 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Recommendations with User Popularity Preferences
Apr 01, 2026Popularity bias is a pervasive problem in recommender systems, where recommendations disproportionately favor popular items. This not only results in "rich-get-richer" dynamics and a homogenization of visible content, but can also lead to misalignment of recommendations with individual users' preferences for popular or niche content. This work studies popularity bias through the lens of user-recommender alignment. To this end, we introduce Popularity Quantile Calibration, a measurement framework that quantifies misalignment between a user's historical popularity preference and the popularity of their recommendations. Building on this notion of popularity alignment, we propose SPREE, an inference-time mitigation method for sequential recommenders based on activation steering. SPREE identifies a popularity direction in representation space and adaptively steers model activations based on an estimate of each user's personal popularity bias, allowing both the direction and magnitude of steering to vary across users. Unlike global debiasing approaches, SPREE explicitly targets alignment rather than uniformly reducing popularity. Experiments across multiple datasets show that SPREE consistently improves user-level popularity alignment while preserving recommendation quality.
Ranking Across Different Content Types: The Robust Beauty of Multinomial Blending
Aug 17, 2024


An increasing number of media streaming services have expanded their offerings to include entities of multiple content types. For instance, audio streaming services that started by offering music only, now also offer podcasts, merchandise items, and videos. Ranking items across different content types into a single slate poses a significant challenge for traditional learning-to-rank (LTR) algorithms due to differing user engagement patterns for different content types. We explore a simple method for cross-content-type ranking, called multinomial blending (MB), which can be used in conjunction with most existing LTR algorithms. We compare MB to existing baselines not only in terms of ranking quality but also from other industry-relevant perspectives such as interpretability, ease-of-use, and stability in dynamic environments with changing user behavior and ranking model retraining. Finally, we report the results of an A/B test from an Amazon Music ranking use-case.
Double Clipping: Less-Biased Variance Reduction in Off-Policy Evaluation
Sep 03, 2023
"Clipping" (a.k.a. importance weight truncation) is a widely used variance-reduction technique for counterfactual off-policy estimators. Like other variance-reduction techniques, clipping reduces variance at the cost of increased bias. However, unlike other techniques, the bias introduced by clipping is always a downward bias (assuming non-negative rewards), yielding a lower bound on the true expected reward. In this work we propose a simple extension, called $\textit{double clipping}$, which aims to compensate this downward bias and thus reduce the overall bias, while maintaining the variance reduction properties of the original estimator.
Fair Effect Attribution in Parallel Online Experiments
Oct 15, 2022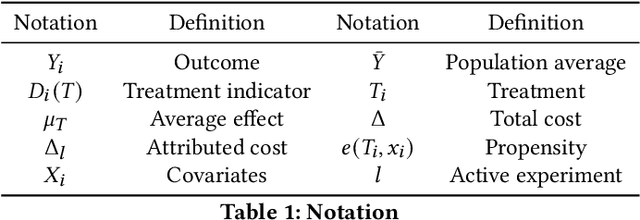

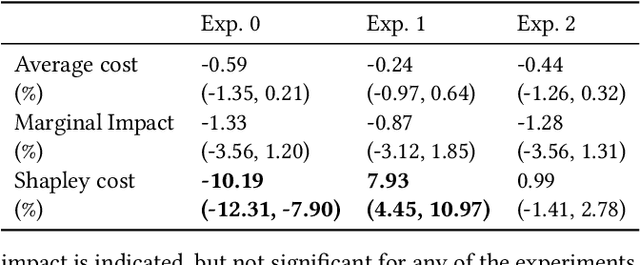
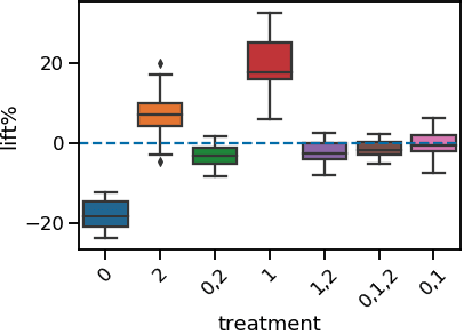
A/B tests serve the purpose of reliably identifying the effect of changes introduced in online services. It is common for online platforms to run a large number of simultaneous experiments by splitting incoming user traffic randomly in treatment and control groups. Despite a perfect randomization between different groups, simultaneous experiments can interact with each other and create a negative impact on average population outcomes such as engagement metrics. These are measured globally and monitored to protect overall user experience. Therefore, it is crucial to measure these interaction effects and attribute their overall impact in a fair way to the respective experimenters. We suggest an approach to measure and disentangle the effect of simultaneous experiments by providing a cost sharing approach based on Shapley values. We also provide a counterfactual perspective, that predicts shared impact based on conditional average treatment effects making use of causal inference techniques. We illustrate our approach in real world and synthetic data experiments.
* Published as https://dl.acm.org/doi/10.1145/3487553.3524211
Low-variance estimation in the Plackett-Luce model via quasi-Monte Carlo sampling
May 12, 2022
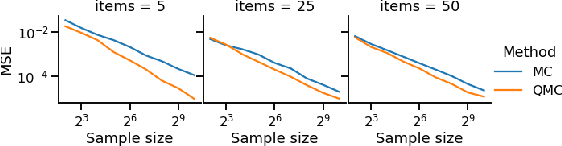
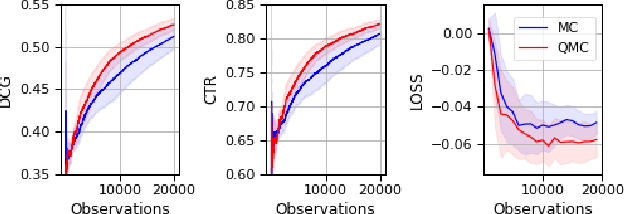

