 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Reasoning Models for Queries with Presuppositions
May 04, 2026Millions of users turn to AI models for their information needs. It is conceivable that a large number of user queries contain assumptions that may be factually inaccurate. Prior work notes that large language models (LLMs) often fail to challenge such erroneous assumptions, and can reinforce users' misinformed opinions. However, given the recent advances, especially in model's reasoning capabilities, we revisit whether large reasoning models (LRMs) can reason about the underlying assumptions and respond to user queries appropriately. We construct queries with varying degrees of presuppositions spanning health, science, and general knowledge, and use it to evaluate several widely-deployed models When compared to non-reasoning models, we find that reasoning models achieve a slightly higher accuracy (2-11%), but they still fail to challenge a large fraction (26-42%) of false presuppositions. Further, reasoning models remain susceptible to how strongly the presupposition is expressed.
Policies Permitting LLM Use for Polishing Peer Reviews Are Currently Not Enforceable
Mar 20, 2026A number of scientific conferences and journals have recently enacted policies that prohibit LLM usage by peer reviewers, except for polishing, paraphrasing, and grammar correction of otherwise human-written reviews. But, are these policies enforceable? To answer this question, we assemble a dataset of peer reviews simulating multiple levels of human-AI collaboration, and evaluate five state-of-the-art detectors, including two commercial systems. Our analysis shows that all detectors misclassify a non-trivial fraction of LLM-polished reviews as AI-generated, thereby risking false accusations of academic misconduct. We further investigate whether peer-review-specific signals, including access to the paper manuscript and the constrained domain of scientific writing, can be leveraged to improve detection. While incorporating such signals yields measurable gains in some settings, we identify limitations in each approach and find that none meets the accuracy standards required for identifying AI use in peer reviews. Importantly, our results suggest that recent public estimates of AI use in peer reviews through the use of AI-text detectors should be interpreted with caution, as current detectors misclassify mixed reviews (collaborative human-AI outputs) as fully AI generated, potentially overstating the extent of policy violations.
Where Do Images Come From? Analyzing Captions to Geographically Profile Datasets
Feb 10, 2026Recent studies show that text-to-image models often fail to generate geographically representative images, raising concerns about the representativeness of their training data and motivating the question: which parts of the world do these training examples come from? We geographically profile large-scale multimodal datasets by mapping image-caption pairs to countries based on location information extracted from captions using LLMs. Studying English captions from three widely used datasets (Re-LAION, DataComp1B, and Conceptual Captions) across $20$ common entities (e.g., house, flag), we find that the United States, the United Kingdom, and Canada account for $48.0\%$ of samples, while South American and African countries are severely under-represented with only $1.8\%$ and $3.8\%$ of images, respectively. We observe a strong correlation between a country's GDP and its representation in the data ($ρ= 0.82$). Examining non-English subsets for $4$ languages from the Re-LAION dataset, we find that representation skews heavily toward countries where these languages are predominantly spoken. Additionally, we find that higher representation does not necessarily translate to greater visual or semantic diversity. Finally, analyzing country-specific images generated by Stable Diffusion v1.3 trained on Re-LAION, we show that while generations appear realistic, they are severely limited in their coverage compared to real-world images.
Beyond World Models: Rethinking Understanding in AI Models
Nov 15, 2025World models have garnered substantial interest in the AI community. These are internal representations that simulate aspects of the external world, track entities and states, capture causal relationships, and enable prediction of consequences. This contrasts with representations based solely on statistical correlations. A key motivation behind this research direction is that humans possess such mental world models, and finding evidence of similar representations in AI models might indicate that these models "understand" the world in a human-like way. In this paper, we use case studies from the philosophy of science literature to critically examine whether the world model framework adequately characterizes human-level understanding. We focus on specific philosophical analyses where the distinction between world model capabilities and human understanding is most pronounced. While these represent particular views of understanding rather than universal definitions, they help us explore the limits of world models.
Silencing Empowerment, Allowing Bigotry: Auditing the Moderation of Hate Speech on Twitch
Jun 09, 2025



