 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Inference for Correlated Human Experts and Classifiers
Jun 05, 2025
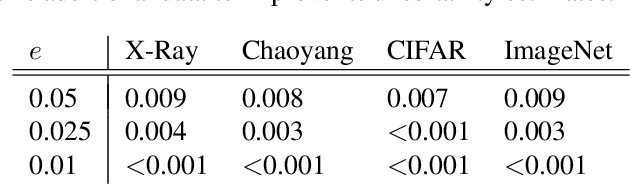
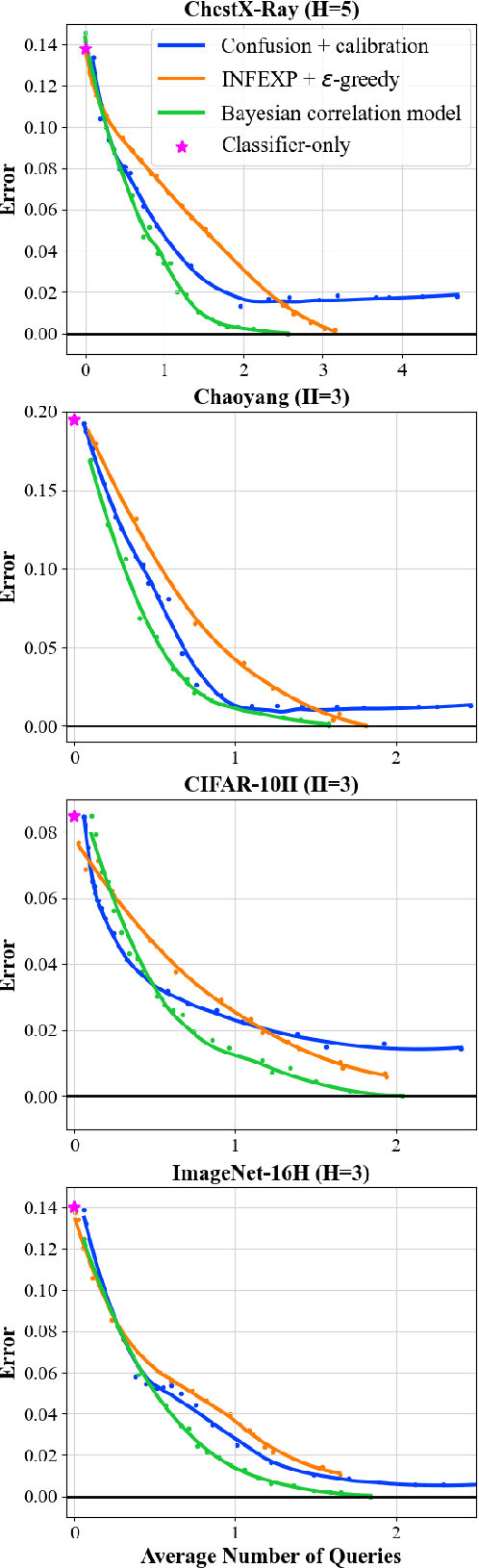

