 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevelopment of Interactive Nomograms for Predicting Short-Term Survival in ICU Patients with Aplastic Anemia
May 23, 2025Aplastic anemia is a rare, life-threatening hematologic disorder characterized by pancytopenia and bone marrow failure. ICU admission in these patients often signals critical complications or disease progression, making early risk assessment crucial for clinical decision-making and resource allocation. In this study, we used the MIMIC-IV database to identify ICU patients diagnosed with aplastic anemia and extracted clinical features from five domains: demographics, synthetic indicators, laboratory results, comorbidities, and medications. Over 400 variables were reduced to seven key predictors through machine learning-based feature selection. Logistic regression and Cox regression models were constructed to predict 7-, 14-, and 28-day mortality, and their performance was evaluated using AUROC. External validation was conducted using the eICU Collaborative Research Database to assess model generalizability. Among 1,662 included patients, the logistic regression model demonstrated superior performance, with AUROC values of 0.8227, 0.8311, and 0.8298 for 7-, 14-, and 28-day mortality, respectively, compared to the Cox model. External validation yielded AUROCs of 0.7391, 0.7119, and 0.7093. Interactive nomograms were developed based on the logistic regression model to visually estimate individual patient risk. In conclusion, we identified a concise set of seven predictors, led by APS III, to build validated and generalizable nomograms that accurately estimate short-term mortality in ICU patients with aplastic anemia. These tools may aid clinicians in personalized risk stratification and decision-making at the point of care.
Machine Learning-Based Model for Postoperative Stroke Prediction in Coronary Artery Disease
Mar 15, 2025


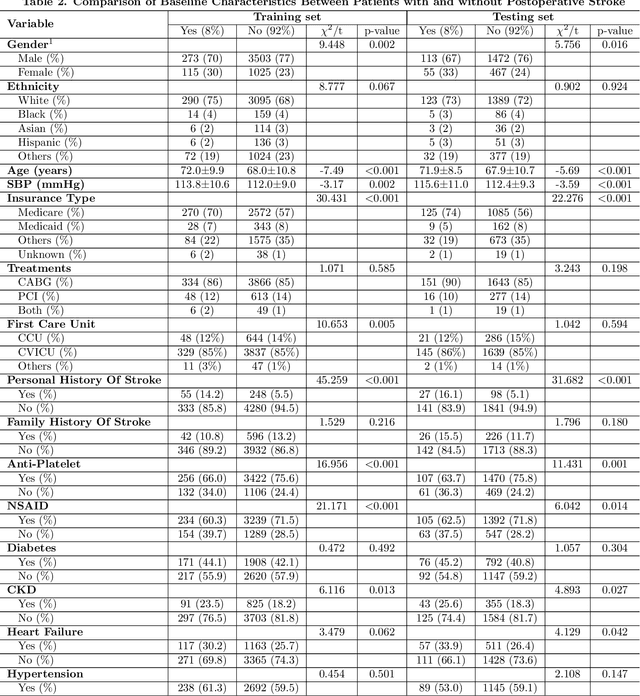
Coronary artery disease remains one of the leading causes of mortality globally. Despite advances in revascularization treatments like PCI and CABG, postoperative stroke is inevitable. This study aims to develop and evaluate a sophisticated machine learning prediction model to assess postoperative stroke risk in coronary revascularization patients.This research employed data from the MIMIC-IV database, consisting of a cohort of 7023 individuals. Study data included clinical, laboratory, and comorbidity variables. To reduce multicollinearity, variables with over 30% missing values and features with a correlation coefficient larger than 0.9 were deleted. The dataset has 70% training and 30% test. The Random Forest technique interpolated residual dataset missing values. Numerical values were normalized, whereas categorical variables were one-hot encoded. LASSO regularization selected features, and grid search found model hyperparameters. Finally, Logistic Regression, XGBoost, SVM, and CatBoost were employed for predictive modeling, and SHAP analysis assessed stroke risk for each variable. AUC of 0.855 (0.829-0.878) showed that SVM model outperformed logistic regression and CatBoost models in prior research. SHAP research showed that the Charlson Comorbidity Index (CCI), diabetes, chronic kidney disease, and heart failure are significant prognostic factors for postoperative stroke. This study shows that improved machine learning reduces overfitting and improves model predictive accuracy. Models using the CCI alone cannot predict postoperative stroke risk as accurately as those using independent comorbidity variables. The suggested technique provides a more thorough and individualized risk assessment by encompassing a wider range of clinically relevant characteristics, making it a better reference for preoperative risk assessments and targeted intervention.