The Plackett-Luce (PL) model is ubiquitous in learning-to-rank (LTR) because it provides a useful and intuitive probabilistic model for sampling ranked lists. Counterfactual offline evaluation and optimization of ranking metrics are pivotal for using LTR methods in production. When adopting the PL model as a ranking policy, both tasks require the computation of expectations with respect to the model. These are usually approximated via Monte-Carlo (MC) sampling, since the combinatorial scaling in the number of items to be ranked makes their analytical computation intractable. Despite recent advances in improving the computational efficiency of the sampling process via the Gumbel top-k trick, the MC estimates can suffer from high variance. We develop a novel approach to producing more sample-efficient estimators of expectations in the PL model by combining the Gumbel top-k trick with quasi-Monte Carlo (QMC) sampling, a well-established technique for variance reduction. We illustrate our findings both theoretically and empirically using real-world recommendation data from Amazon Music and the Yahoo learning-to-rank challenge.
Ranker-agnostic Contextual Position Bias Estimation
Jul 28, 2021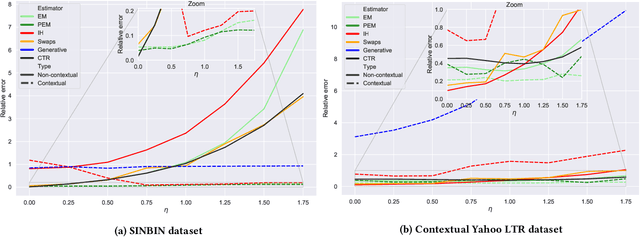

