 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Recommendations with User Popularity Preferences
Apr 01, 2026Popularity bias is a pervasive problem in recommender systems, where recommendations disproportionately favor popular items. This not only results in "rich-get-richer" dynamics and a homogenization of visible content, but can also lead to misalignment of recommendations with individual users' preferences for popular or niche content. This work studies popularity bias through the lens of user-recommender alignment. To this end, we introduce Popularity Quantile Calibration, a measurement framework that quantifies misalignment between a user's historical popularity preference and the popularity of their recommendations. Building on this notion of popularity alignment, we propose SPREE, an inference-time mitigation method for sequential recommenders based on activation steering. SPREE identifies a popularity direction in representation space and adaptively steers model activations based on an estimate of each user's personal popularity bias, allowing both the direction and magnitude of steering to vary across users. Unlike global debiasing approaches, SPREE explicitly targets alignment rather than uniformly reducing popularity. Experiments across multiple datasets show that SPREE consistently improves user-level popularity alignment while preserving recommendation quality.
Evaluating Large Language Models with fmeval
Jul 15, 2024



fmeval is an open source library to evaluate large language models (LLMs) in a range of tasks. It helps practitioners evaluate their model for task performance and along multiple responsible AI dimensions. This paper presents the library and exposes its underlying design principles: simplicity, coverage, extensibility and performance. We then present how these were implemented in the scientific and engineering choices taken when developing fmeval. A case study demonstrates a typical use case for the library: picking a suitable model for a question answering task. We close by discussing limitations and further work in the development of the library. fmeval can be found at https://github.com/aws/fmeval.
Large Language Models as Recommender Systems: A Study of Popularity Bias
Jun 03, 2024The issue of popularity bias -- where popular items are disproportionately recommended, overshadowing less popular but potentially relevant items -- remains a significant challenge in recommender systems. Recent advancements have seen the integration of general-purpose Large Language Models (LLMs) into the architecture of such systems. This integration raises concerns that it might exacerbate popularity bias, given that the LLM's training data is likely dominated by popular items. However, it simultaneously presents a novel opportunity to address the bias via prompt tuning. Our study explores this dichotomy, examining whether LLMs contribute to or can alleviate popularity bias in recommender systems. We introduce a principled way to measure popularity bias by discussing existing metrics and proposing a novel metric that fulfills a series of desiderata. Based on our new metric, we compare a simple LLM-based recommender to traditional recommender systems on a movie recommendation task. We find that the LLM recommender exhibits less popularity bias, even without any explicit mitigation.
Geographical Erasure in Language Generation
Oct 23, 2023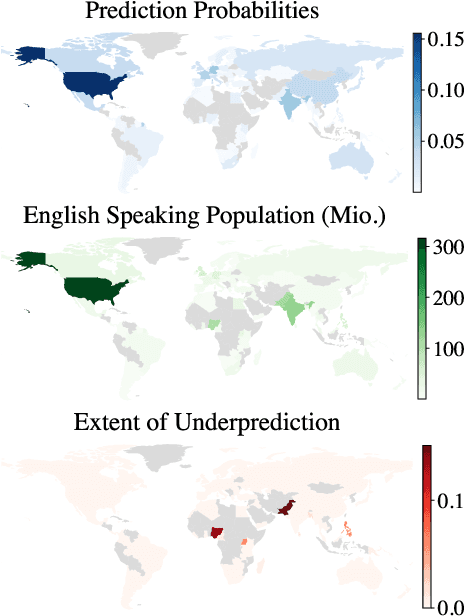