XGBoost-Based Prediction of ICU Mortality in Sepsis-Associated Acute Kidney Injury Patients Using MIMIC-IV Database with Validation from eICU Database
Feb 25, 2025
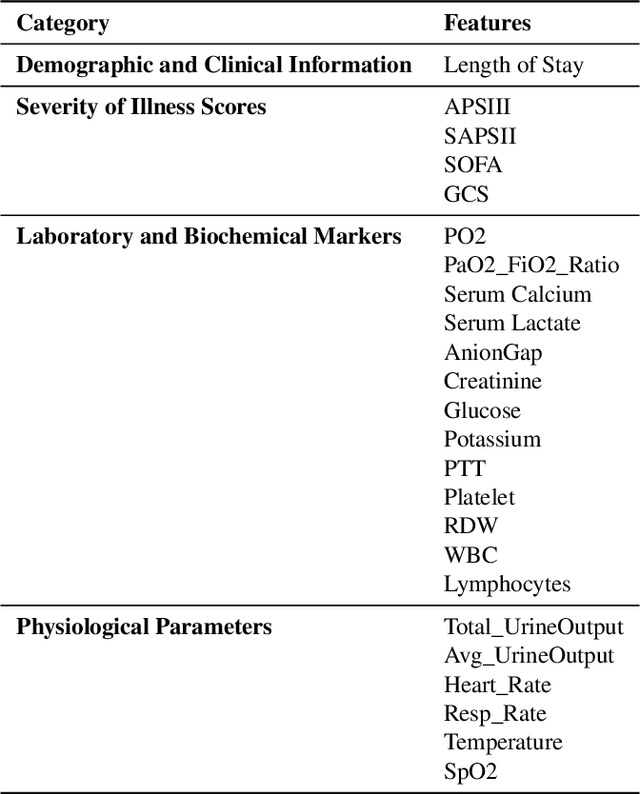
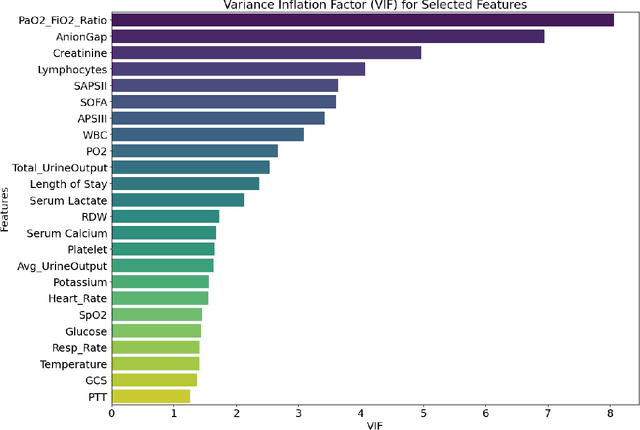
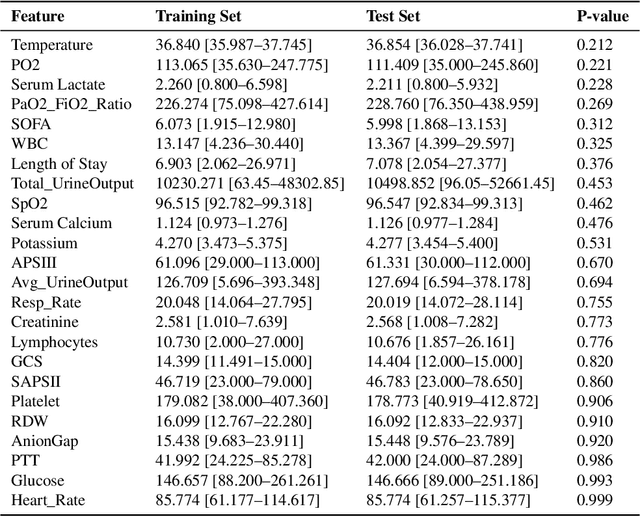
Background: Sepsis-Associated Acute Kidney Injury (SA-AKI) leads to high mortality in intensive care. This study develops machine learning models using the Medical Information Mart for Intensive Care IV (MIMIC-IV) database to predict Intensive Care Unit (ICU) mortality in SA-AKI patients. External validation is conducted using the eICU Collaborative Research Database. Methods: For 9,474 identified SA-AKI patients in MIMIC-IV, key features like lab results, vital signs, and comorbidities were selected using Variance Inflation Factor (VIF), Recursive Feature Elimination (RFE), and expert input, narrowing to 24 predictive variables. An Extreme Gradient Boosting (XGBoost) model was built for in-hospital mortality prediction, with hyperparameters optimized using GridSearch. Model interpretability was enhanced with SHapley Additive exPlanations (SHAP) and Local Interpretable Model-agnostic Explanations (LIME). External validation was conducted using the eICU database. Results: The proposed XGBoost model achieved an internal Area Under the Receiver Operating Characteristic curve (AUROC) of 0.878 (95% Confidence Interval: 0.859-0.897). SHAP identified Sequential Organ Failure Assessment (SOFA), serum lactate, and respiratory rate as key mortality predictors. LIME highlighted serum lactate, Acute Physiology and Chronic Health Evaluation II (APACHE II) score, total urine output, and serum calcium as critical features. Conclusions: The integration of advanced techniques with the XGBoost algorithm yielded a highly accurate and interpretable model for predicting SA-AKI mortality across diverse populations. It supports early identification of high-risk patients, enhancing clinical decision-making in intensive care. Future work needs to focus on enhancing adaptability, versatility, and real-world applications.
