 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteerEval: A Framework for Evaluating Steerability with Natural Language Profiles for Recommendation
Jan 28, 2026Natural-language user profiles have recently attracted attention not only for improved interpretability, but also for their potential to make recommender systems more steerable. By enabling direct editing, natural-language profiles allow users to explicitly articulate preferences that may be difficult to infer from past behavior. However, it remains unclear whether current natural-language-based recommendation methods can follow such steering commands. While existing steerability evaluations have shown some success for well-recognized item attributes (e.g., movie genres), we argue that these benchmarks fail to capture the richer forms of user control that motivate steerable recommendations. To address this gap, we introduce SteerEval, an evaluation framework designed to measure more nuanced and diverse forms of steerability by using interventions that range from genres to content-warning for movies. We assess the steerability of a family of pretrained natural-language recommenders, examine the potential and limitations of steering on relatively niche topics, and compare how different profile and recommendation interventions impact steering effectiveness. Finally, we offer practical design suggestions informed by our findings and discuss future steps in steerable recommender design.
Do LLMs Favor LLMs? Quantifying Interaction Effects in Peer Review
Jan 28, 2026There are increasing indications that LLMs are not only used for producing scientific papers, but also as part of the peer review process. In this work, we provide the first comprehensive analysis of LLM use across the peer review pipeline, with particular attention to interaction effects: not just whether LLM-assisted papers or LLM-assisted reviews are different in isolation, but whether LLM-assisted reviews evaluate LLM-assisted papers differently. In particular, we analyze over 125,000 paper-review pairs from ICLR, NeurIPS, and ICML. We initially observe what appears to be a systematic interaction effect: LLM-assisted reviews seem especially kind to LLM-assisted papers compared to papers with minimal LLM use. However, controlling for paper quality reveals a different story: LLM-assisted reviews are simply more lenient toward lower quality papers in general, and the over-representation of LLM-assisted papers among weaker submissions creates a spurious interaction effect rather than genuine preferential treatment of LLM-generated content. By augmenting our observational findings with reviews that are fully LLM-generated, we find that fully LLM-generated reviews exhibit severe rating compression that fails to discriminate paper quality, while human reviewers using LLMs substantially reduce this leniency. Finally, examining metareviews, we find that LLM-assisted metareviews are more likely to render accept decisions than human metareviews given equivalent reviewer scores, though fully LLM-generated metareviews tend to be harsher. This suggests that meta-reviewers do not merely outsource the decision-making to the LLM. These findings provide important input for developing policies that govern the use of LLMs during peer review, and they more generally indicate how LLMs interact with existing decision-making processes.
Prompt Optimization with Logged Bandit Data
Apr 03, 2025We study how to use naturally available user feedback, such as clicks, to optimize large language model (LLM) pipelines for generating personalized sentences using prompts. Naive approaches, which estimate the policy gradient in the prompt space, suffer either from variance caused by the large action space of prompts or bias caused by inaccurate reward predictions. To circumvent these challenges, we propose a novel kernel-based off-policy gradient method, which estimates the policy gradient by leveraging similarity among generated sentences, substantially reducing variance while suppressing the bias. Empirical results on our newly established suite of benchmarks demonstrate the effectiveness of the proposed approach in generating personalized descriptions for movie recommendations, particularly when the number of candidate prompts is large.
Poor Alignment and Steerability of Large Language Models: Evidence from College Admission Essays
Mar 25, 2025People are increasingly using technologies equipped with large language models (LLM) to write texts for formal communication, which raises two important questions at the intersection of technology and society: Who do LLMs write like (model alignment); and can LLMs be prompted to change who they write like (model steerability). We investigate these questions in the high-stakes context of undergraduate admissions at a selective university by comparing lexical and sentence variation between essays written by 30,000 applicants to two types of LLM-generated essays: one prompted with only the essay question used by the human applicants; and another with additional demographic information about each applicant. We consistently find that both types of LLM-generated essays are linguistically distinct from human-authored essays, regardless of the specific model and analytical approach. Further, prompting a specific sociodemographic identity is remarkably ineffective in aligning the model with the linguistic patterns observed in human writing from this identity group. This holds along the key dimensions of sex, race, first-generation status, and geographic location. The demographically prompted and unprompted synthetic texts were also more similar to each other than to the human text, meaning that prompting did not alleviate homogenization. These issues of model alignment and steerability in current LLMs raise concerns about the use of LLMs in high-stakes contexts.
End-to-end Training for Recommendation with Language-based User Profiles
Oct 24, 2024