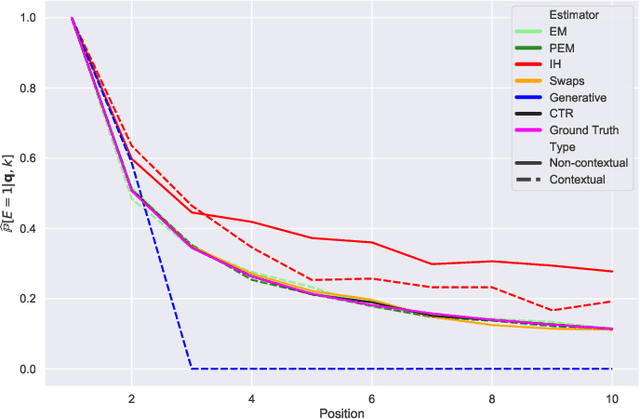

Learning-to-rank (LTR) algorithms are ubiquitous and necessary to explore the extensive catalogs of media providers. To avoid the user examining all the results, its preferences are used to provide a subset of relatively small size. The user preferences can be inferred from the interactions with the presented content if explicit ratings are unavailable. However, directly using implicit feedback can lead to learning wrong relevance models and is known as biased LTR. The mismatch between implicit feedback and true relevances is due to various nuisances, with position bias one of the most relevant. Position bias models consider that the lack of interaction with a presented item is not only attributed to the item being irrelevant but because the item was not examined. This paper introduces a method for modeling the probability of an item being seen in different contexts, e.g., for different users, with a single estimator. Our suggested method, denoted as contextual (EM)-based regression, is ranker-agnostic and able to correctly learn the latent examination probabilities while only using implicit feedback. Our empirical results indicate that the method introduced in this paper outperforms other existing position bias estimators in terms of relative error when the examination probability varies across queries. Moreover, the estimated values provide a ranking performance boost when used to debias the implicit ranking data even if there is no context dependency on the examination probabilities.
A Linear Bandit for Seasonal Environments
Apr 28, 2020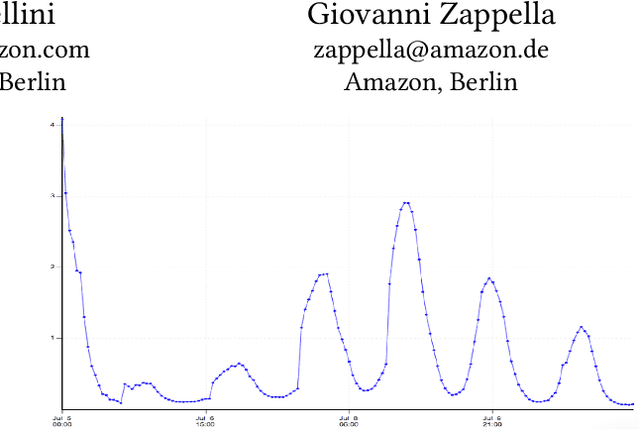
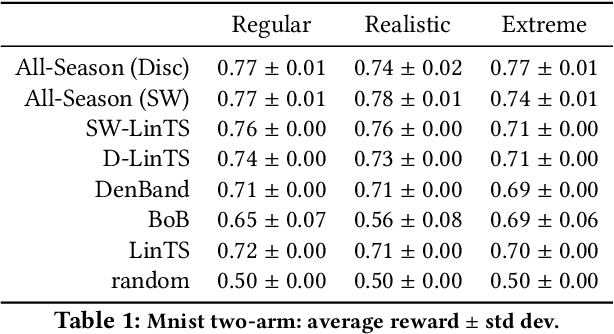
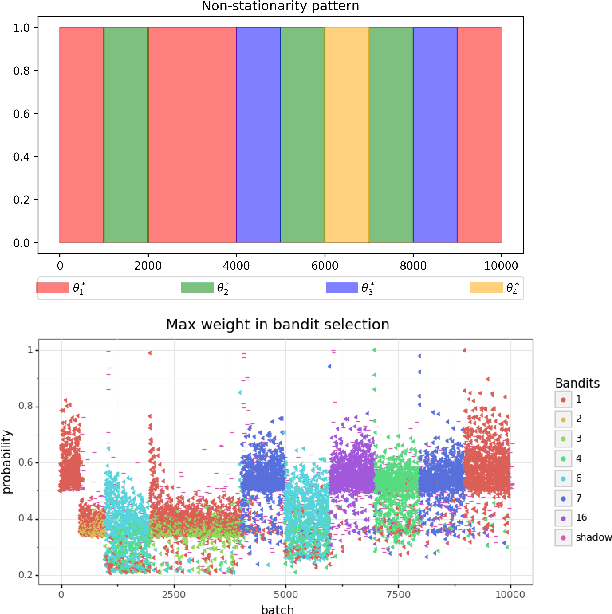
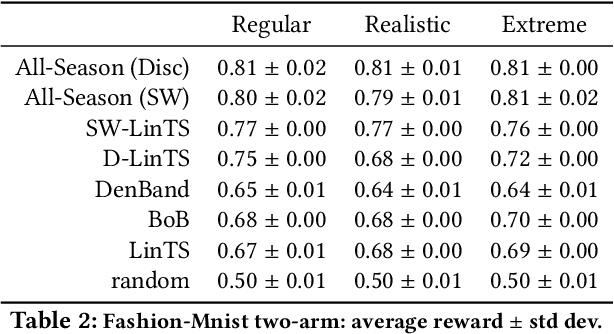
Contextual bandit algorithms are extremely popular and widely used in recommendation systems to provide online personalised recommendations. A recurrent assumption is the stationarity of the reward function, which is rather unrealistic in most of the real-world applications. In the music recommendation scenario for instance, people's music taste can abruptly change during certain events, such as Halloween or Christmas, and revert to the previous music taste soon after. We would therefore need an algorithm which can promptly react to these changes. Moreover, we would like to leverage already observed rewards collected during different stationary periods which can potentially reoccur, without the need of restarting the learning process from scratch. A growing literature has addressed the problem of reward's non-stationarity, providing algorithms that could quickly adapt to the changing environment. However, up to our knowledge, there is no algorithm which deals with seasonal changes of the reward function. Here we present a contextual bandit algorithm which detects and adapts to abrupt changes of the reward function and leverages previous estimations whenever the environment falls back to a previously observed state. We show that the proposed method can outperform state-of-the-art algorithms for non-stationary environments. We ran our experiment on both synthetic and real datasets.
Non-exchangeable feature allocation models with sublinear growth of the feature sizes
Mar 30, 2020