A Novel Multi-Task Teacher-Student Architecture with Self-Supervised Pretraining for 48-Hour Vasoactive-Inotropic Trend Analysis in Sepsis Mortality Prediction
Feb 24, 2025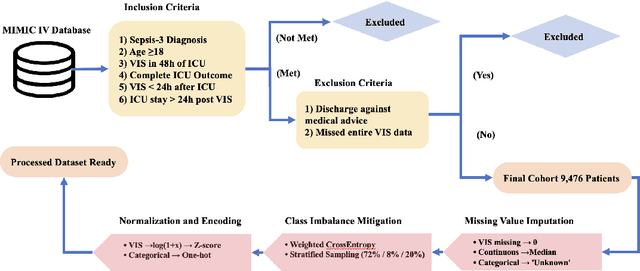

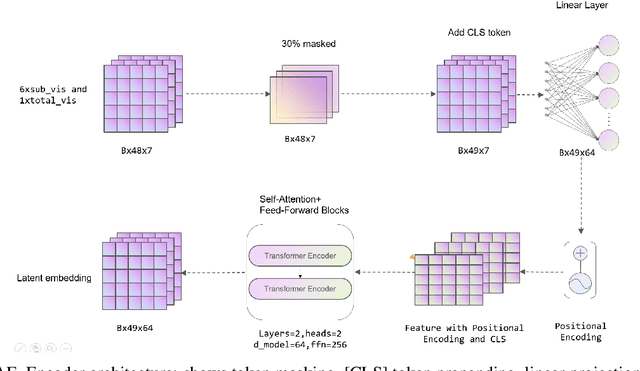
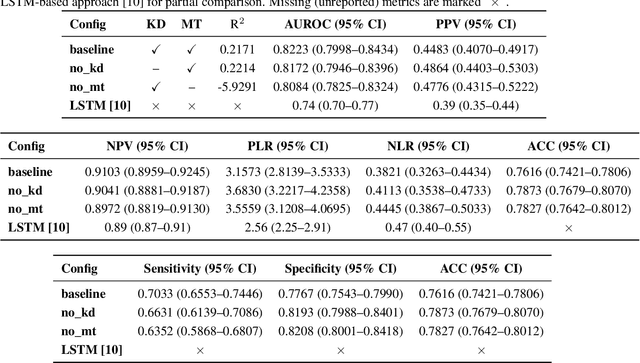
Sepsis is a major cause of ICU mortality, where early recognition and effective interventions are essential for improving patient outcomes. However, the vasoactive-inotropic score (VIS) varies dynamically with a patient's hemodynamic status, complicated by irregular medication patterns, missing data, and confounders, making sepsis prediction challenging. To address this, we propose a novel Teacher-Student multitask framework with self-supervised VIS pretraining via a Masked Autoencoder (MAE). The teacher model performs mortality classification and severity-score regression, while the student distills robust time-series representations, enhancing adaptation to heterogeneous VIS data. Compared to LSTM-based methods, our approach achieves an AUROC of 0.82 on MIMIC-IV 3.0 (9,476 patients), outperforming the baseline (0.74). SHAP analysis revealed that SOFA score (0.147) had the greatest impact on ICU mortality, followed by LODS (0.033), single marital status (0.031), and Medicaid insurance (0.023), highlighting the role of sociodemographic factors. SAPSII (0.020) also contributed significantly. These findings suggest that both clinical and social factors should be considered in ICU decision-making. Our novel multitask and distillation strategies enable earlier identification of high-risk patients, improving prediction accuracy and disease management, offering new tools for ICU decision support.