Many online platforms maintain user profiles for personalization. Unfortunately, these profiles are typically not interpretable or easily modifiable by the user. To remedy this shortcoming, we explore natural language-based user profiles, as they promise enhanced transparency and scrutability of recommender systems. While existing work has shown that language-based profiles from standard LLMs can be effective, such generalist LLMs are unlikely to be optimal for this task. In this paper, we introduce LangPTune, the first end-to-end learning method for training LLMs to produce language-based user profiles that optimize recommendation effectiveness. Through comprehensive evaluations of LangPTune across various training configurations and benchmarks, we demonstrate that our approach significantly outperforms existing profile-based methods. In addition, it approaches performance levels comparable to state-of-the-art, less transparent recommender systems, providing a robust and interpretable alternative to conventional systems. Finally, we validate the relative interpretability of these language-based user profiles through user studies involving crowdworkers and GPT-4-based evaluations. Implementation of LangPTune can be found at https://github.com/ZhaolinGao/LangPTune.
REBEL: Reinforcement Learning via Regressing Relative Rewards
Apr 25, 2024While originally developed for continuous control problems, Proximal Policy Optimization (PPO) has emerged as the work-horse of a variety of reinforcement learning (RL) applications including the fine-tuning of generative models. Unfortunately, PPO requires multiple heuristics to enable stable convergence (e.g. value networks, clipping) and is notorious for its sensitivity to the precise implementation of these components. In response, we take a step back and ask what a minimalist RL algorithm for the era of generative models would look like. We propose REBEL, an algorithm that cleanly reduces the problem of policy optimization to regressing the relative rewards via a direct policy parameterization between two completions to a prompt, enabling strikingly lightweight implementation. In theory, we prove that fundamental RL algorithms like Natural Policy Gradient can be seen as variants of REBEL, which allows us to match the strongest known theoretical guarantees in terms of convergence and sample complexity in the RL literature. REBEL can also cleanly incorporate offline data and handle the intransitive preferences we frequently see in practice. Empirically, we find that REBEL provides a unified approach to language modeling and image generation with stronger or similar performance as PPO and DPO, all while being simpler to implement and more computationally tractable than PPO.
Language-Based User Profiles for Recommendation
Feb 23, 2024



Most conventional recommendation methods (e.g., matrix factorization) represent user profiles as high-dimensional vectors. Unfortunately, these vectors lack interpretability and steerability, and often perform poorly in cold-start settings. To address these shortcomings, we explore the use of user profiles that are represented as human-readable text. We propose the Language-based Factorization Model (LFM), which is essentially an encoder/decoder model where both the encoder and the decoder are large language models (LLMs). The encoder LLM generates a compact natural-language profile of the user's interests from the user's rating history. The decoder LLM uses this summary profile to complete predictive downstream tasks. We evaluate our LFM approach on the MovieLens dataset, comparing it against matrix factorization and an LLM model that directly predicts from the user's rating history. In cold-start settings, we find that our method can have higher accuracy than matrix factorization. Furthermore, we find that generating a compact and human-readable summary often performs comparably with or better than direct LLM prediction, while enjoying better interpretability and shorter model input length. Our results motivate a number of future research directions and potential improvements.
Reviewer2: Optimizing Review Generation Through Prompt Generation
Feb 16, 2024Recent developments in LLMs offer new opportunities for assisting authors in improving their work. In this paper, we envision a use case where authors can receive LLM-generated reviews that uncover weak points in the current draft. While initial methods for automated review generation already exist, these methods tend to produce reviews that lack detail, and they do not cover the range of opinions that human reviewers produce. To address this shortcoming, we propose an efficient two-stage review generation framework called Reviewer2. Unlike prior work, this approach explicitly models the distribution of possible aspects that the review may address. We show that this leads to more detailed reviews that better cover the range of aspects that human reviewers identify in the draft. As part of the research, we generate a large-scale review dataset of 27k papers and 99k reviews that we annotate with aspect prompts, which we make available as a resource for future research.
POTEC: Off-Policy Learning for Large Action Spaces via Two-Stage Policy Decomposition
Feb 09, 2024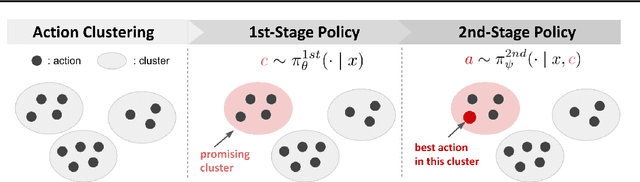

