 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models as Recommender Systems: A Study of Popularity Bias
Jun 03, 2024The issue of popularity bias -- where popular items are disproportionately recommended, overshadowing less popular but potentially relevant items -- remains a significant challenge in recommender systems. Recent advancements have seen the integration of general-purpose Large Language Models (LLMs) into the architecture of such systems. This integration raises concerns that it might exacerbate popularity bias, given that the LLM's training data is likely dominated by popular items. However, it simultaneously presents a novel opportunity to address the bias via prompt tuning. Our study explores this dichotomy, examining whether LLMs contribute to or can alleviate popularity bias in recommender systems. We introduce a principled way to measure popularity bias by discussing existing metrics and proposing a novel metric that fulfills a series of desiderata. Based on our new metric, we compare a simple LLM-based recommender to traditional recommender systems on a movie recommendation task. We find that the LLM recommender exhibits less popularity bias, even without any explicit mitigation.
Unbiased Offline Evaluation for Learning to Rank with Business Rules
Nov 03, 2023
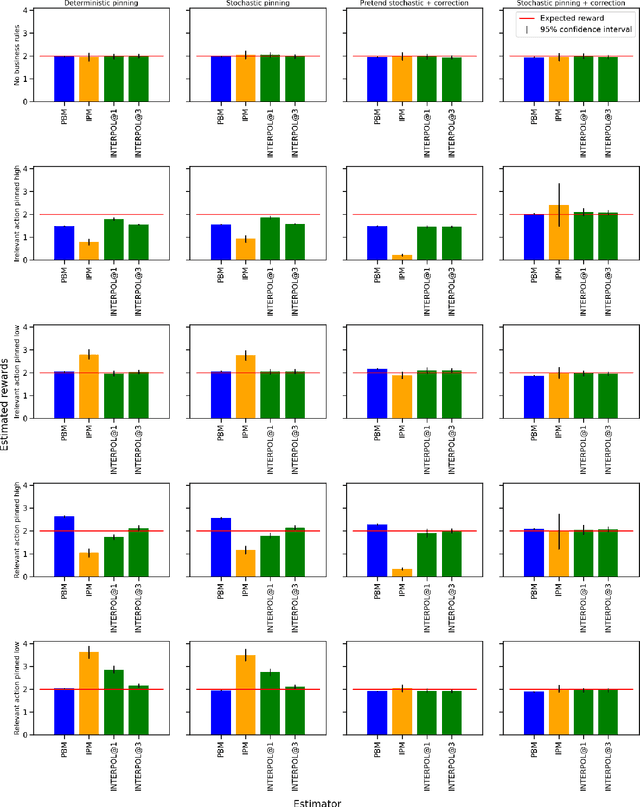

For industrial learning-to-rank (LTR) systems, it is common that the output of a ranking model is modified, either as a results of post-processing logic that enforces business requirements, or as a result of unforeseen design flaws or bugs present in real-world production systems. This poses a challenge for deploying off-policy learning and evaluation methods, as these often rely on the assumption that rankings implied by the model's scores coincide with displayed items to the users. Further requirements for reliable offline evaluation are proper randomization and correct estimation of the propensities of displaying each item in any given position of the ranking, which are also impacted by the aforementioned post-processing. We investigate empirically how these scenarios impair off-policy evaluation for learning-to-rank models. We then propose a novel correction method based on the Birkhoff-von-Neumann decomposition that is robust to this type of post-processing. We obtain more accurate off-policy estimates in offline experiments, overcoming the problem of post-processed rankings. To the best of our knowledge this is the first study on the impact of real-world business rules on offline evaluation of LTR models.
Double Clipping: Less-Biased Variance Reduction in Off-Policy Evaluation
Sep 03, 2023
"Clipping" (a.k.a. importance weight truncation) is a widely used variance-reduction technique for counterfactual off-policy estimators. Like other variance-reduction techniques, clipping reduces variance at the cost of increased bias. However, unlike other techniques, the bias introduced by clipping is always a downward bias (assuming non-negative rewards), yielding a lower bound on the true expected reward. In this work we propose a simple extension, called $\textit{double clipping}$, which aims to compensate this downward bias and thus reduce the overall bias, while maintaining the variance reduction properties of the original estimator.
