 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Erosion: Emulating Controlled Neurodegeneration and Aging in AI Systems
Mar 15, 2024



Creating controlled methods to simulate neurodegeneration in artificial intelligence (AI) is crucial for applications that emulate brain function decline and cognitive disorders. We use IQ tests performed by Large Language Models (LLMs) and, more specifically, the LLaMA 2 to introduce the concept of ``neural erosion." This deliberate erosion involves ablating synapses or neurons, or adding Gaussian noise during or after training, resulting in a controlled progressive decline in the LLMs' performance. We are able to describe the neurodegeneration in the IQ tests and show that the LLM first loses its mathematical abilities and then its linguistic abilities, while further losing its ability to understand the questions. To the best of our knowledge, this is the first work that models neurodegeneration with text data, compared to other works that operate in the computer vision domain. Finally, we draw similarities between our study and cognitive decline clinical studies involving test subjects. We find that with the application of neurodegenerative methods, LLMs lose abstract thinking abilities, followed by mathematical degradation, and ultimately, a loss in linguistic ability, responding to prompts incoherently. These findings are in accordance with human studies.
AttentionStitch: How Attention Solves the Speech Editing Problem
Mar 05, 2024
The generation of natural and high-quality speech from text is a challenging problem in the field of natural language processing. In addition to speech generation, speech editing is also a crucial task, which requires the seamless and unnoticeable integration of edited speech into synthesized speech. We propose a novel approach to speech editing by leveraging a pre-trained text-to-speech (TTS) model, such as FastSpeech 2, and incorporating a double attention block network on top of it to automatically merge the synthesized mel-spectrogram with the mel-spectrogram of the edited text. We refer to this model as AttentionStitch, as it harnesses attention to stitch audio samples together. We evaluate the proposed AttentionStitch model against state-of-the-art baselines on both single and multi-speaker datasets, namely LJSpeech and VCTK. We demonstrate its superior performance through an objective and a subjective evaluation test involving 15 human participants. AttentionStitch is capable of producing high-quality speech, even for words not seen during training, while operating automatically without the need for human intervention. Moreover, AttentionStitch is fast during both training and inference and is able to generate human-sounding edited speech.
Machine Learning-Enhanced Prediction of Surface Smoothness for Inertial Confinement Fusion Target Polishing Using Limited Data
Dec 16, 2023In Inertial Confinement Fusion (ICF) process, roughly a 2mm spherical shell made of high density carbon is used as target for laser beams, which compress and heat it to energy levels needed for high fusion yield. These shells are polished meticulously to meet the standards for a fusion shot. However, the polishing of these shells involves multiple stages, with each stage taking several hours. To make sure that the polishing process is advancing in the right direction, we are able to measure the shell surface roughness. This measurement, however, is very labor-intensive, time-consuming, and requires a human operator. We propose to use machine learning models that can predict surface roughness based on the data collected from a vibration sensor that is connected to the polisher. Such models can generate surface roughness of the shells in real-time, allowing the operator to make any necessary changes to the polishing for optimal result.
Structured Stochastic Gradient MCMC
Jul 19, 2021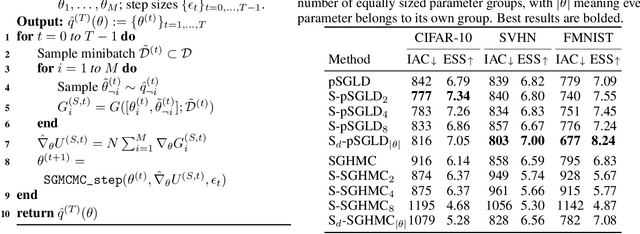
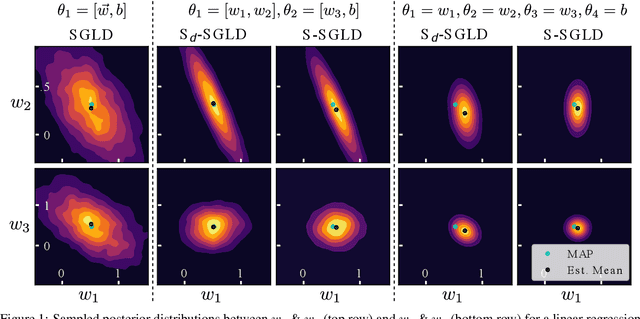
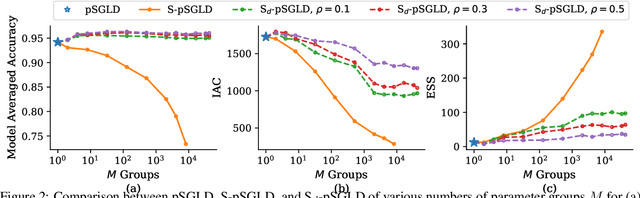
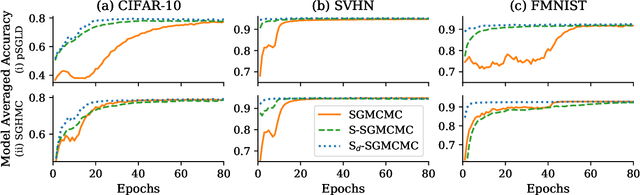
Stochastic gradient Markov chain Monte Carlo (SGMCMC) is considered the gold standard for Bayesian inference in large-scale models, such as Bayesian neural networks. Since practitioners face speed versus accuracy tradeoffs in these models, variational inference (VI) is often the preferable option. Unfortunately, VI makes strong assumptions on both the factorization and functional form of the posterior. In this work, we propose a new non-parametric variational approximation that makes no assumptions about the approximate posterior's functional form and allows practitioners to specify the exact dependencies the algorithm should respect or break. The approach relies on a new Langevin-type algorithm that operates on a modified energy function, where parts of the latent variables are averaged over samples from earlier iterations of the Markov chain. This way, statistical dependencies can be broken in a controlled way, allowing the chain to mix faster. This scheme can be further modified in a ''dropout'' manner, leading to even more scalability. By implementing the scheme on a ResNet-20 architecture, we obtain better predictive likelihoods and larger effective sample sizes than full SGMCMC.
