 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRanking Across Different Content Types: The Robust Beauty of Multinomial Blending
Aug 17, 2024


An increasing number of media streaming services have expanded their offerings to include entities of multiple content types. For instance, audio streaming services that started by offering music only, now also offer podcasts, merchandise items, and videos. Ranking items across different content types into a single slate poses a significant challenge for traditional learning-to-rank (LTR) algorithms due to differing user engagement patterns for different content types. We explore a simple method for cross-content-type ranking, called multinomial blending (MB), which can be used in conjunction with most existing LTR algorithms. We compare MB to existing baselines not only in terms of ranking quality but also from other industry-relevant perspectives such as interpretability, ease-of-use, and stability in dynamic environments with changing user behavior and ranking model retraining. Finally, we report the results of an A/B test from an Amazon Music ranking use-case.
Double Clipping: Less-Biased Variance Reduction in Off-Policy Evaluation
Sep 03, 2023
"Clipping" (a.k.a. importance weight truncation) is a widely used variance-reduction technique for counterfactual off-policy estimators. Like other variance-reduction techniques, clipping reduces variance at the cost of increased bias. However, unlike other techniques, the bias introduced by clipping is always a downward bias (assuming non-negative rewards), yielding a lower bound on the true expected reward. In this work we propose a simple extension, called $\textit{double clipping}$, which aims to compensate this downward bias and thus reduce the overall bias, while maintaining the variance reduction properties of the original estimator.
Fair Effect Attribution in Parallel Online Experiments
Oct 15, 2022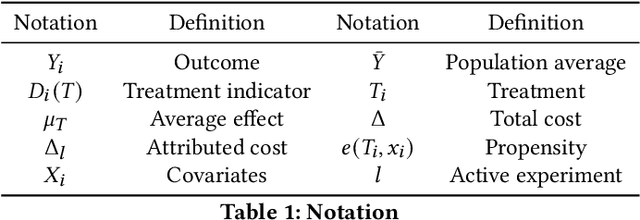

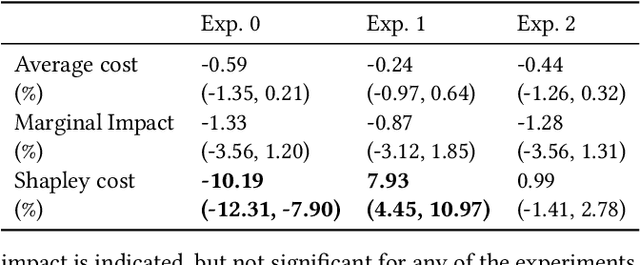
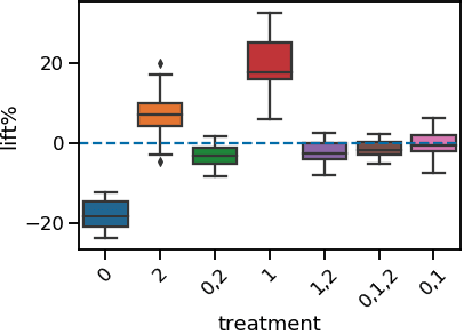
A/B tests serve the purpose of reliably identifying the effect of changes introduced in online services. It is common for online platforms to run a large number of simultaneous experiments by splitting incoming user traffic randomly in treatment and control groups. Despite a perfect randomization between different groups, simultaneous experiments can interact with each other and create a negative impact on average population outcomes such as engagement metrics. These are measured globally and monitored to protect overall user experience. Therefore, it is crucial to measure these interaction effects and attribute their overall impact in a fair way to the respective experimenters. We suggest an approach to measure and disentangle the effect of simultaneous experiments by providing a cost sharing approach based on Shapley values. We also provide a counterfactual perspective, that predicts shared impact based on conditional average treatment effects making use of causal inference techniques. We illustrate our approach in real world and synthetic data experiments.
* Published as https://dl.acm.org/doi/10.1145/3487553.3524211
Low-variance estimation in the Plackett-Luce model via quasi-Monte Carlo sampling
May 12, 2022
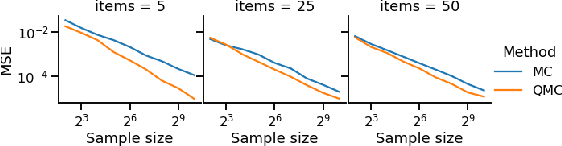
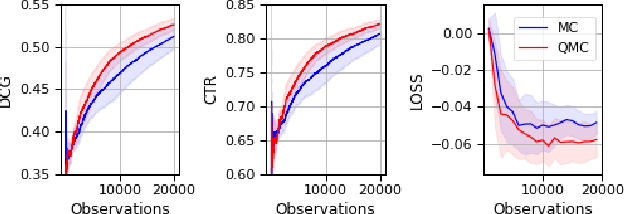