Fair Effect Attribution in Parallel Online Experiments
Oct 15, 2022

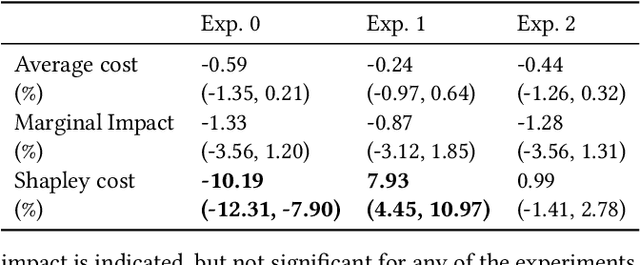
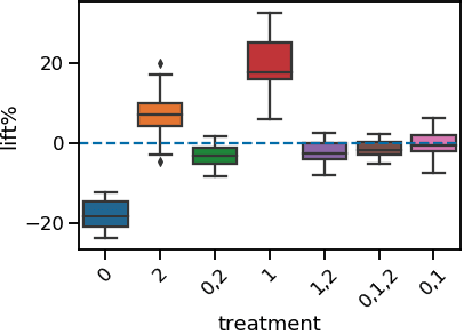
A/B tests serve the purpose of reliably identifying the effect of changes introduced in online services. It is common for online platforms to run a large number of simultaneous experiments by splitting incoming user traffic randomly in treatment and control groups. Despite a perfect randomization between different groups, simultaneous experiments can interact with each other and create a negative impact on average population outcomes such as engagement metrics. These are measured globally and monitored to protect overall user experience. Therefore, it is crucial to measure these interaction effects and attribute their overall impact in a fair way to the respective experimenters. We suggest an approach to measure and disentangle the effect of simultaneous experiments by providing a cost sharing approach based on Shapley values. We also provide a counterfactual perspective, that predicts shared impact based on conditional average treatment effects making use of causal inference techniques. We illustrate our approach in real world and synthetic data experiments.
* Published as https://dl.acm.org/doi/10.1145/3487553.3524211
Off-policy evaluation for learning-to-rank via interpolating the item-position model and the position-based model
Oct 15, 2022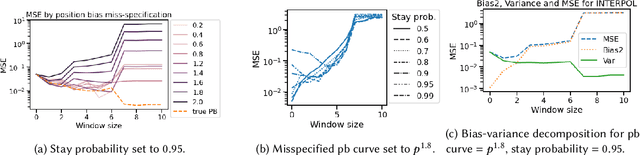
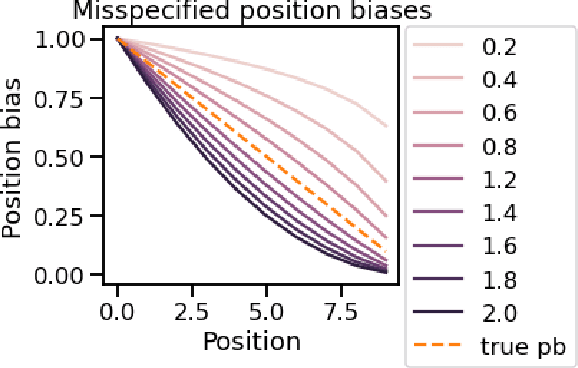
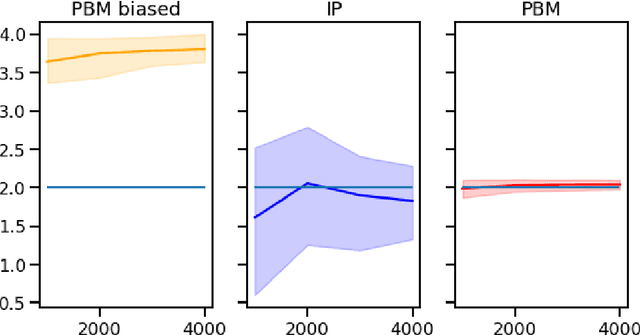
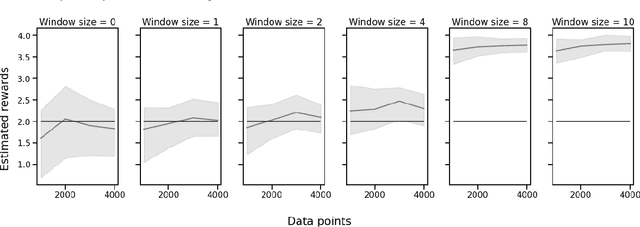
A critical need for industrial recommender systems is the ability to evaluate recommendation policies offline, before deploying them to production. Unfortunately, widely used off-policy evaluation methods either make strong assumptions about how users behave that can lead to excessive bias, or they make fewer assumptions and suffer from large variance. We tackle this problem by developing a new estimator that mitigates the problems of the two most popular off-policy estimators for rankings, namely the position-based model and the item-position model. In particular, the new estimator, called INTERPOL, addresses the bias of a potentially misspecified position-based model, while providing an adaptable bias-variance trade-off compared to the item-position model. We provide theoretical arguments as well as empirical results that highlight the performance of our novel estimation approach.