Local Competition and Stochasticity for Adversarial Robustness in Deep Learning
Jan 04, 2021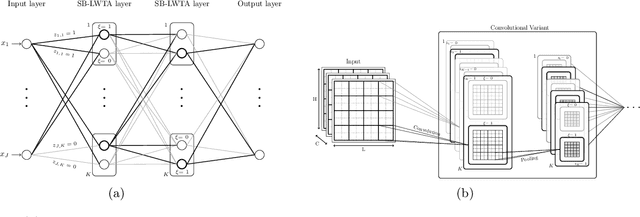
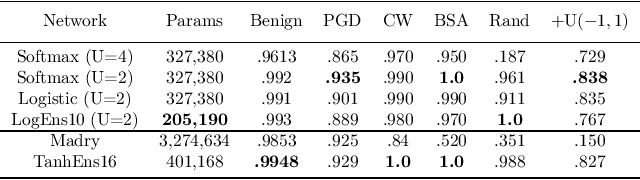

This work addresses adversarial robustness in deep learning by considering deep networks with stochastic local winner-takes-all (LWTA) nonlinearities. This type of network units result in sparse representations from each model layer, as the units are organized in blocks where only one unit generates non-zero output. The main operating principle of the introduced units lies on stochastic arguments, as the network performs posterior sampling over competing units to select the winner. We combine these LWTA arguments with tools from the field of Bayesian non-parametrics, specifically the stick-breaking construction of the Indian Buffet Process, to allow for inferring the sub-part of each layer that is essential for modeling the data at hand. Inference for the proposed network is performed by means of stochastic variational Bayes. We perform a thorough experimental evaluation of our model using benchmark datasets, assuming gradient-based adversarial attacks. As we show, our method achieves high robustness to adversarial perturbations, with state-of-the-art performance in powerful white-box attacks.
Local Competition and Uncertainty for Adversarial Robustness in Deep Learning
Jun 18, 2020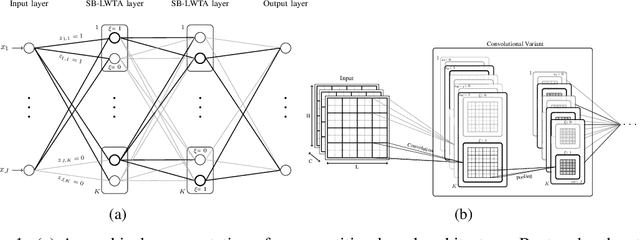
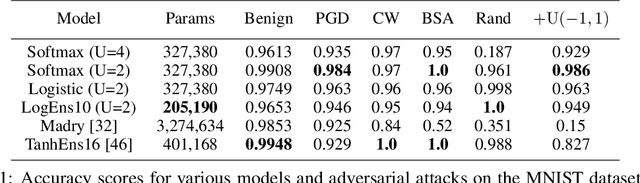
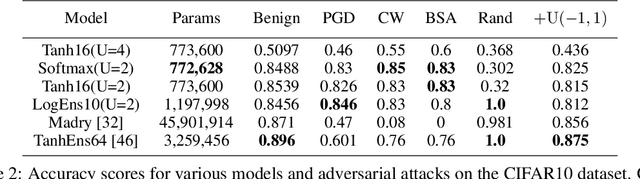
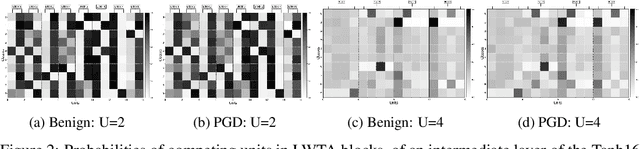
This work attempts to address adversarial robustness of deep networks by means of novel learning arguments. Specifically, inspired from results in neuroscience, we propose a local competition principle as a means of adversarially-robust deep learning. We argue that novel local winner-takes-all (LWTA) nonlinearities, combined with posterior sampling schemes, can greatly improve the adversarial robustness of traditional deep networks against difficult adversarial attack schemes. We combine these LWTA arguments with tools from the field of Bayesian non-parametrics, specifically the stick-breaking construction of the Indian Buffet Process, to flexibly account for the inherent uncertainty in data-driven modeling. As we experimentally show, the new proposed model achieves high robustness to adversarial perturbations on MNIST and CIFAR10 datasets. Our model achieves state-of-the-art results in powerful white-box attacks, while at the same time retaining its benign accuracy to a high degree. Equally importantly, our approach achieves this result while requiring far less trainable model parameters than the existing state-of-the-art.