 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Trust: How Humans Mentally Recalibrate AI Confidence Signals
Mar 23, 2026Productive human-AI collaboration requires appropriate reliance, yet contemporary AI systems are often miscalibrated, exhibiting systematic overconfidence or underconfidence. We investigate whether humans can learn to mentally recalibrate AI confidence signals through repeated experience. In a behavioral experiment (N = 200), participants predicted the AI's correctness across four AI calibration conditions: standard, overconfidence, underconfidence, and a counterintuitive "reverse confidence" mapping. Results demonstrate robust learning across all conditions, with participants significantly improving their accuracy, discrimination, and calibration alignment over 50 trials. We present a computational model utilizing a linear-in-log-odds (LLO) transformation and a Rescorla-Wagner learning rule to explain these dynamics. The model reveals that humans adapt by updating their baseline trust and confidence sensitivity, using asymmetric learning rates to prioritize the most informative errors. While humans can compensate for monotonic miscalibration, we identify a significant boundary in the reverse confidence scenario, where a substantial proportion of participants struggled to override initial inductive biases. These findings provide a mechanistic account of how humans adapt their trust in AI confidence signals through experience.
Strategic Shaping of Human Prosociality: A Latent-State POMDP Framework
Mar 02, 2026We propose a decision-theoretic framework in which a robot strategically can shape inferred human's prosocial state during repeated interactions. Modeling the human's prosociality as a latent state that evolves over time, the robot learns to infer and influence this state through its own actions, including helping and signaling. We formalize this as a latent-state POMDP with limited observations and learn the transition and observation dynamics using expectation maximization. The resulting belief-based policy balances task and social objectives, selecting actions that maximize long-term cooperative outcomes. We evaluate the model using data from user studies and show that the learned policy outperforms baseline strategies in both team performance and increasing observed human cooperative behavior.
Beyond Accuracy: How AI Metacognitive Sensitivity improves AI-assisted Decision Making
Jul 30, 2025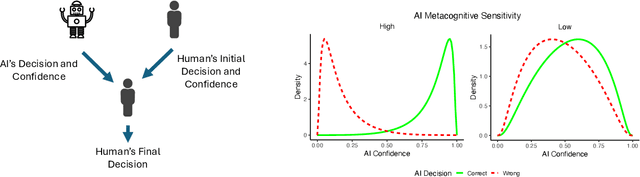


In settings where human decision-making relies on AI input, both the predictive accuracy of the AI system and the reliability of its confidence estimates influence decision quality. We highlight the role of AI metacognitive sensitivity -- its ability to assign confidence scores that accurately distinguish correct from incorrect predictions -- and introduce a theoretical framework for assessing the joint impact of AI's predictive accuracy and metacognitive sensitivity in hybrid decision-making settings. Our analysis identifies conditions under which an AI with lower predictive accuracy but higher metacognitive sensitivity can enhance the overall accuracy of human decision making. Finally, a behavioral experiment confirms that greater AI metacognitive sensitivity improves human decision performance. Together, these findings underscore the importance of evaluating AI assistance not only by accuracy but also by metacognitive sensitivity, and of optimizing both to achieve superior decision outcomes.
Bayesian Inference for Correlated Human Experts and Classifiers
Jun 05, 2025
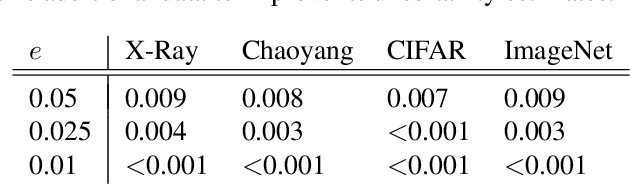
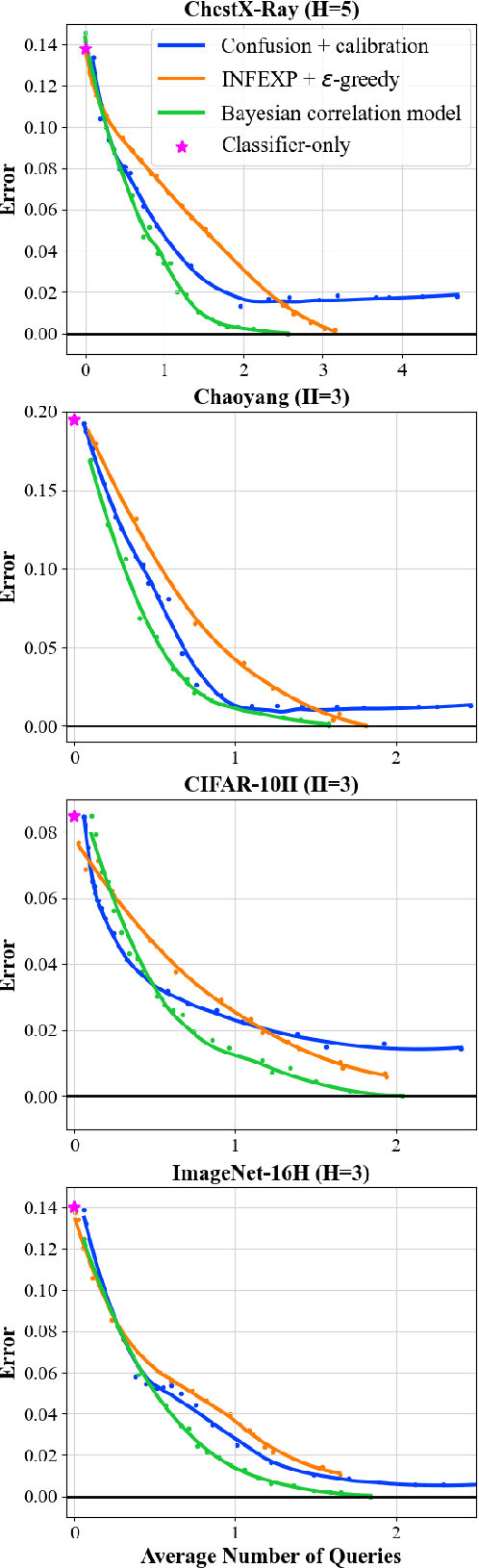