Low-variance estimation in the Plackett-Luce model via quasi-Monte Carlo sampling
May 12, 2022
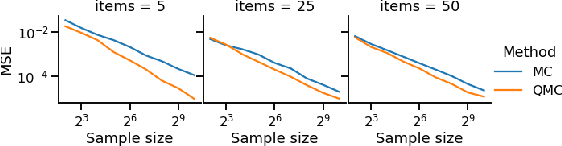
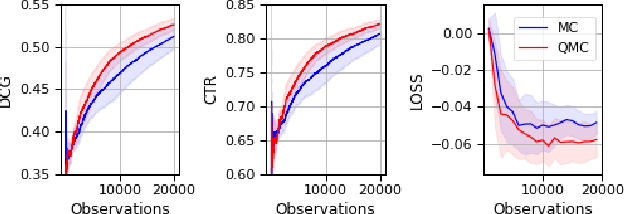

The Plackett-Luce (PL) model is ubiquitous in learning-to-rank (LTR) because it provides a useful and intuitive probabilistic model for sampling ranked lists. Counterfactual offline evaluation and optimization of ranking metrics are pivotal for using LTR methods in production. When adopting the PL model as a ranking policy, both tasks require the computation of expectations with respect to the model. These are usually approximated via Monte-Carlo (MC) sampling, since the combinatorial scaling in the number of items to be ranked makes their analytical computation intractable. Despite recent advances in improving the computational efficiency of the sampling process via the Gumbel top-k trick, the MC estimates can suffer from high variance. We develop a novel approach to producing more sample-efficient estimators of expectations in the PL model by combining the Gumbel top-k trick with quasi-Monte Carlo (QMC) sampling, a well-established technique for variance reduction. We illustrate our findings both theoretically and empirically using real-world recommendation data from Amazon Music and the Yahoo learning-to-rank challenge.