Applications of machine learning often involve making predictions based on both model outputs and the opinions of human experts. In this context, we investigate the problem of querying experts for class label predictions, using as few human queries as possible, and leveraging the class probability estimates of pre-trained classifiers. We develop a general Bayesian framework for this problem, modeling expert correlation via a joint latent representation, enabling simulation-based inference about the utility of additional expert queries, as well as inference of posterior distributions over unobserved expert labels. We apply our approach to two real-world medical classification problems, as well as to CIFAR-10H and ImageNet-16H, demonstrating substantial reductions relative to baselines in the cost of querying human experts while maintaining high prediction accuracy.
Deep Linear Hawkes Processes
Dec 27, 2024Marked temporal point processes (MTPPs) are used to model sequences of different types of events with irregular arrival times, with broad applications ranging from healthcare and social networks to finance. We address shortcomings in existing point process models by drawing connections between modern deep state-space models (SSMs) and linear Hawkes processes (LHPs), culminating in an MTPP that we call the deep linear Hawkes process (DLHP). The DLHP modifies the linear differential equations in deep SSMs to be stochastic jump differential equations, akin to LHPs. After discretizing, the resulting recurrence can be implemented efficiently using a parallel scan. This brings parallelism and linear scaling to MTPP models. This contrasts with attention-based MTPPs, which scale quadratically, and RNN-based MTPPs, which do not parallelize across the sequence length. We show empirically that DLHPs match or outperform existing models across a broad range of metrics on eight real-world datasets. Our proposed DLHP model is the first instance of the unique architectural capabilities of SSMs being leveraged to construct a new class of MTPP models.
On the Efficient Marginalization of Probabilistic Sequence Models
Mar 06, 2024Real-world data often exhibits sequential dependence, across diverse domains such as human behavior, medicine, finance, and climate modeling. Probabilistic methods capture the inherent uncertainty associated with prediction in these contexts, with autoregressive models being especially prominent. This dissertation focuses on using autoregressive models to answer complex probabilistic queries that go beyond single-step prediction, such as the timing of future events or the likelihood of a specific event occurring before another. In particular, we develop a broad class of novel and efficient approximation techniques for marginalization in sequential models that are model-agnostic. These techniques rely solely on access to and sampling from next-step conditional distributions of a pre-trained autoregressive model, including both traditional parametric models as well as more recent neural autoregressive models. Specific approaches are presented for discrete sequential models, for marked temporal point processes, and for stochastic jump processes, each tailored to a well-defined class of informative, long-range probabilistic queries.
Probabilistic Modeling for Sequences of Sets in Continuous-Time
Jan 04, 2024Neural marked temporal point processes have been a valuable addition to the existing toolbox of statistical parametric models for continuous-time event data. These models are useful for sequences where each event is associated with a single item (a single type of event or a "mark") -- but such models are not suited for the practical situation where each event is associated with a set of items. In this work, we develop a general framework for modeling set-valued data in continuous-time, compatible with any intensity-based recurrent neural point process model. In addition, we develop inference methods that can use such models to answer probabilistic queries such as "the probability of item $A$ being observed before item $B$," conditioned on sequence history. Computing exact answers for such queries is generally intractable for neural models due to both the continuous-time nature of the problem setting and the combinatorially-large space of potential outcomes for each event. To address this, we develop a class of importance sampling methods for querying with set-based sequences and demonstrate orders-of-magnitude improvements in efficiency over direct sampling via systematic experiments with four real-world datasets. We also illustrate how to use this framework to perform model selection using likelihoods that do not involve one-step-ahead prediction.
Bayesian Online Learning for Consensus Prediction
Dec 12, 2023



Given a pre-trained classifier and multiple human experts, we investigate the task of online classification where model predictions are provided for free but querying humans incurs a cost. In this practical but under-explored setting, oracle ground truth is not available. Instead, the prediction target is defined as the consensus vote of all experts. Given that querying full consensus can be costly, we propose a general framework for online Bayesian consensus estimation, leveraging properties of the multivariate hypergeometric distribution. Based on this framework, we propose a family of methods that dynamically estimate expert consensus from partial feedback by producing a posterior over expert and model beliefs. Analyzing this posterior induces an interpretable trade-off between querying cost and classification performance. We demonstrate the efficacy of our framework against a variety of baselines on CIFAR-10H and ImageNet-16H, two large-scale crowdsourced datasets.
Understanding Pathologies of Deep Heteroskedastic Regression
Jun 29, 2023



Several recent studies have reported negative results when using heteroskedastic neural regression models to model real-world data. In particular, for overparameterized models, the mean and variance networks are powerful enough to either fit every single data point (while shrinking the predicted variances to zero), or to learn a constant prediction with an output variance exactly matching every predicted residual (i.e., explaining the targets as pure noise). This paper studies these difficulties from the perspective of statistical physics. We show that the observed instabilities are not specific to any neural network architecture but are already present in a field theory of an overparameterized conditional Gaussian likelihood model. Under light assumptions, we derive a nonparametric free energy that can be solved numerically. The resulting solutions show excellent qualitative agreement with empirical model fits on real-world data and, in particular, prove the existence of phase transitions, i.e., abrupt, qualitative differences in the behaviors of the regressors upon varying the regularization strengths on the two networks. Our work thus provides a theoretical explanation for the necessity to carefully regularize heteroskedastic regression models. Moreover, the insights from our theory suggest a scheme for optimizing this regularization which is quadratically more efficient than the naive approach.
Probabilistic Querying of Continuous-Time Event Sequences
Nov 15, 2022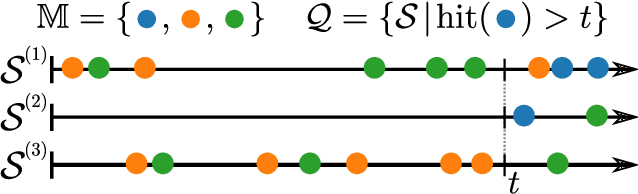