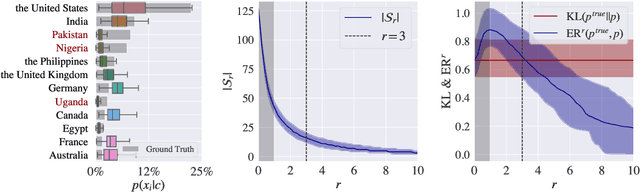
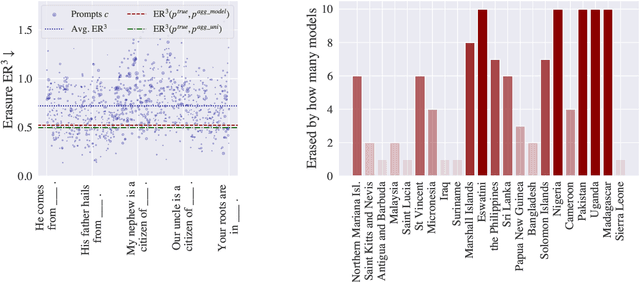
Large language models (LLMs) encode vast amounts of world knowledge. However, since these models are trained on large swaths of internet data, they are at risk of inordinately capturing information about dominant groups. This imbalance can propagate into generated language. In this work, we study and operationalise a form of geographical erasure, wherein language models underpredict certain countries. We demonstrate consistent instances of erasure across a range of LLMs. We discover that erasure strongly correlates with low frequencies of country mentions in the training corpus. Lastly, we mitigate erasure by finetuning using a custom objective.
The Long Arc of Fairness: Formalisations and Ethical Discourse
Mar 08, 2022
In recent years, the idea of formalising and modelling fairness for algorithmic decision making (ADM) has advanced to a point of sophisticated specialisation. However, the relations between technical (formalised) and ethical discourse on fairness are not always clear and productive. Arguing for an alternative perspective, we review existing fairness metrics and discuss some common issues. For instance, the fairness of procedures and distributions is often formalised and discussed statically, disregarding both structural preconditions of the status quo and downstream effects of a given intervention. We then introduce dynamic fairness modelling, a more comprehensive approach that realigns formal fairness metrics with arguments from the ethical discourse. A dynamic fairness model incorporates (1) ethical goals, (2) formal metrics to quantify decision procedures and outcomes and (3) mid-term or long-term downstream effects. By contextualising these elements of fairness-related processes, dynamic fairness modelling explicates formerly latent ethical aspects and thereby provides a helpful tool to navigate trade-offs between different fairness interventions. To illustrate the framework, we discuss an example application -- the current European efforts to increase the number of women on company boards, e.g. via quota solutions -- and present early technical work that fits within our framework.
Probabilistic Spatial Transformers for Bayesian Data Augmentation
Apr 07, 2020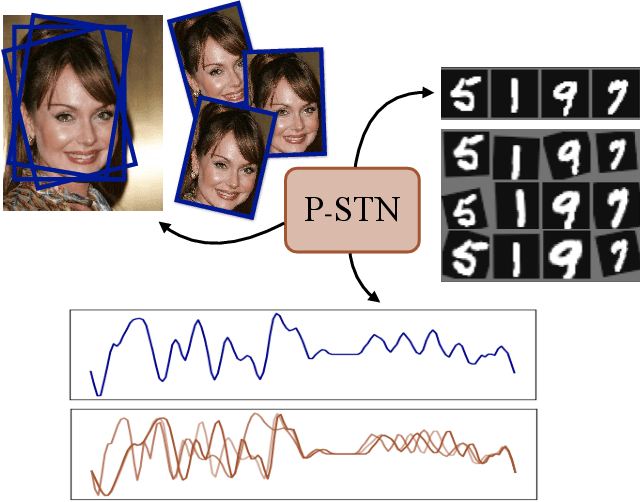
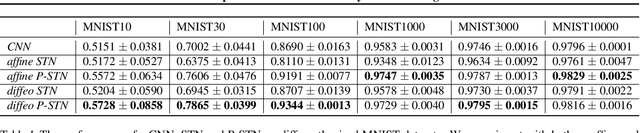
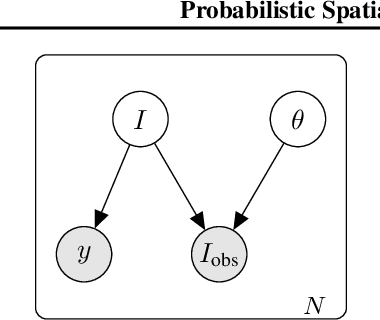

High-capacity models require vast amounts of data, and data augmentation is a common remedy when this resource is limited. Standard augmentation techniques apply small hand-tuned transformations to existing data, which is a brittle process that realistically only allows for simple transformations. We propose a Bayesian interpretation of data augmentation where the transformations are modelled as latent variables to be marginalized, and show how these can be inferred variationally in an end-to-end fashion. This allows for significantly more complex transformations than manual tuning, and the marginalization implies a form of test-time data augmentation. The resulting model can be interpreted as a probabilistic extension of spatial transformer networks. Experimentally, we demonstrate improvements in accuracy and uncertainty quantification in image and time series classification tasks.