Ranker-agnostic Contextual Position Bias Estimation
Jul 28, 2021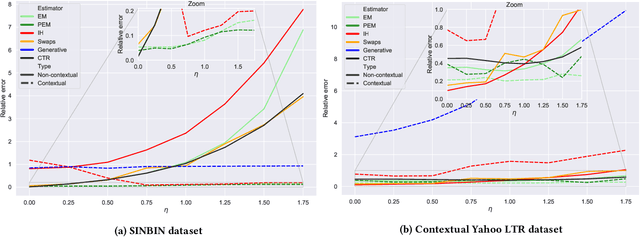

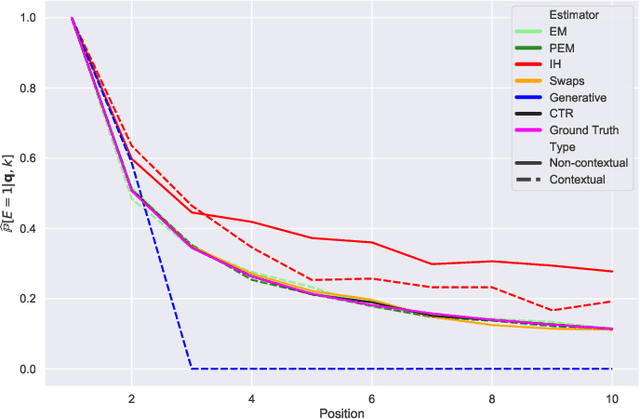

Learning-to-rank (LTR) algorithms are ubiquitous and necessary to explore the extensive catalogs of media providers. To avoid the user examining all the results, its preferences are used to provide a subset of relatively small size. The user preferences can be inferred from the interactions with the presented content if explicit ratings are unavailable. However, directly using implicit feedback can lead to learning wrong relevance models and is known as biased LTR. The mismatch between implicit feedback and true relevances is due to various nuisances, with position bias one of the most relevant. Position bias models consider that the lack of interaction with a presented item is not only attributed to the item being irrelevant but because the item was not examined. This paper introduces a method for modeling the probability of an item being seen in different contexts, e.g., for different users, with a single estimator. Our suggested method, denoted as contextual (EM)-based regression, is ranker-agnostic and able to correctly learn the latent examination probabilities while only using implicit feedback. Our empirical results indicate that the method introduced in this paper outperforms other existing position bias estimators in terms of relative error when the examination probability varies across queries. Moreover, the estimated values provide a ranking performance boost when used to debias the implicit ranking data even if there is no context dependency on the examination probabilities.
Distributed Bayesian Computation for Model Choice
Oct 10, 2019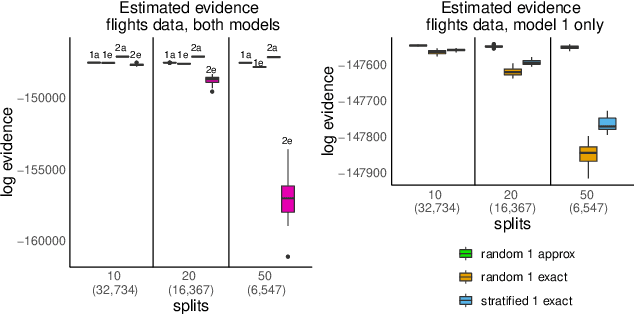
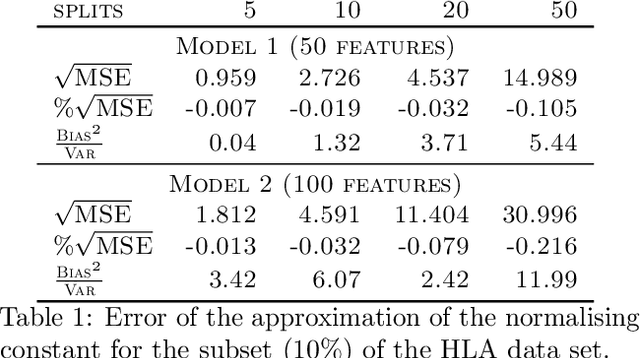
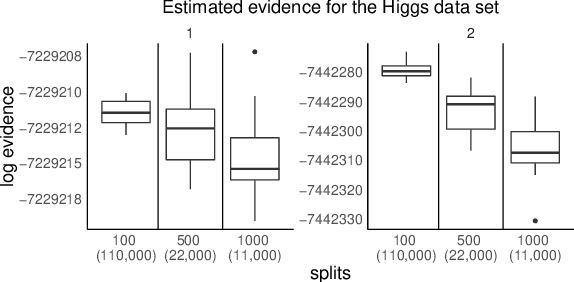
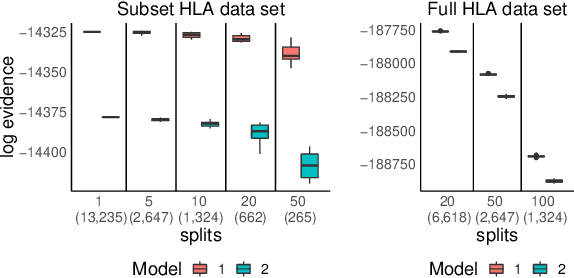
We propose a general method for distributed Bayesian model choice, where each worker has access only to non-overlapping subsets of the data. Our approach approximates the model evidence for the full data set through Monte Carlo sampling from the posterior on every subset generating a model evidence per subset. The model evidences per worker are then consistently combined using a novel approach which corrects for the splitting using summary statistics of the generated samples. This divide-and-conquer approach allows Bayesian model choice in the large data setting, exploiting all available information but limiting communication between workers. Our work thereby complements the work on consensus Monte Carlo (Scott et al., 2016) by explicitly enabling model choice. In addition, we show how the suggested approach can be extended to model choice within a reversible jump setting that explores multiple models within one run.
