 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom `May' to `Is': Certainty Distortion in Language Model Rewriting
Jun 06, 2026Humans increasingly turn to Language Models (LMs) in ways that shape beliefs and drive decisions, including discussing, rewriting, and summarizing information from scientific articles, news, and medical reports. However, in these domains, where how confidently a claim is expressed matters, little is known about whether LMs faithfully preserve it. In this work, we investigate certainty distortion in LMs, defined as meaningful changes in expressed certainty when semantic content is preserved. We propose an LM-based evaluation metric that is consistent with population-level judgments of certainty. Using this metric, we characterize certainty distortion across different sizes and families of models in the context of scientific and medical communication tasks. Our results show that certainty distortion affects up to 75\% of LM outputs and is systematically asymmetric in rewriting tasks with most LMs being 1.5-2$\times$ more likely to increase the expressed certainty than to decrease it. These effects can compound over repeated paraphrasing: in the medical domain, claude-haiku-4-5 increases certainty of 20\% examples after a single iteration, increasing to 40\% after five iterations. Prompt-based interventions reduce overall certainty distortion but do not eliminate it. Together, these findings reveal a general bias toward inflating expressed certainty, with direct implications for users who rely on LMs in high-stakes domains.
Lost in Simulation: LLM-Simulated Users are Unreliable Proxies for Human Users in Agentic Evaluations
Jan 23, 2026Agentic benchmarks increasingly rely on LLM-simulated users to scalably evaluate agent performance, yet the robustness, validity, and fairness of this approach remain unexamined. Through a user study with participants across the United States, India, Kenya, and Nigeria, we investigate whether LLM-simulated users serve as reliable proxies for real human users in evaluating agents on τ-Bench retail tasks. We find that user simulation lacks robustness, with agent success rates varying up to 9 percentage points across different user LLMs. Furthermore, evaluations using simulated users exhibit systematic miscalibration, underestimating agent performance on challenging tasks and overestimating it on moderately difficult ones. African American Vernacular English (AAVE) speakers experience consistently worse success rates and calibration errors than Standard American English (SAE) speakers, with disparities compounding significantly with age. We also find simulated users to be a differentially effective proxy for different populations, performing worst for AAVE and Indian English speakers. Additionally, simulated users introduce conversational artifacts and surface different failure patterns than human users. These findings demonstrate that current evaluation practices risk misrepresenting agent capabilities across diverse user populations and may obscure real-world deployment challenges.
Entropy-Aligned Decoding of LMs for Better Writing and Reasoning
Jan 05, 2026Language models (LMs) are trained on billions of tokens in an attempt to recover the true language distribution. Still, vanilla random sampling from LMs yields low quality generations. Decoding algorithms attempt to restrict the LM distribution to a set of high-probability continuations, but rely on greedy heuristics that introduce myopic distortions, yielding sentences that are homogeneous, repetitive and incoherent. In this paper, we introduce EPIC, a hyperparameter-free decoding approach that incorporates the entropy of future trajectories into LM decoding. EPIC explicitly regulates the amount of uncertainty expressed at every step of generation, aligning the sampling distribution's entropy to the aleatoric (data) uncertainty. Through Entropy-Aware Lazy Gumbel-Max sampling, EPIC manages to be exact, while also being efficient, requiring only a sublinear number of entropy evaluations per step. Unlike current baselines, EPIC yields sampling distributions that are empirically well-aligned with the entropy of the underlying data distribution. Across creative writing and summarization tasks, EPIC consistently improves LM-as-judge preference win-rates over widely used decoding strategies. These preference gains are complemented by automatic metrics, showing that EPIC produces more diverse generations and more faithful summaries. We also evaluate EPIC on mathematical reasoning, where it outperforms all baselines.
Parallel Token Prediction for Language Models
Dec 24, 2025We propose Parallel Token Prediction (PTP), a universal framework for parallel sequence generation in language models. PTP jointly predicts multiple dependent tokens in a single transformer call by incorporating the sampling procedure into the model. This reduces the latency bottleneck of autoregressive decoding, and avoids the restrictive independence assumptions common in existing multi-token prediction methods. We prove that PTP can represent arbitrary autoregressive sequence distributions. PTP is trained either by distilling an existing model or through inverse autoregressive training without a teacher. Experimentally, we achieve state-of-the-art speculative decoding performance on Vicuna-7B by accepting over four tokens per step on Spec-Bench. The universality of our framework indicates that parallel generation of long sequences is feasible without loss of modeling power.