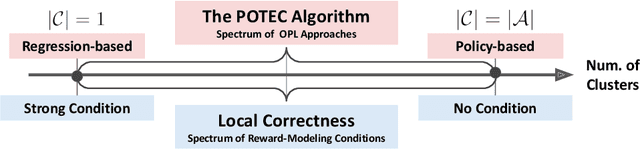

We study off-policy learning (OPL) of contextual bandit policies in large discrete action spaces where existing methods -- most of which rely crucially on reward-regression models or importance-weighted policy gradients -- fail due to excessive bias or variance. To overcome these issues in OPL, we propose a novel two-stage algorithm, called Policy Optimization via Two-Stage Policy Decomposition (POTEC). It leverages clustering in the action space and learns two different policies via policy- and regression-based approaches, respectively. In particular, we derive a novel low-variance gradient estimator that enables to learn a first-stage policy for cluster selection efficiently via a policy-based approach. To select a specific action within the cluster sampled by the first-stage policy, POTEC uses a second-stage policy derived from a regression-based approach within each cluster. We show that a local correctness condition, which only requires that the regression model preserves the relative expected reward differences of the actions within each cluster, ensures that our policy-gradient estimator is unbiased and the second-stage policy is optimal. We also show that POTEC provides a strict generalization of policy- and regression-based approaches and their associated assumptions. Comprehensive experiments demonstrate that POTEC provides substantial improvements in OPL effectiveness particularly in large and structured action spaces.
Unbiased Offline Evaluation for Learning to Rank with Business Rules
Nov 03, 2023
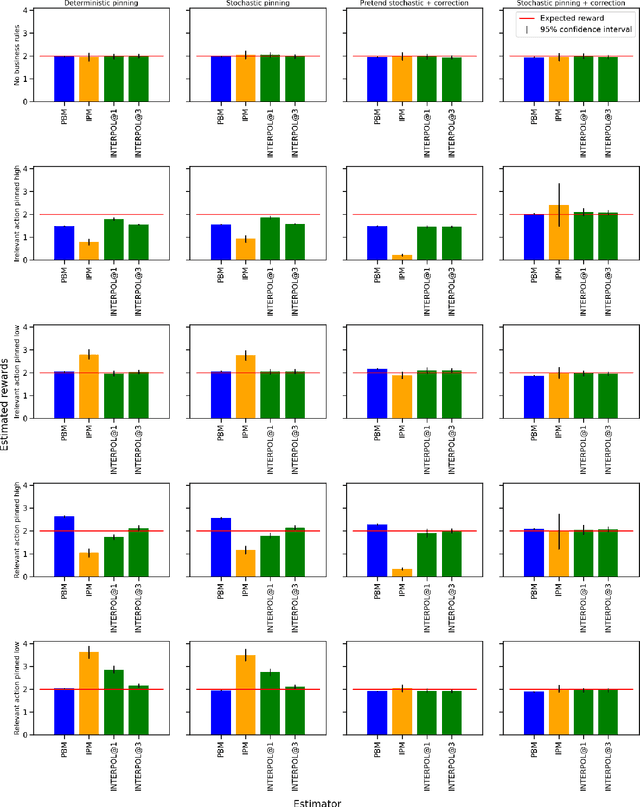

For industrial learning-to-rank (LTR) systems, it is common that the output of a ranking model is modified, either as a results of post-processing logic that enforces business requirements, or as a result of unforeseen design flaws or bugs present in real-world production systems. This poses a challenge for deploying off-policy learning and evaluation methods, as these often rely on the assumption that rankings implied by the model's scores coincide with displayed items to the users. Further requirements for reliable offline evaluation are proper randomization and correct estimation of the propensities of displaying each item in any given position of the ranking, which are also impacted by the aforementioned post-processing. We investigate empirically how these scenarios impair off-policy evaluation for learning-to-rank models. We then propose a novel correction method based on the Birkhoff-von-Neumann decomposition that is robust to this type of post-processing. We obtain more accurate off-policy estimates in offline experiments, overcoming the problem of post-processed rankings. To the best of our knowledge this is the first study on the impact of real-world business rules on offline evaluation of LTR models.