Machine Learning-Based Prediction of ICU Readmissions in Intracerebral Hemorrhage Patients: Insights from the MIMIC Databases
Jan 02, 2025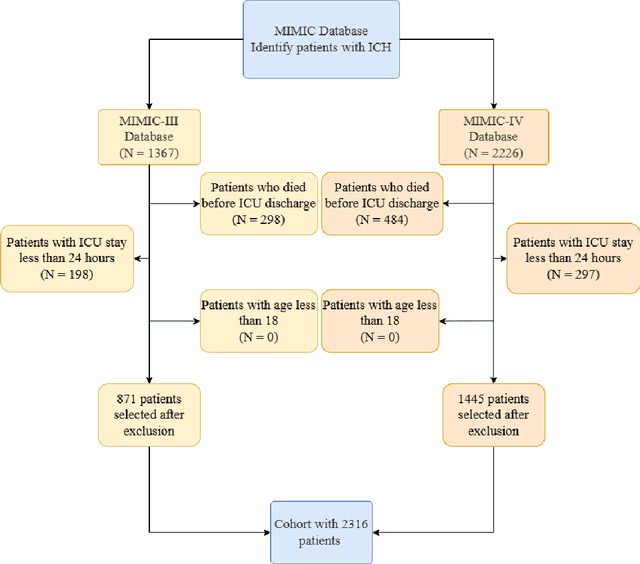
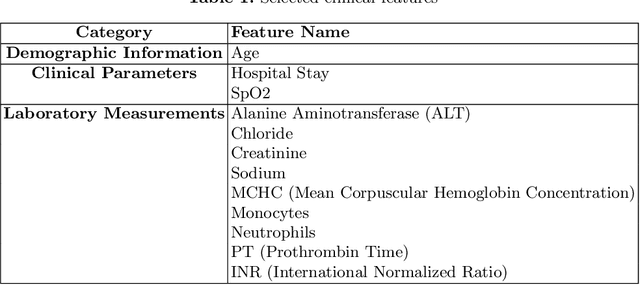
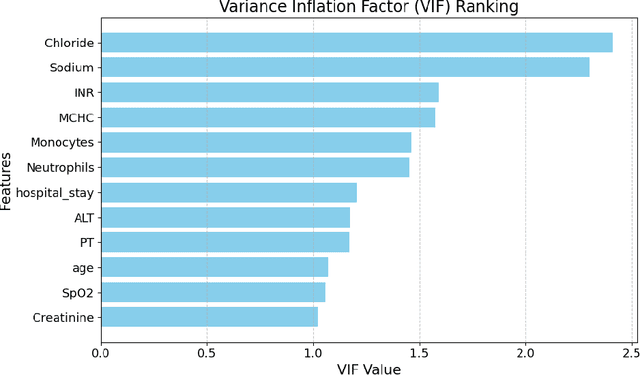
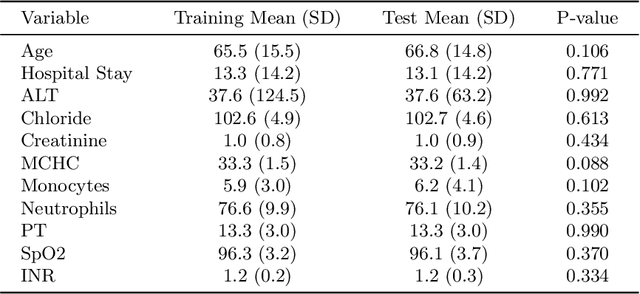
Intracerebral hemorrhage (ICH) is a life-risking condition characterized by bleeding within the brain parenchyma. ICU readmission in ICH patients is a critical outcome, reflecting both clinical severity and resource utilization. Accurate prediction of ICU readmission risk is crucial for guiding clinical decision-making and optimizing healthcare resources. This study utilized the Medical Information Mart for Intensive Care (MIMIC-III and MIMIC-IV) databases, which contain comprehensive clinical and demographic data on ICU patients. Patients with ICH were identified from both databases. Various clinical, laboratory, and demographic features were extracted for analysis based on both overview literature and experts' opinions. Preprocessing methods like imputing and sampling were applied to improve the performance of our models. Machine learning techniques, such as Artificial Neural Network (ANN), XGBoost, and Random Forest, were employed to develop predictive models for ICU readmission risk. Model performance was evaluated using metrics such as AUROC, accuracy, sensitivity, and specificity. The developed models demonstrated robust predictive accuracy for ICU readmission in ICH patients, with key predictors including demographic information, clinical parameters, and laboratory measurements. Our study provides a predictive framework for ICU readmission risk in ICH patients, which can aid in clinical decision-making and improve resource allocation in intensive care settings.
Utilizing Machine Learning Models to Predict Acute Kidney Injury in Septic Patients from MIMIC-III Database
