation (e.g., forward/backward passes) than the task-specific objective at every time step. In this paper, we propose Aranyani, an ensemble of oblique decision trees, to make fair decisions in online settings. The hierarchical tree structure of Aranyani enables parameter isolation and allows us to efficiently compute the fairness gradients using aggregate statistics of previous decisions, eliminating the need for additional storage and forward/backward passes. We also present an efficient framework to train Aranyani and theoretically analyze several of its properties. We conduct empirical evaluations on 5 publicly available benchmarks (including vision and language datasets) to show that Aranyani achieves a better accuracy-fairness trade-off compared to baseline approaches.
Counterfactual Learning To Rank for Utility-Maximizing Query Autocompletion
Apr 22, 2022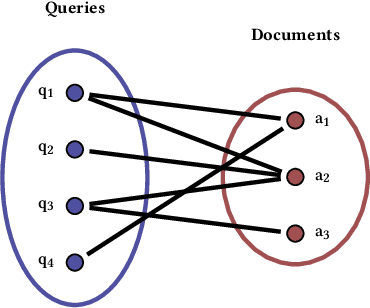

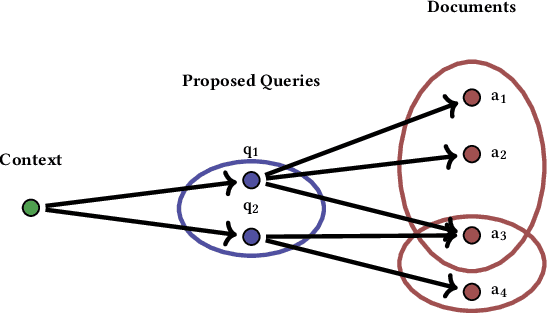
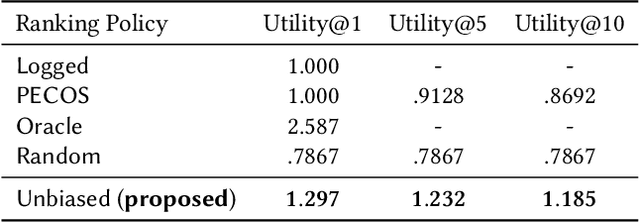
Conventional methods for query autocompletion aim to predict which completed query a user will select from a list. A shortcoming of this approach is that users often do not know which query will provide the best retrieval performance on the current information retrieval system, meaning that any query autocompletion methods trained to mimic user behavior can lead to suboptimal query suggestions. To overcome this limitation, we propose a new approach that explicitly optimizes the query suggestions for downstream retrieval performance. We formulate this as a problem of ranking a set of rankings, where each query suggestion is represented by the downstream item ranking it produces. We then present a learning method that ranks query suggestions by the quality of their item rankings. The algorithm is based on a counterfactual learning approach that is able to leverage feedback on the items (e.g., clicks, purchases) to evaluate query suggestions through an unbiased estimator, thus avoiding the assumption that users write or select optimal queries. We establish theoretical support for the proposed approach and provide learning-theoretic guarantees. We also present empirical results on publicly available datasets, and demonstrate real-world applicability using data from an online shopping store.
Mitigating Covariate Shift in Imitation Learning via Offline Data Without Great Coverage
Jun 14, 2021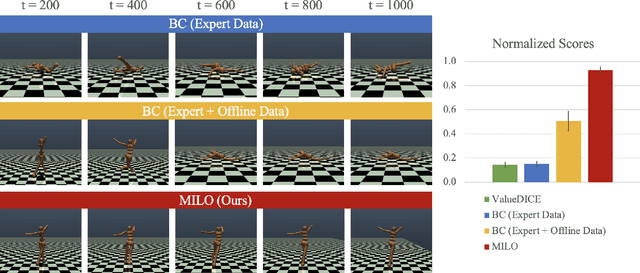

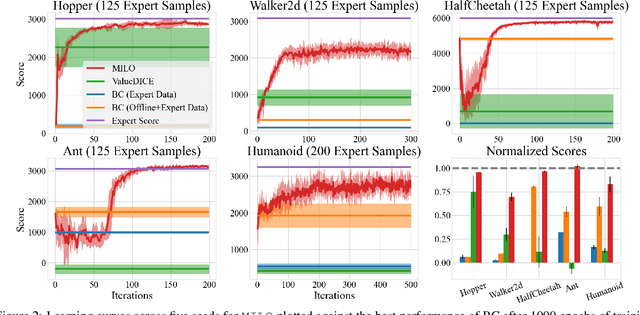
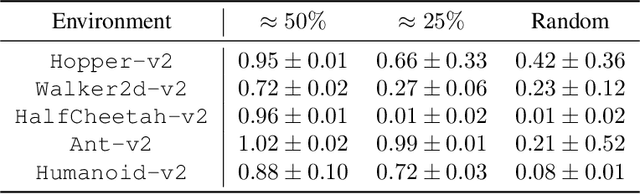
This paper studies offline Imitation Learning (IL) where an agent learns to imitate an expert demonstrator without additional online environment interactions. Instead, the learner is presented with a static offline dataset of state-action-next state transition triples from a potentially less proficient behavior policy. We introduce Model-based IL from Offline data (MILO): an algorithmic framework that utilizes the static dataset to solve the offline IL problem efficiently both in theory and in practice. In theory, even if the behavior policy is highly sub-optimal compared to the expert, we show that as long as the data from the behavior policy provides sufficient coverage on the expert state-action traces (and with no necessity for a global coverage over the entire state-action space), MILO can provably combat the covariate shift issue in IL. Complementing our theory results, we also demonstrate that a practical implementation of our approach mitigates covariate shift on benchmark MuJoCo continuous control tasks. We demonstrate that with behavior policies whose performances are less than half of that of the expert, MILO still successfully imitates with an extremely low number of expert state-action pairs while traditional offline IL method such as behavior cloning (BC) fails completely. Source code is provided at https://github.com/jdchang1/milo.
Making Paper Reviewing Robust to Bid Manipulation Attacks
Feb 22, 2021



Most computer science conferences rely on paper bidding to assign reviewers to papers. Although paper bidding enables high-quality assignments in days of unprecedented submission numbers, it also opens the door for dishonest reviewers to adversarially influence paper reviewing assignments. Anecdotal evidence suggests that some reviewers bid on papers by "friends" or colluding authors, even though these papers are outside their area of expertise, and recommend them for acceptance without considering the merit of the work. In this paper, we study the efficacy of such bid manipulation attacks and find that, indeed, they can jeopardize the integrity of the review process. We develop a novel approach for paper bidding and assignment that is much more robust against such attacks. We show empirically that our approach provides robustness even when dishonest reviewers collude, have full knowledge of the assignment system's internal workings, and have access to the system's inputs. In addition to being more robust, the quality of our paper review assignments is comparable to that of current, non-robust assignment approaches.