 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRanking Across Different Content Types: The Robust Beauty of Multinomial Blending
Aug 17, 2024


An increasing number of media streaming services have expanded their offerings to include entities of multiple content types. For instance, audio streaming services that started by offering music only, now also offer podcasts, merchandise items, and videos. Ranking items across different content types into a single slate poses a significant challenge for traditional learning-to-rank (LTR) algorithms due to differing user engagement patterns for different content types. We explore a simple method for cross-content-type ranking, called multinomial blending (MB), which can be used in conjunction with most existing LTR algorithms. We compare MB to existing baselines not only in terms of ranking quality but also from other industry-relevant perspectives such as interpretability, ease-of-use, and stability in dynamic environments with changing user behavior and ranking model retraining. Finally, we report the results of an A/B test from an Amazon Music ranking use-case.
Large Language Models as Recommender Systems: A Study of Popularity Bias
Jun 03, 2024The issue of popularity bias -- where popular items are disproportionately recommended, overshadowing less popular but potentially relevant items -- remains a significant challenge in recommender systems. Recent advancements have seen the integration of general-purpose Large Language Models (LLMs) into the architecture of such systems. This integration raises concerns that it might exacerbate popularity bias, given that the LLM's training data is likely dominated by popular items. However, it simultaneously presents a novel opportunity to address the bias via prompt tuning. Our study explores this dichotomy, examining whether LLMs contribute to or can alleviate popularity bias in recommender systems. We introduce a principled way to measure popularity bias by discussing existing metrics and proposing a novel metric that fulfills a series of desiderata. Based on our new metric, we compare a simple LLM-based recommender to traditional recommender systems on a movie recommendation task. We find that the LLM recommender exhibits less popularity bias, even without any explicit mitigation.
Double Clipping: Less-Biased Variance Reduction in Off-Policy Evaluation
Sep 03, 2023
"Clipping" (a.k.a. importance weight truncation) is a widely used variance-reduction technique for counterfactual off-policy estimators. Like other variance-reduction techniques, clipping reduces variance at the cost of increased bias. However, unlike other techniques, the bias introduced by clipping is always a downward bias (assuming non-negative rewards), yielding a lower bound on the true expected reward. In this work we propose a simple extension, called $\textit{double clipping}$, which aims to compensate this downward bias and thus reduce the overall bias, while maintaining the variance reduction properties of the original estimator.
Low-variance estimation in the Plackett-Luce model via quasi-Monte Carlo sampling
May 12, 2022
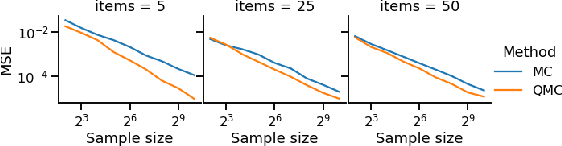
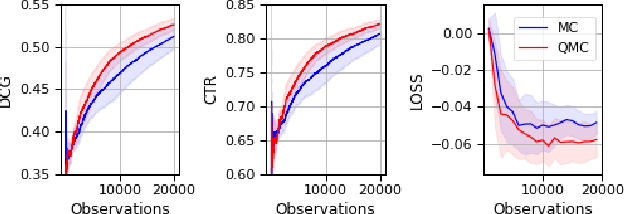

The Plackett-Luce (PL) model is ubiquitous in learning-to-rank (LTR) because it provides a useful and intuitive probabilistic model for sampling ranked lists. Counterfactual offline evaluation and optimization of ranking metrics are pivotal for using LTR methods in production. When adopting the PL model as a ranking policy, both tasks require the computation of expectations with respect to the model. These are usually approximated via Monte-Carlo (MC) sampling, since the combinatorial scaling in the number of items to be ranked makes their analytical computation intractable. Despite recent advances in improving the computational efficiency of the sampling process via the Gumbel top-k trick, the MC estimates can suffer from high variance. We develop a novel approach to producing more sample-efficient estimators of expectations in the PL model by combining the Gumbel top-k trick with quasi-Monte Carlo (QMC) sampling, a well-established technique for variance reduction. We illustrate our findings both theoretically and empirically using real-world recommendation data from Amazon Music and the Yahoo learning-to-rank challenge.
Iterative Policy-Space Expansion in Reinforcement Learning
Dec 05, 2019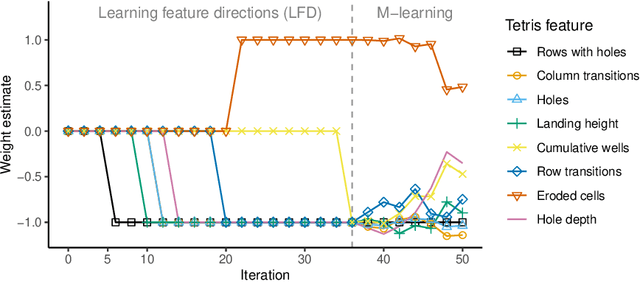
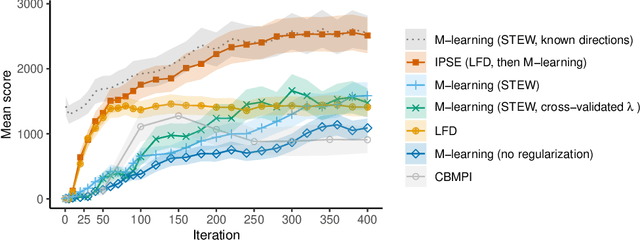
Humans and animals solve a difficult problem much more easily when they are presented with a sequence of problems that starts simple and slowly increases in difficulty. We explore this idea in the context of reinforcement learning. Rather than providing the agent with an externally provided curriculum of progressively more difficult tasks, the agent solves a single task utilizing a decreasingly constrained policy space. The algorithm we propose first learns to categorize features into positive and negative before gradually learning a more refined policy. Experimental results in Tetris demonstrate superior learning rate of our approach when compared to existing algorithms.