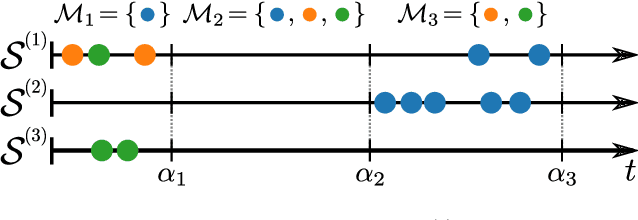
Continuous-time event sequences, i.e., sequences consisting of continuous time stamps and associated event types ("marks"), are an important type of sequential data with many applications, e.g., in clinical medicine or user behavior modeling. Since these data are typically modeled autoregressively (e.g., using neural Hawkes processes or their classical counterparts), it is natural to ask questions about future scenarios such as "what kind of event will occur next" or "will an event of type $A$ occur before one of type $B$". Unfortunately, some of these queries are notoriously hard to address since current methods are limited to naive simulation, which can be highly inefficient. This paper introduces a new typology of query types and a framework for addressing them using importance sampling. Example queries include predicting the $n^\text{th}$ event type in a sequence and the hitting time distribution of one or more event types. We also leverage these findings further to be applicable for estimating general "$A$ before $B$" type of queries. We prove theoretically that our estimation method is effectively always better than naive simulation and show empirically based on three real-world datasets that it is on average 1,000 times more efficient than existing approaches.
Predictive Querying for Autoregressive Neural Sequence Models
Oct 13, 2022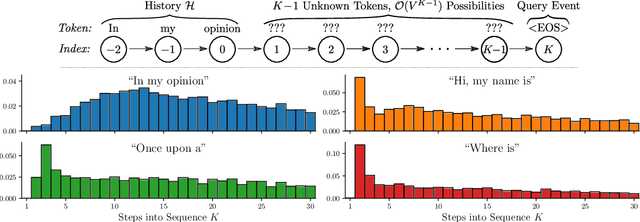