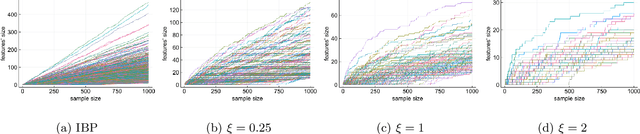
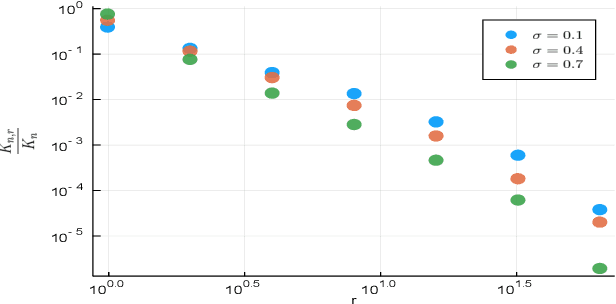
Feature allocation models are popular models used in different applications such as unsupervised learning or network modeling. In particular, the Indian buffet process is a flexible and simple one-parameter feature allocation model where the number of features grows unboundedly with the number of objects. The Indian buffet process, like most feature allocation models, satisfies a symmetry property of exchangeability: the distribution is invariant under permutation of the objects. While this property is desirable in some cases, it has some strong implications. Importantly, the number of objects sharing a particular feature grows linearly with the number of objects. In this article, we describe a class of non-exchangeable feature allocation models where the number of objects sharing a given feature grows sublinearly, where the rate can be controlled by a tuning parameter. We derive the asymptotic properties of the model, and show that such model provides a better fit and better predictive performances on various datasets.
Non-exchangeable random partition models for microclustering
Nov 20, 2017

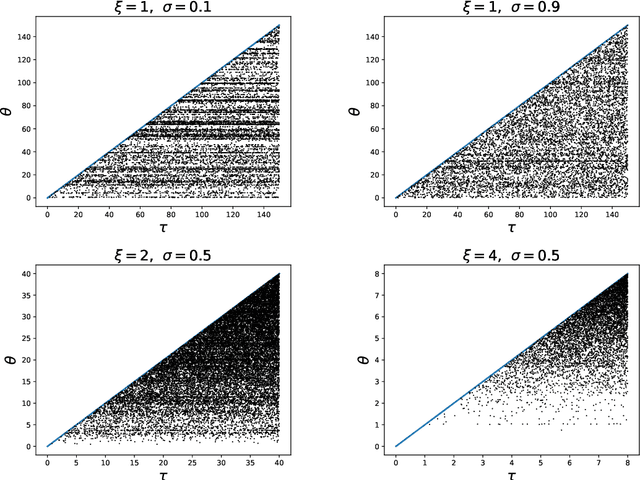
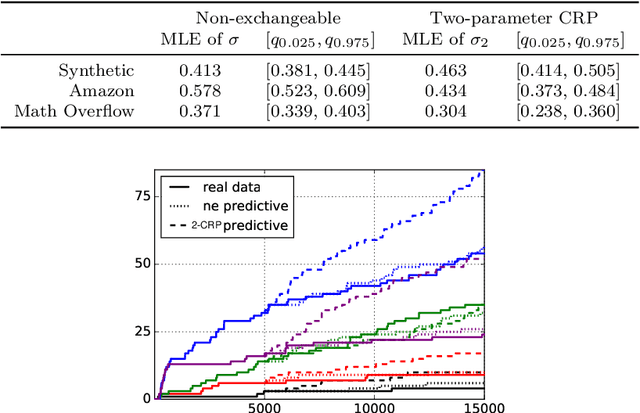
Many popular random partition models, such as the Chinese restaurant process and its two-parameter extension, fall in the class of exchangeable random partitions, and have found wide applicability in model-based clustering, population genetics, ecology or network analysis. While the exchangeability assumption is sensible in many cases, it has some strong implications. In particular, Kingman's representation theorem implies that the size of the clusters necessarily grows linearly with the sample size; this feature may be undesirable for some applications, as recently pointed out by Miller et al. (2015). We present here a flexible class of non-exchangeable random partition models which are able to generate partitions whose cluster sizes grow sublinearly with the sample size, and where the growth rate is controlled by one parameter. Along with this result, we provide the asymptotic behaviour of the number of clusters of a given size, and show that the model can exhibit a power-law behavior, controlled by another parameter. The construction is based on completely random measures and a Poisson embedding of the random partition, and inference is performed using a Sequential Monte Carlo algorithm. Additionally, we show how the model can also be directly used to generate sparse multigraphs with power-law degree distributions and degree sequences with sublinear growth. Finally, experiments on real datasets emphasize the usefulness of the approach compared to a two-parameter Chinese restaurant process.