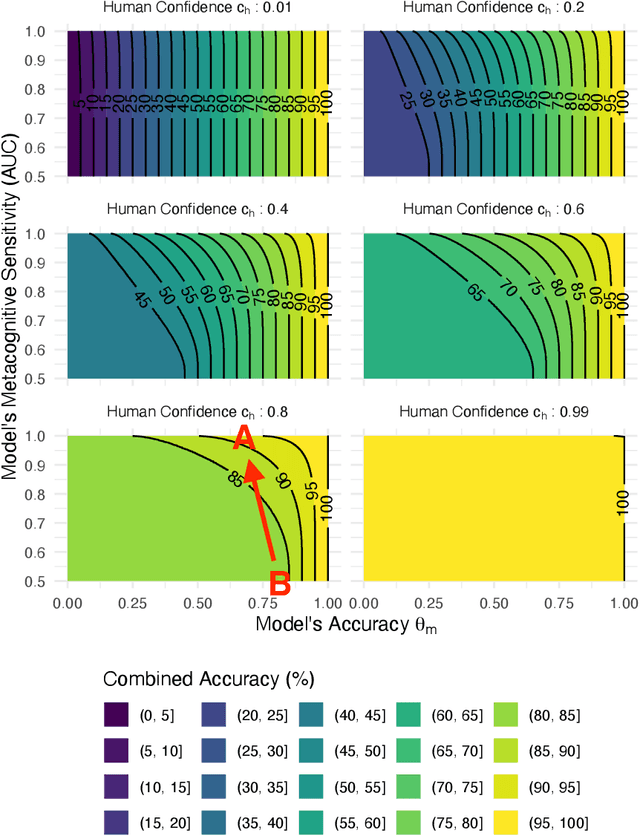
Applications of machine learning often involve making predictions based on both model outputs and the opinions of human experts. In this context, we investigate the problem of querying experts for class label predictions, using as few human queries as possible, and leveraging the class probability estimates of pre-trained classifiers. We develop a general Bayesian framework for this problem, modeling expert correlation via a joint latent representation, enabling simulation-based inference about the utility of additional expert queries, as well as inference of posterior distributions over unobserved expert labels. We apply our approach to two real-world medical classification problems, as well as to CIFAR-10H and ImageNet-16H, demonstrating substantial reductions relative to baselines in the cost of querying human experts while maintaining high prediction accuracy.
Metacognition and Uncertainty Communication in Humans and Large Language Models
Apr 18, 2025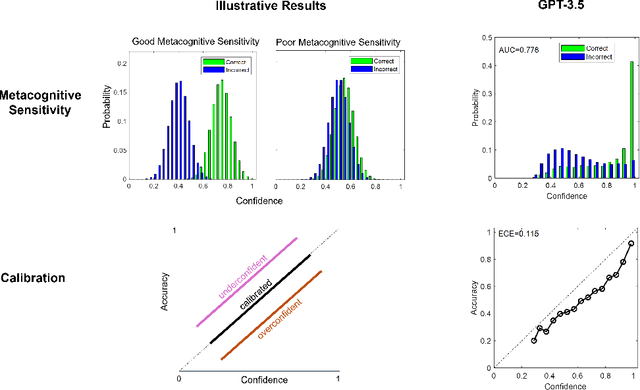
Metacognition, the capacity to monitor and evaluate one's own knowledge and performance, is foundational to human decision-making, learning, and communication. As large language models (LLMs) become increasingly embedded in high-stakes decision contexts, it is critical to assess whether, how, and to what extent they exhibit metacognitive abilities. Here, we provide an overview of current knowledge of LLMs' metacognitive capacities, how they might be studied, and how they relate to our knowledge of metacognition in humans. We show that while humans and LLMs can sometimes appear quite aligned in their metacognitive capacities and behaviors, it is clear many differences remain. Attending to these differences is crucial not only for enhancing human-AI collaboration, but also for promoting the development of more capable and trustworthy artificial systems. Finally, we discuss how endowing future LLMs with more sensitive and more calibrated metacognition may also help them develop new capacities such as more efficient learning, self-direction, and curiosity.
Hybrid Forecasting of Geopolitical Events
Dec 14, 2024