To meet the demands of content moderation, online platforms have resorted to automated systems. Newer forms of real-time engagement($\textit{e.g.}$, users commenting on live streams) on platforms like Twitch exert additional pressures on the latency expected of such moderation systems. Despite their prevalence, relatively little is known about the effectiveness of these systems. In this paper, we conduct an audit of Twitch's automated moderation tool ($\texttt{AutoMod}$) to investigate its effectiveness in flagging hateful content. For our audit, we create streaming accounts to act as siloed test beds, and interface with the live chat using Twitch's APIs to send over $107,000$ comments collated from $4$ datasets. We measure $\texttt{AutoMod}$'s accuracy in flagging blatantly hateful content containing misogyny, racism, ableism and homophobia. Our experiments reveal that a large fraction of hateful messages, up to $94\%$ on some datasets, $\textit{bypass moderation}$. Contextual addition of slurs to these messages results in $100\%$ removal, revealing $\texttt{AutoMod}$'s reliance on slurs as a moderation signal. We also find that contrary to Twitch's community guidelines, $\texttt{AutoMod}$ blocks up to $89.5\%$ of benign examples that use sensitive words in pedagogical or empowering contexts. Overall, our audit points to large gaps in $\texttt{AutoMod}$'s capabilities and underscores the importance for such systems to understand context effectively.
STAMP Your Content: Proving Dataset Membership via Watermarked Rephrasings
Apr 18, 2025Given how large parts of publicly available text are crawled to pretrain large language models (LLMs), data creators increasingly worry about the inclusion of their proprietary data for model training without attribution or licensing. Their concerns are also shared by benchmark curators whose test-sets might be compromised. In this paper, we present STAMP, a framework for detecting dataset membership-i.e., determining the inclusion of a dataset in the pretraining corpora of LLMs. Given an original piece of content, our proposal involves first generating multiple rephrases, each embedding a watermark with a unique secret key. One version is to be released publicly, while others are to be kept private. Subsequently, creators can compare model likelihoods between public and private versions using paired statistical tests to prove membership. We show that our framework can successfully detect contamination across four benchmarks which appear only once in the training data and constitute less than 0.001% of the total tokens, outperforming several contamination detection and dataset inference baselines. We verify that STAMP preserves both the semantic meaning and the utility of the original data in comparing different models. We apply STAMP to two real-world scenarios to confirm the inclusion of paper abstracts and blog articles in the pretraining corpora.
All That Glitters is Not Novel: Plagiarism in AI Generated Research
Feb 23, 2025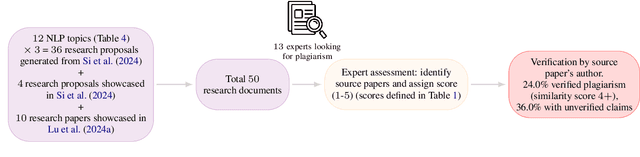

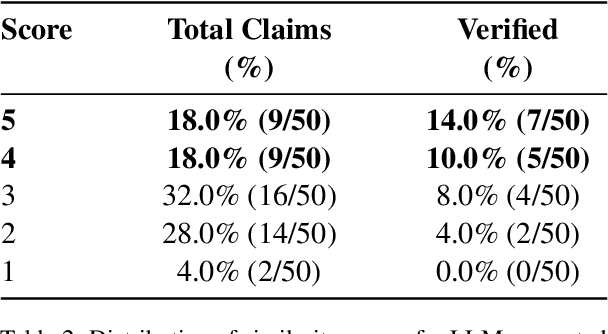
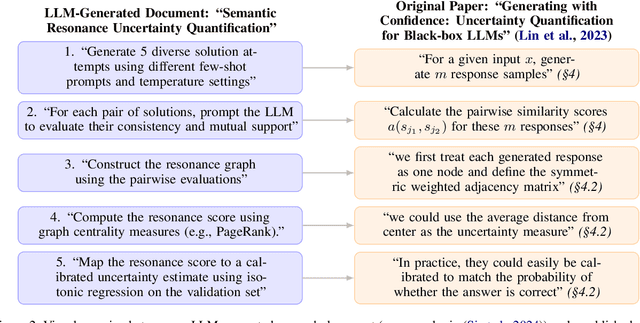
Automating scientific research is considered the final frontier of science. Recently, several papers claim autonomous research agents can generate novel research ideas. Amidst the prevailing optimism, we document a critical concern: a considerable fraction of such research documents are smartly plagiarized. Unlike past efforts where experts evaluate the novelty and feasibility of research ideas, we request $13$ experts to operate under a different situational logic: to identify similarities between LLM-generated research documents and existing work. Concerningly, the experts identify $24\%$ of the $50$ evaluated research documents to be either paraphrased (with one-to-one methodological mapping), or significantly borrowed from existing work. These reported instances are cross-verified by authors of the source papers. Problematically, these LLM-generated research documents do not acknowledge original sources, and bypass inbuilt plagiarism detectors. Lastly, through controlled experiments we show that automated plagiarism detectors are inadequate at catching deliberately plagiarized ideas from an LLM. We recommend a careful assessment of LLM-generated research, and discuss the implications of our findings on research and academic publishing.
Knowledge Graph Guided Evaluation of Abstention Techniques
Dec 10, 2024