Characterizing Mamba's Selective Memory using Auto-Encoders
Dec 17, 2025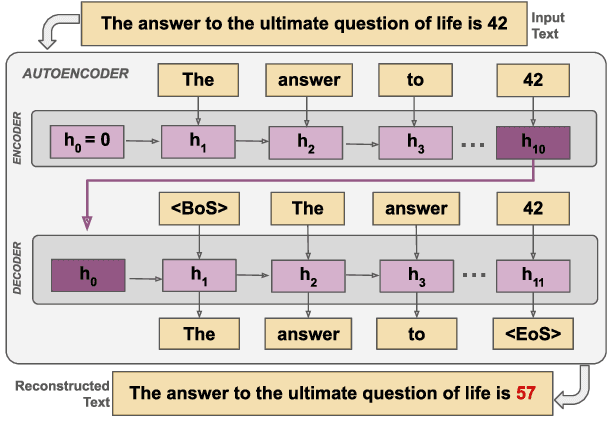
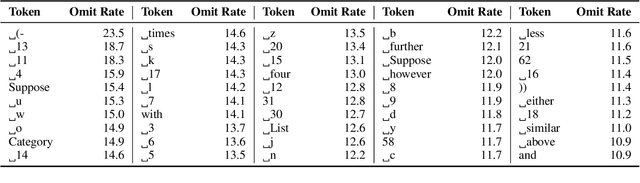
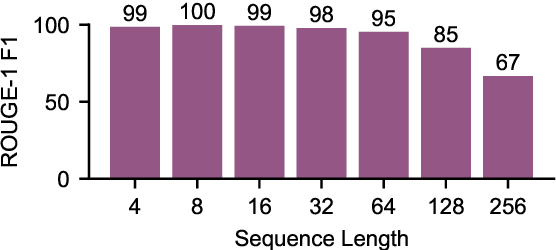
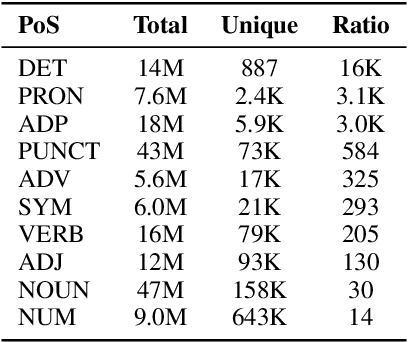
State space models (SSMs) are a promising alternative to transformers for language modeling because they use fixed memory during inference. However, this fixed memory usage requires some information loss in the hidden state when processing long sequences. While prior work has studied the sequence length at which this information loss occurs, it does not characterize the types of information SSM language models (LMs) tend to forget. In this paper, we address this knowledge gap by identifying the types of tokens (e.g., parts of speech, named entities) and sequences (e.g., code, math problems) that are more frequently forgotten by SSM LMs. We achieve this by training an auto-encoder to reconstruct sequences from the SSM's hidden state, and measure information loss by comparing inputs with their reconstructions. We perform experiments using the Mamba family of SSM LMs (130M--1.4B) on sequences ranging from 4--256 tokens. Our results show significantly higher rates of information loss on math-related tokens (e.g., numbers, variables), mentions of organization entities, and alternative dialects to Standard American English. We then examine the frequency that these tokens appear in Mamba's pretraining data and find that less prevalent tokens tend to be the ones Mamba is most likely to forget. By identifying these patterns, our work provides clear direction for future research to develop methods that better control Mamba's ability to retain important information.
Leveraging In-Context Learning for Language Model Agents
Jun 16, 2025In-context learning (ICL) with dynamically selected demonstrations combines the flexibility of prompting large language models (LLMs) with the ability to leverage training data to improve performance. While ICL has been highly successful for prediction and generation tasks, leveraging it for agentic tasks that require sequential decision making is challenging -- one must think not only about how to annotate long trajectories at scale and how to select demonstrations, but also what constitutes demonstrations, and when and where to show them. To address this, we first propose an algorithm that leverages an LLM with retries along with demonstrations to automatically and efficiently annotate agentic tasks with solution trajectories. We then show that set-selection of trajectories of similar tasks as demonstrations significantly improves performance, reliability, robustness, and efficiency of LLM agents. However, trajectory demonstrations have a large inference cost overhead. We show that this can be mitigated by using small trajectory snippets at every step instead of an additional trajectory. We find that demonstrations obtained from larger models (in the annotation phase) also improve smaller models, and that ICL agents can even rival costlier trained agents. Thus, our results reveal that ICL, with careful use, can be very powerful for agentic tasks as well.