The Plackett-Luce (PL) model is ubiquitous in learning-to-rank (LTR) because it provides a useful and intuitive probabilistic model for sampling ranked lists. Counterfactual offline evaluation and optimization of ranking metrics are pivotal for using LTR methods in production. When adopting the PL model as a ranking policy, both tasks require the computation of expectations with respect to the model. These are usually approximated via Monte-Carlo (MC) sampling, since the combinatorial scaling in the number of items to be ranked makes their analytical computation intractable. Despite recent advances in improving the computational efficiency of the sampling process via the Gumbel top-k trick, the MC estimates can suffer from high variance. We develop a novel approach to producing more sample-efficient estimators of expectations in the PL model by combining the Gumbel top-k trick with quasi-Monte Carlo (QMC) sampling, a well-established technique for variance reduction. We illustrate our findings both theoretically and empirically using real-world recommendation data from Amazon Music and the Yahoo learning-to-rank challenge.
Ranker-agnostic Contextual Position Bias Estimation
Jul 28, 2021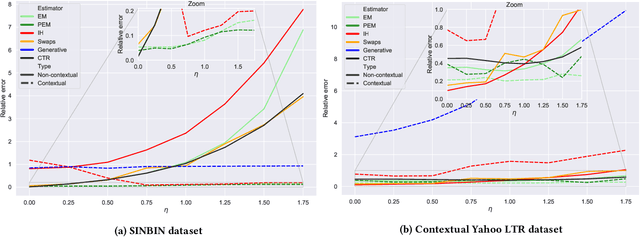