Quasi-Monte Carlo Variational Inference
Jul 04, 2018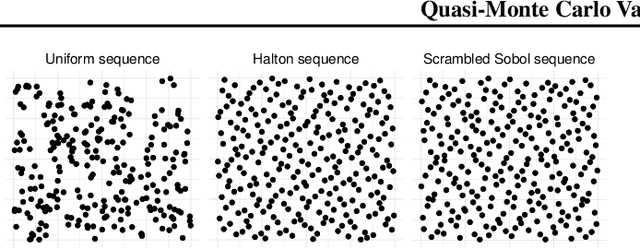

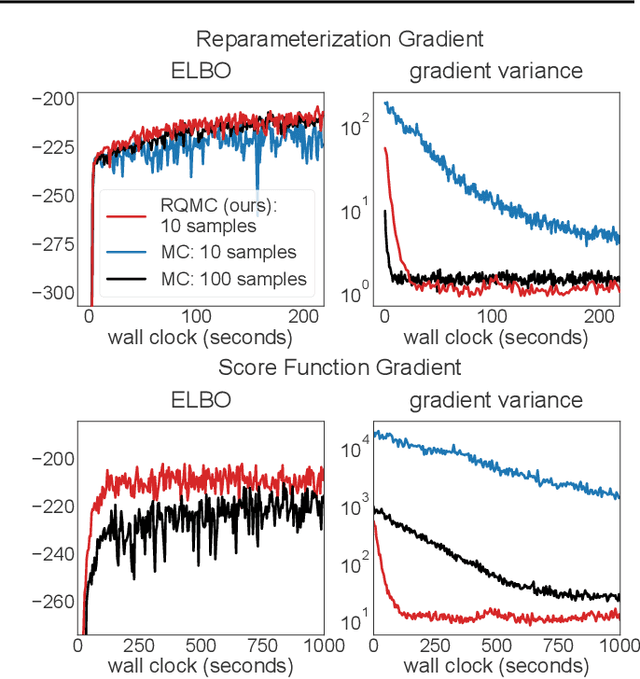
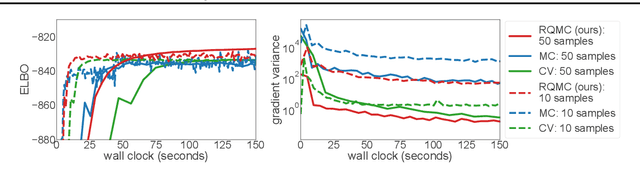
Many machine learning problems involve Monte Carlo gradient estimators. As a prominent example, we focus on Monte Carlo variational inference (MCVI) in this paper. The performance of MCVI crucially depends on the variance of its stochastic gradients. We propose variance reduction by means of Quasi-Monte Carlo (QMC) sampling. QMC replaces N i.i.d. samples from a uniform probability distribution by a deterministic sequence of samples of length N. This sequence covers the underlying random variable space more evenly than i.i.d. draws, reducing the variance of the gradient estimator. With our novel approach, both the score function and the reparameterization gradient estimators lead to much faster convergence. We also propose a new algorithm for Monte Carlo objectives, where we operate with a constant learning rate and increase the number of QMC samples per iteration. We prove that this way, our algorithm can converge asymptotically at a faster rate than SGD. We furthermore provide theoretical guarantees on QMC for Monte Carlo objectives that go beyond MCVI, and support our findings by several experiments on large-scale data sets from various domains.