 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Inference for Correlated Human Experts and Classifiers
Jun 05, 2025
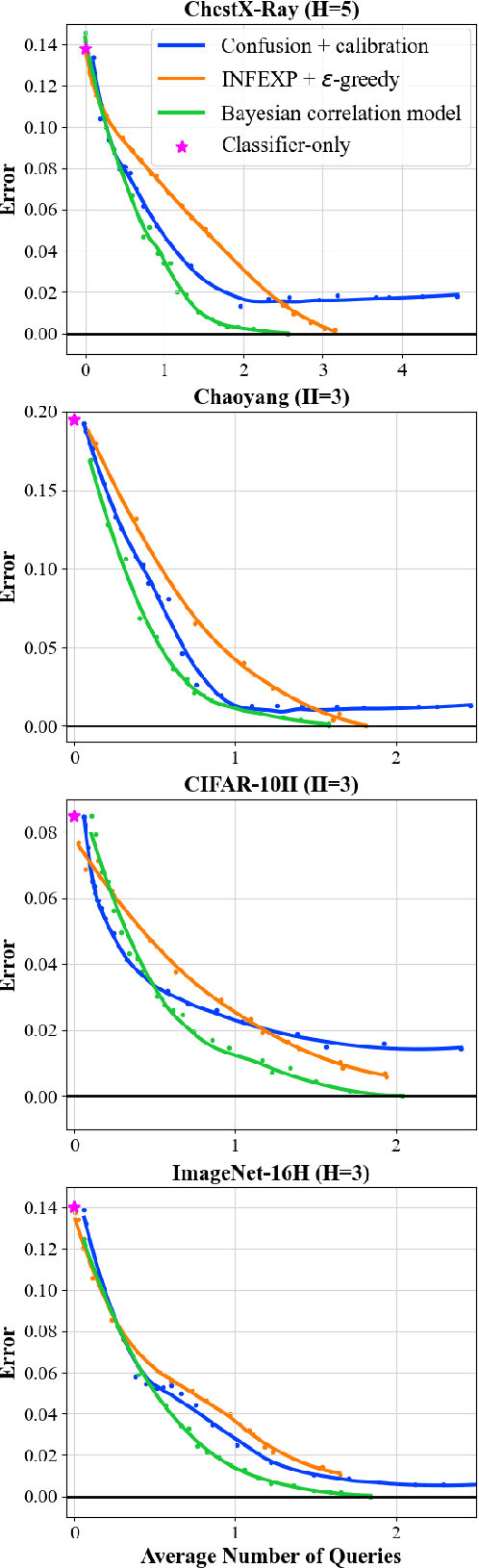

Applications of machine learning often involve making predictions based on both model outputs and the opinions of human experts. In this context, we investigate the problem of querying experts for class label predictions, using as few human queries as possible, and leveraging the class probability estimates of pre-trained classifiers. We develop a general Bayesian framework for this problem, modeling expert correlation via a joint latent representation, enabling simulation-based inference about the utility of additional expert queries, as well as inference of posterior distributions over unobserved expert labels. We apply our approach to two real-world medical classification problems, as well as to CIFAR-10H and ImageNet-16H, demonstrating substantial reductions relative to baselines in the cost of querying human experts while maintaining high prediction accuracy.
Bayesian Online Learning for Consensus Prediction
Dec 12, 2023



Given a pre-trained classifier and multiple human experts, we investigate the task of online classification where model predictions are provided for free but querying humans incurs a cost. In this practical but under-explored setting, oracle ground truth is not available. Instead, the prediction target is defined as the consensus vote of all experts. Given that querying full consensus can be costly, we propose a general framework for online Bayesian consensus estimation, leveraging properties of the multivariate hypergeometric distribution. Based on this framework, we propose a family of methods that dynamically estimate expert consensus from partial feedback by producing a posterior over expert and model beliefs. Analyzing this posterior induces an interpretable trade-off between querying cost and classification performance. We demonstrate the efficacy of our framework against a variety of baselines on CIFAR-10H and ImageNet-16H, two large-scale crowdsourced datasets.
Predictive Querying for Autoregressive Neural Sequence Models
Oct 13, 2022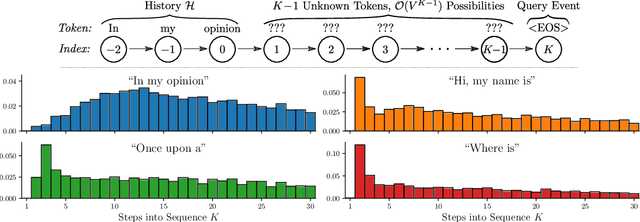

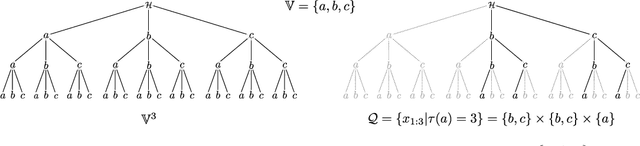

In reasoning about sequential events it is natural to pose probabilistic queries such as "when will event A occur next" or "what is the probability of A occurring before B", with applications in areas such as user modeling, medicine, and finance. However, with machine learning shifting towards neural autoregressive models such as RNNs and transformers, probabilistic querying has been largely restricted to simple cases such as next-event prediction. This is in part due to the fact that future querying involves marginalization over large path spaces, which is not straightforward to do efficiently in such models. In this paper we introduce a general typology for predictive queries in neural autoregressive sequence models and show that such queries can be systematically represented by sets of elementary building blocks. We leverage this typology to develop new query estimation methods based on beam search, importance sampling, and hybrids. Across four large-scale sequence datasets from different application domains, as well as for the GPT-2 language model, we demonstrate the ability to make query answering tractable for arbitrary queries in exponentially-large predictive path-spaces, and find clear differences in cost-accuracy tradeoffs between search and sampling methods.