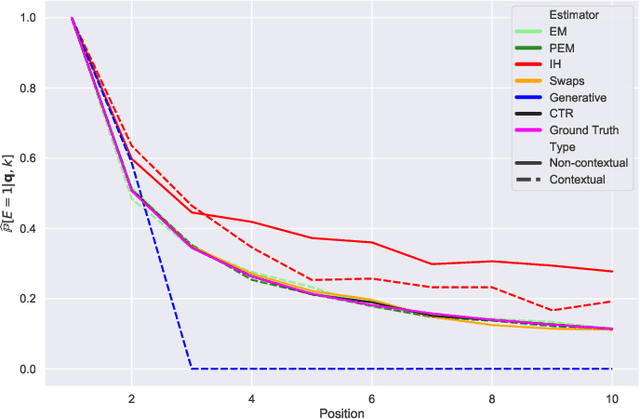

Learning-to-rank (LTR) algorithms are ubiquitous and necessary to explore the extensive catalogs of media providers. To avoid the user examining all the results, its preferences are used to provide a subset of relatively small size. The user preferences can be inferred from the interactions with the presented content if explicit ratings are unavailable. However, directly using implicit feedback can lead to learning wrong relevance models and is known as biased LTR. The mismatch between implicit feedback and true relevances is due to various nuisances, with position bias one of the most relevant. Position bias models consider that the lack of interaction with a presented item is not only attributed to the item being irrelevant but because the item was not examined. This paper introduces a method for modeling the probability of an item being seen in different contexts, e.g., for different users, with a single estimator. Our suggested method, denoted as contextual (EM)-based regression, is ranker-agnostic and able to correctly learn the latent examination probabilities while only using implicit feedback. Our empirical results indicate that the method introduced in this paper outperforms other existing position bias estimators in terms of relative error when the examination probability varies across queries. Moreover, the estimated values provide a ranking performance boost when used to debias the implicit ranking data even if there is no context dependency on the examination probabilities.
Hierarchical Methods of Moments
Oct 17, 2018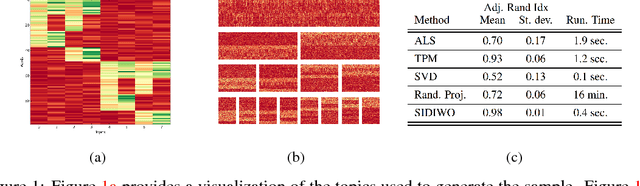
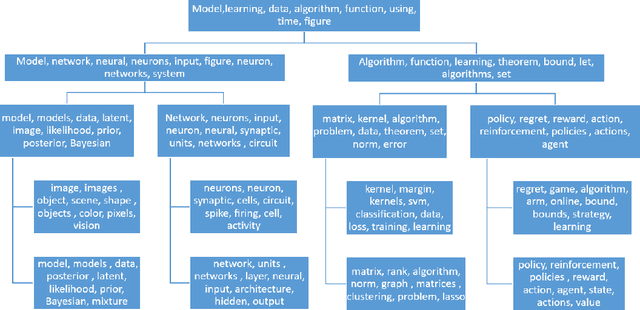
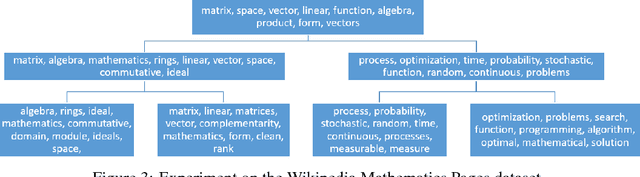
Spectral methods of moments provide a powerful tool for learning the parameters of latent variable models. Despite their theoretical appeal, the applicability of these methods to real data is still limited due to a lack of robustness to model misspecification. In this paper we present a hierarchical approach to methods of moments to circumvent such limitations. Our method is based on replacing the tensor decomposition step used in previous algorithms with approximate joint diagonalization. Experiments on topic modeling show that our method outperforms previous tensor decomposition methods in terms of speed and model quality.
Generating Synthetic but Plausible Healthcare Record Datasets
Jul 04, 2018
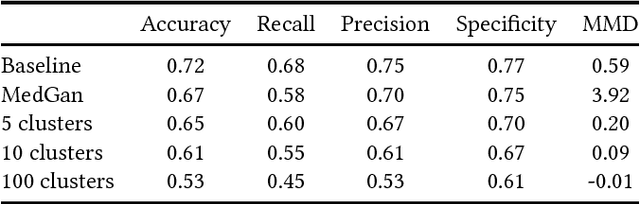
Generating datasets that "look like" given real ones is an interesting tasks for healthcare applications of ML and many other fields of science and engineering. In this paper we propose a new method of general application to binary datasets based on a method for learning the parameters of a latent variable moment that we have previously used for clustering patient datasets. We compare our method with a recent proposal (MedGan) based on generative adversarial methods and find that the synthetic datasets we generate are globally more realistic in at least two senses: real and synthetic instances are harder to tell apart by Random Forests, and the MMD statistic. The most likely explanation is that our method does not suffer from the "mode collapse" which is an admitted problem of GANs. Additionally, the generative models we generate are easy to interpret, unlike the rather obscure GANs. Our experiments are performed on two patient datasets containing ICD-9 diagnostic codes: the publicly available MIMIC-III dataset and a dataset containing admissions for congestive heart failure during 7 years at Hospital de Sant Pau in Barcelona.
Clustering Patients with Tensor Decomposition
Aug 29, 2017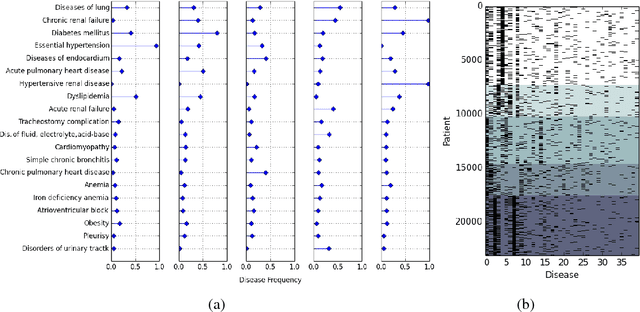



In this paper we present a method for the unsupervised clustering of high-dimensional binary data, with a special focus on electronic healthcare records. We present a robust and efficient heuristic to face this problem using tensor decomposition. We present the reasons why this approach is preferable for tasks such as clustering patient records, to more commonly used distance-based methods. We run the algorithm on two datasets of healthcare records, obtaining clinically meaningful results.
A New Spectral Method for Latent Variable Models
Apr 04, 2017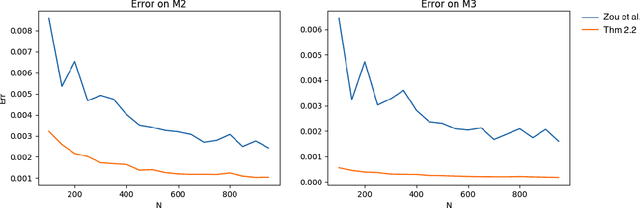

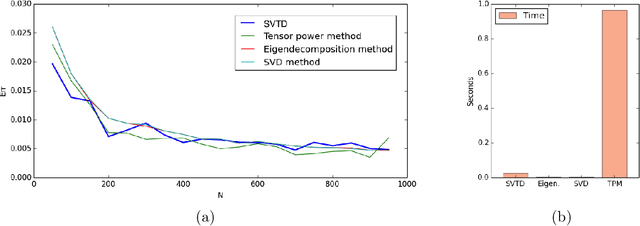

This paper presents an algorithm for the unsupervised learning of latent variable models from unlabeled sets of data. We base our technique on spectral decomposition, providing a technique that proves to be robust both in theory and in practice. We also describe how to use this algorithm to learn the parameters of two well known text mining models: single topic model and Latent Dirichlet Allocation, providing in both cases an efficient technique to retrieve the parameters to feed the algorithm. We compare the results of our algorithm with those of existing algorithms on synthetic data, and we provide examples of applications to real world text corpora for both single topic model and LDA, obtaining meaningful results.