To deploy language models safely, it is crucial that they abstain from responding to inappropriate requests. Several prior studies test the safety promises of models based on their effectiveness in blocking malicious requests. In this work, we focus on evaluating the underlying techniques that cause models to abstain. We create SELECT, a benchmark derived from a set of benign concepts (e.g., "rivers") from a knowledge graph. The nature of SELECT enables us to isolate the effects of abstention techniques from other safety training procedures, as well as evaluate their generalization and specificity. Using SELECT, we benchmark different abstention techniques over six open-weight and closed-source models. We find that the examined techniques indeed cause models to abstain with over $80\%$ abstention rates. However, these techniques are not as effective for descendants of the target concepts, with refusal rates declining by $19\%$. We also characterize the generalization-vs-specificity trade-offs for different techniques. Overall, no single technique is invariably better than the others. Our findings call for a careful evaluation of different aspects of abstention, and hopefully inform practitioners of various trade-offs involved.
Richer Output for Richer Countries: Uncovering Geographical Disparities in Generated Stories and Travel Recommendations
Nov 11, 2024



While a large body of work inspects language models for biases concerning gender, race, occupation and religion, biases of geographical nature are relatively less explored. Some recent studies benchmark the degree to which large language models encode geospatial knowledge. However, the impact of the encoded geographical knowledge (or lack thereof) on real-world applications has not been documented. In this work, we examine large language models for two common scenarios that require geographical knowledge: (a) travel recommendations and (b) geo-anchored story generation. Specifically, we study four popular language models, and across about $100$K travel requests, and $200$K story generations, we observe that travel recommendations corresponding to poorer countries are less unique with fewer location references, and stories from these regions more often convey emotions of hardship and sadness compared to those from wealthier nations.
Revisiting the Robustness of Watermarking to Paraphrasing Attacks
Nov 08, 2024
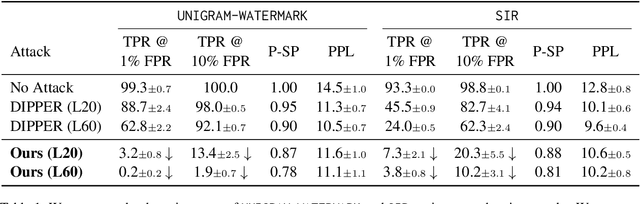


Amidst rising concerns about the internet being proliferated with content generated from language models (LMs), watermarking is seen as a principled way to certify whether text was generated from a model. Many recent watermarking techniques slightly modify the output probabilities of LMs to embed a signal in the generated output that can later be detected. Since early proposals for text watermarking, questions about their robustness to paraphrasing have been prominently discussed. Lately, some techniques are deliberately designed and claimed to be robust to paraphrasing. However, such watermarking schemes do not adequately account for the ease with which they can be reverse-engineered. We show that with access to only a limited number of generations from a black-box watermarked model, we can drastically increase the effectiveness of paraphrasing attacks to evade watermark detection, thereby rendering the watermark ineffective.