Sound decision-making relies on accurate prediction for tangible outcomes ranging from military conflict to disease outbreaks. To improve crowdsourced forecasting accuracy, we developed SAGE, a hybrid forecasting system that combines human and machine generated forecasts. The system provides a platform where users can interact with machine models and thus anchor their judgments on an objective benchmark. The system also aggregates human and machine forecasts weighting both for propinquity and based on assessed skill while adjusting for overconfidence. We present results from the Hybrid Forecasting Competition (HFC) - larger than comparable forecasting tournaments - including 1085 users forecasting 398 real-world forecasting problems over eight months. Our main result is that the hybrid system generated more accurate forecasts compared to a human-only baseline which had no machine generated predictions. We found that skilled forecasters who had access to machine-generated forecasts outperformed those who only viewed historical data. We also demonstrated the inclusion of machine-generated forecasts in our aggregation algorithms improved performance, both in terms of accuracy and scalability. This suggests that hybrid forecasting systems, which potentially require fewer human resources, can be a viable approach for maintaining a competitive level of accuracy over a larger number of forecasting questions.
* 20 pages, 6 figures, 4 tables
Perceptions of Linguistic Uncertainty by Language Models and Humans
Jul 22, 2024Uncertainty expressions such as ``probably'' or ``highly unlikely'' are pervasive in human language. While prior work has established that there is population-level agreement in terms of how humans interpret these expressions, there has been little inquiry into the abilities of language models to interpret such expressions. In this paper, we investigate how language models map linguistic expressions of uncertainty to numerical responses. Our approach assesses whether language models can employ theory of mind in this setting: understanding the uncertainty of another agent about a particular statement, independently of the model's own certainty about that statement. We evaluate both humans and 10 popular language models on a task created to assess these abilities. Unexpectedly, we find that 8 out of 10 models are able to map uncertainty expressions to probabilistic responses in a human-like manner. However, we observe systematically different behavior depending on whether a statement is actually true or false. This sensitivity indicates that language models are substantially more susceptible to bias based on their prior knowledge (as compared to humans). These findings raise important questions and have broad implications for human-AI alignment and AI-AI communication.
The Calibration Gap between Model and Human Confidence in Large Language Models
Jan 24, 2024For large language models (LLMs) to be trusted by humans they need to be well-calibrated in the sense that they can accurately assess and communicate how likely it is that their predictions are correct. Recent work has focused on the quality of internal LLM confidence assessments, but the question remains of how well LLMs can communicate this internal model confidence to human users. This paper explores the disparity between external human confidence in an LLM's responses and the internal confidence of the model. Through experiments involving multiple-choice questions, we systematically examine human users' ability to discern the reliability of LLM outputs. Our study focuses on two key areas: (1) assessing users' perception of true LLM confidence and (2) investigating the impact of tailored explanations on this perception. The research highlights that default explanations from LLMs often lead to user overestimation of both the model's confidence and its' accuracy. By modifying the explanations to more accurately reflect the LLM's internal confidence, we observe a significant shift in user perception, aligning it more closely with the model's actual confidence levels. This adjustment in explanatory approach demonstrates potential for enhancing user trust and accuracy in assessing LLM outputs. The findings underscore the importance of transparent communication of confidence levels in LLMs, particularly in high-stakes applications where understanding the reliability of AI-generated information is essential.
Bayesian Online Learning for Consensus Prediction
Dec 12, 2023



Given a pre-trained classifier and multiple human experts, we investigate the task of online classification where model predictions are provided for free but querying humans incurs a cost. In this practical but under-explored setting, oracle ground truth is not available. Instead, the prediction target is defined as the consensus vote of all experts. Given that querying full consensus can be costly, we propose a general framework for online Bayesian consensus estimation, leveraging properties of the multivariate hypergeometric distribution. Based on this framework, we propose a family of methods that dynamically estimate expert consensus from partial feedback by producing a posterior over expert and model beliefs. Analyzing this posterior induces an interpretable trade-off between querying cost and classification performance. We demonstrate the efficacy of our framework against a variety of baselines on CIFAR-10H and ImageNet-16H, two large-scale crowdsourced datasets.
Capturing Humans' Mental Models of AI: An Item Response Theory Approach
May 15, 2023



Improving our understanding of how humans perceive AI teammates is an important foundation for our general understanding of human-AI teams. Extending relevant work from cognitive science, we propose a framework based on item response theory for modeling these perceptions. We apply this framework to real-world experiments, in which each participant works alongside another person or an AI agent in a question-answering setting, repeatedly assessing their teammate's performance. Using this experimental data, we demonstrate the use of our framework for testing research questions about people's perceptions of both AI agents and other people. We contrast mental models of AI teammates with those of human teammates as we characterize the dimensionality of these mental models, their development over time, and the influence of the participants' own self-perception. Our results indicate that people expect AI agents' performance to be significantly better on average than the performance of other humans, with less variation across different types of problems. We conclude with a discussion of the implications of these findings for human-AI interaction.