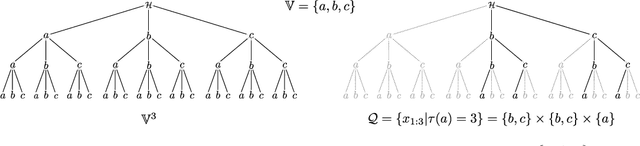

In reasoning about sequential events it is natural to pose probabilistic queries such as "when will event A occur next" or "what is the probability of A occurring before B", with applications in areas such as user modeling, medicine, and finance. However, with machine learning shifting towards neural autoregressive models such as RNNs and transformers, probabilistic querying has been largely restricted to simple cases such as next-event prediction. This is in part due to the fact that future querying involves marginalization over large path spaces, which is not straightforward to do efficiently in such models. In this paper we introduce a general typology for predictive queries in neural autoregressive sequence models and show that such queries can be systematically represented by sets of elementary building blocks. We leverage this typology to develop new query estimation methods based on beam search, importance sampling, and hybrids. Across four large-scale sequence datasets from different application domains, as well as for the GPT-2 language model, we demonstrate the ability to make query answering tractable for arbitrary queries in exponentially-large predictive path-spaces, and find clear differences in cost-accuracy tradeoffs between search and sampling methods.
Structured Stochastic Gradient MCMC
Jul 19, 2021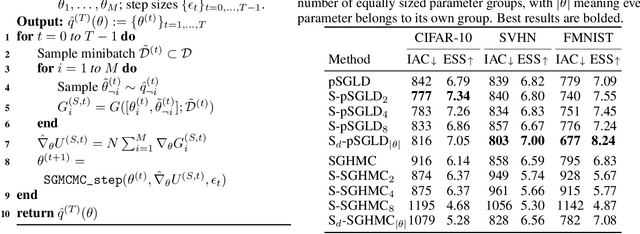
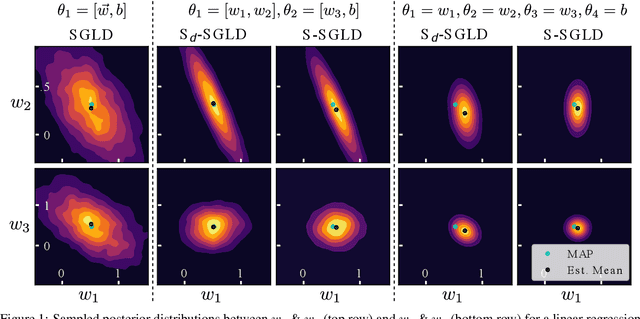
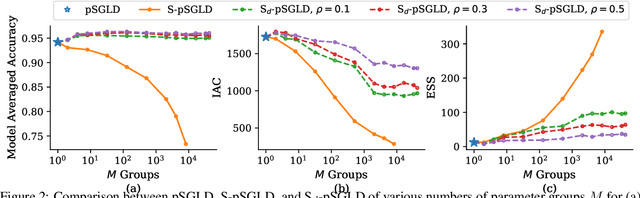
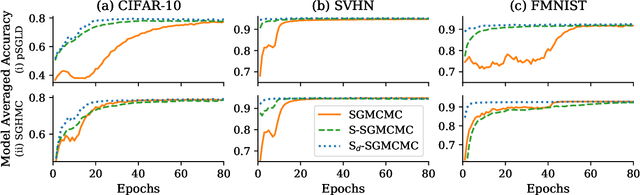
Stochastic gradient Markov chain Monte Carlo (SGMCMC) is considered the gold standard for Bayesian inference in large-scale models, such as Bayesian neural networks. Since practitioners face speed versus accuracy tradeoffs in these models, variational inference (VI) is often the preferable option. Unfortunately, VI makes strong assumptions on both the factorization and functional form of the posterior. In this work, we propose a new non-parametric variational approximation that makes no assumptions about the approximate posterior's functional form and allows practitioners to specify the exact dependencies the algorithm should respect or break. The approach relies on a new Langevin-type algorithm that operates on a modified energy function, where parts of the latent variables are averaged over samples from earlier iterations of the Markov chain. This way, statistical dependencies can be broken in a controlled way, allowing the chain to mix faster. This scheme can be further modified in a ''dropout'' manner, leading to even more scalability. By implementing the scheme on a ResNet-20 architecture, we obtain better predictive likelihoods and larger effective sample sizes than full SGMCMC.
Variational Beam Search for Online Learning with Distribution Shifts
Dec 15, 2020

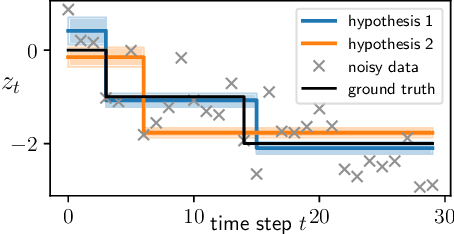
We consider the problem of online learning in the presence of sudden distribution shifts as frequently encountered in applications such as autonomous navigation. Distribution shifts require constant performance monitoring and re-training. They may also be hard to detect and can lead to a slow but steady degradation in model performance. To address this problem we propose a new Bayesian meta-algorithm that can both (i) make inferences about subtle distribution shifts based on minimal sequential observations and (ii) accordingly adapt a model in an online fashion. The approach uses beam search over multiple change point hypotheses to perform inference on a hierarchical sequential latent variable modeling framework. Our proposed approach is model-agnostic, applicable to both supervised and unsupervised learning, and yields significant improvements over state-of-the-art Bayesian online learning approaches.