Semantic Probabilistic Control of Language Models
May 04, 2025Semantic control entails steering LM generations towards satisfying subtle non-lexical constraints, e.g., toxicity, sentiment, or politeness, attributes that can be captured by a sequence-level verifier. It can thus be viewed as sampling from the LM distribution conditioned on the target attribute, a computationally intractable problem due to the non-decomposable nature of the verifier. Existing approaches to LM control either only deal with syntactic constraints which cannot capture the aforementioned attributes, or rely on sampling to explore the conditional LM distribution, an ineffective estimator for low-probability events. In this work, we leverage a verifier's gradient information to efficiently reason over all generations that satisfy the target attribute, enabling precise steering of LM generations by reweighing the next-token distribution. Starting from an initial sample, we create a local LM distribution favoring semantically similar sentences. This approximation enables the tractable computation of an expected sentence embedding. We use this expected embedding, informed by the verifier's evaluation at the initial sample, to estimate the probability of satisfying the constraint, which directly informs the update to the next-token distribution. We evaluated the effectiveness of our approach in controlling the toxicity, sentiment, and topic-adherence of LMs yielding generations satisfying the constraint with high probability (>95%) without degrading their quality.
Benchmark Data Repositories for Better Benchmarking
Oct 31, 2024



In machine learning research, it is common to evaluate algorithms via their performance on standard benchmark datasets. While a growing body of work establishes guidelines for -- and levies criticisms at -- data and benchmarking practices in machine learning, comparatively less attention has been paid to the data repositories where these datasets are stored, documented, and shared. In this paper, we analyze the landscape of these $\textit{benchmark data repositories}$ and the role they can play in improving benchmarking. This role includes addressing issues with both datasets themselves (e.g., representational harms, construct validity) and the manner in which evaluation is carried out using such datasets (e.g., overemphasis on a few datasets and metrics, lack of reproducibility). To this end, we identify and discuss a set of considerations surrounding the design and use of benchmark data repositories, with a focus on improving benchmarking practices in machine learning.
TurtleBench: A Visual Programming Benchmark in Turtle Geometry
Oct 31, 2024



Humans have the ability to reason about geometric patterns in images and scenes from a young age. However, developing large multimodal models (LMMs) capable of similar reasoning remains a challenge, highlighting the need for robust evaluation methods to assess these capabilities. We introduce TurtleBench, a benchmark designed to evaluate LMMs' capacity to interpret geometric patterns -- given visual examples, textual instructions, or both -- and generate precise code outputs. Inspired by turtle geometry, a notion used to teach children foundational coding and geometric concepts, TurtleBench features tasks with patterned shapes that have underlying algorithmic logic. Our evaluation reveals that leading LMMs struggle significantly with these tasks, with GPT-4o achieving only 19\% accuracy on the simplest tasks and few-shot prompting only marginally improves their performance ($<2\%$). TurtleBench highlights the gap between human and AI performance in intuitive and visual geometrical understanding, setting the stage for future research in this area. TurtleBench stands as one of the few benchmarks to evaluate the integration of visual understanding and code generation capabilities in LMMs, setting the stage for future research. Code and Dataset for this paper is provided here: https://github.com/sinaris76/TurtleBench
Nudging: Inference-time Alignment via Model Collaboration
Oct 15, 2024



Large language models (LLMs) require alignment, such as instruction-tuning or reinforcement learning from human feedback, to effectively and safely follow user instructions. This process necessitates training aligned versions for every model size in each model family, resulting in significant computational overhead. In this work, we propose nudging, a simple, plug-and-play, and training-free algorithm that aligns any base model at inference time using a small aligned model. Nudging is motivated by recent findings that alignment primarily alters the model's behavior on a small subset of stylistic tokens, such as "Sure" or "Thank". We find that base models are significantly more uncertain when generating these tokens. Leveraging this observation, nudging employs a small aligned model to generate nudging tokens to steer the large base model's output toward desired directions when the base model's uncertainty is high. We evaluate the effectiveness of nudging across 3 model families and 13 tasks, covering reasoning, general knowledge, instruction following, and safety benchmarks. Without any additional training, nudging a large base model with a 7x - 14x smaller aligned model achieves zero-shot performance comparable to, and sometimes surpassing, that of large aligned models. For example, nudging OLMo-7b with OLMo-1b-instruct, affecting less than 9% of tokens, achieves a 10% absolute improvement on GSM8K over OLMo-7b-instruct. Unlike prior inference-time tuning methods, nudging enables off-the-shelf collaboration between model families. For instance, nudging Gemma-2-27b with Llama-2-7b-chat outperforms Llama-2-70b-chat on various tasks. Overall, this work introduces a simple yet powerful approach to token-level model collaboration, offering a modular solution to LLM alignment. Our project website: https://fywalter.github.io/nudging/ .