Dec 04, 2024Sepsis is a severe condition that causes the body to respond incorrectly to an infection. This reaction can subsequently cause organ failure, a major one being acute kidney injury (AKI). For septic patients, approximately 50% develop AKI, with a mortality rate above 40%. Creating models that can accurately predict AKI based on specific qualities of septic patients is crucial for early detection and intervention. Using medical data from septic patients during intensive care unit (ICU) admission from the Medical Information Mart for Intensive Care 3 (MIMIC-III) database, we extracted 3301 patients with sepsis, with 73% of patients developing AKI. The data was randomly divided into a training set (n = 1980, 40%), a test set (n = 661, 10%), and a validation set (n = 660, 50%). The proposed model was logistic regression, and it was compared against five baseline models: XGBoost, K Nearest Neighbors (KNN), Support Vector Machines (SVM), Random Forest (RF), and LightGBM. Area Under the Curve (AUC), Accuracy, F1-Score, and Recall were calculated for each model. After analysis, we were able to select 23 features to include in our model, the top features being urine output, maximum bilirubin, minimum bilirubin, weight, maximum blood urea nitrogen, and minimum estimated glomerular filtration rate. The logistic regression model performed the best, achieving an AUC score of 0.887 (95% CI: [0.861-0.915]), an accuracy of 0.817, an F1 score of 0.866, a recall score of 0.827, and a Brier score of 0.13. Compared to the best existing literature in this field, our model achieved an 8.57% improvement in AUC while using 13 fewer variables, showcasing its effectiveness in determining AKI in septic patients. While the features selected for predicting AKI in septic patients are similar to previous literature, the top features that influenced our model's performance differ.
Optimizing Mortality Prediction for ICU Heart Failure Patients: Leveraging XGBoost and Advanced Machine Learning with the MIMIC-III Database
Sep 03, 2024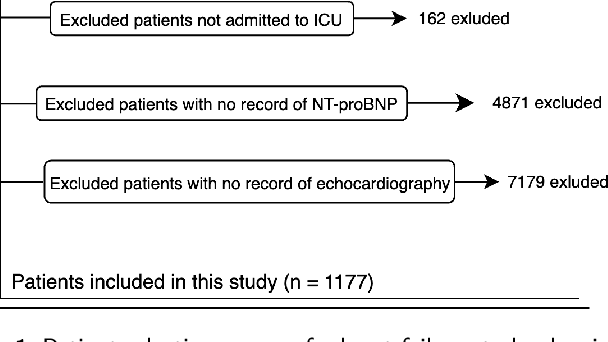
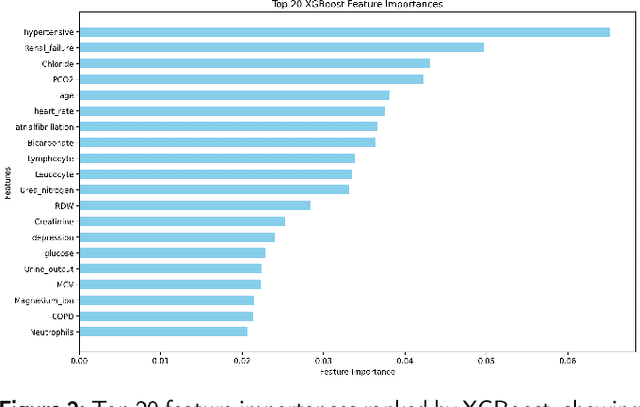
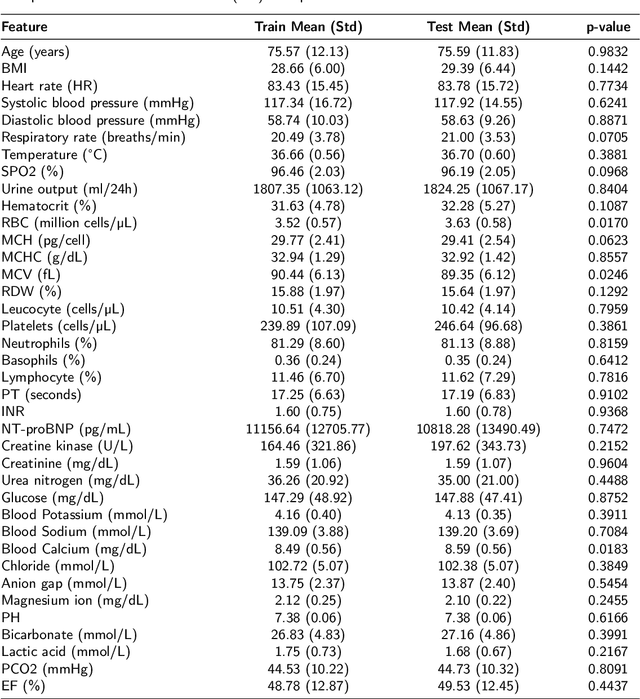
Heart failure affects millions of people worldwide, significantly reducing quality of life and leading to high mortality rates. Despite extensive research, the relationship between heart failure and mortality rates among ICU patients is not fully understood, indicating the need for more accurate prediction models. This study analyzed data from 1,177 patients over 18 years old from the MIMIC-III database, identified using ICD-9 codes. Preprocessing steps included handling missing data, removing duplicates, treating skewness, and using oversampling techniques to address data imbalances. Through rigorous feature selection using Variance Inflation Factor (VIF), expert clinical input, and ablation studies, 46 key features were identified to enhance model performance. Our analysis compared several machine learning models, including Logistic Regression, Support Vector Machine (SVM), Random Forest, LightGBM, and XGBoost. XGBoost emerged as the superior model, achieving a test AUC-ROC of 0.9228 (95\% CI 0.8748 - 0.9613), significantly outperforming our previous work (AUC-ROC of 0.8766) and the best results reported in existing literature (AUC-ROC of 0.824). The improved model's success is attributed to advanced feature selection methods, robust preprocessing techniques, and comprehensive hyperparameter optimization through Grid-Search. SHAP analysis and feature importance evaluations based on XGBoost highlighted key variables like leucocyte count and RDW, providing valuable insights into the clinical factors influencing mortality risk. This framework offers significant support for clinicians, enabling them to identify high-risk ICU heart failure patients and improve patient outcomes through timely and informed interventions.
Data-Driven Machine Learning Approaches for Predicting In-Hospital Sepsis Mortality
Aug 03, 2024



Background: Sepsis is a severe condition responsible for many deaths worldwide. Accurate prediction of sepsis outcomes is crucial for timely and effective treatment. Although previous studies have used ML to forecast outcomes, they faced limitations in feature selection and model comprehensibility, resulting in less effective predictions. Thus, this research aims to develop an interpretable and accurate ML model to help clinical professionals predict in-hospital mortality. Methods: We analyzed ICU patient records from the MIMIC-III database based on specific criteria and extracted relevant data. Our feature selection process included a literature review, clinical input refinement, and using Random Forest to select the top 35 features. We performed data preprocessing, including cleaning, imputation, standardization, and applied SMOTE for oversampling to address imbalance, resulting in 4,683 patients, with admission counts of 17,429. We compared the performance of Random Forest, Gradient Boosting, Logistic Regression, SVM, and KNN models. Results: The Random Forest model was the most effective in predicting sepsis-related in-hospital mortality. It outperformed other models, achieving an accuracy of 0.90 and an AUROC of 0.97, significantly better than the existing literature. Our meticulous feature selection contributed to the model's precision and identified critical determinants of sepsis mortality. These results underscore the pivotal role of data-driven ML in healthcare, especially for predicting in-hospital mortality due to sepsis. Conclusion: This study represents a significant advancement in predicting in-hospital sepsis mortality, highlighting the potential of ML in healthcare. The implications are profound, offering a data-driven approach that enhances decision-making in patient care and reduces in-hospital mortality.
Enhanced Prediction of Ventilator-Associated Pneumonia in Patients with Traumatic Brain Injury Using Advanced Machine Learning Techniques
Aug 02, 2024Background: Ventilator-associated pneumonia (VAP) in traumatic brain injury (TBI) patients poses a significant mortality risk and imposes a considerable financial burden on patients and healthcare systems. Timely detection and prognostication of VAP in TBI patients are crucial to improve patient outcomes and alleviate the strain on healthcare resources. Methods: We implemented six machine learning models using the MIMIC-III database. Our methodology included preprocessing steps, such as feature selection with CatBoost and expert opinion, addressing class imbalance with the Synthetic Minority Oversampling Technique (SMOTE), and rigorous model tuning through 5-fold cross-validation to optimize hyperparameters. Key models evaluated included SVM, Logistic Regression, Random Forest, XGBoost, ANN, and AdaBoost. Additionally, we conducted SHAP analysis to determine feature importance and performed an ablation study to assess feature impacts on model performance. Results: XGBoost outperformed the baseline models and the best existing literature. We used metrics, including AUC, Accuracy, Specificity, Sensitivity, F1 Score, PPV, and NPV. XGBoost demonstrated the highest performance with an AUC of 0.940 and an Accuracy of 0.875, which are 23.4% and 23.5% higher than the best results in the existing literature, with an AUC of 0.706 and an Accuracy of 0.640, respectively. This enhanced performance underscores the models' effectiveness in clinical settings. Conclusions: This study enhances the predictive modeling of VAP in TBI patients, improving early detection and intervention potential. Refined feature selection and advanced ensemble techniques significantly boosted model accuracy and reliability, offering promising directions for future clinical applications and medical diagnostics research.
Enhanced Mortality Prediction in ICU Stroke Patients via Deep Learning
Jul 19, 2024



Background: Stroke is second-leading cause of disability and death among adults. Approximately 17 million people suffer from a stroke annually, with about 85% being ischemic strokes. Predicting mortality of ischemic stroke patients in intensive care unit (ICU) is crucial for optimizing treatment strategies, allocating resources, and improving survival rates. Methods: We acquired data on ICU ischemic stroke patients from MIMIC-IV database, including diagnoses, vital signs, laboratory tests, medications, procedures, treatments, and clinical notes. Stroke patients were randomly divided into training (70%, n=2441), test (15%, n=523), and validation (15%, n=523) sets. To address data imbalances, we applied Synthetic Minority Over-sampling Technique (SMOTE). We selected 30 features for model development, significantly reducing feature number from 1095 used in the best study. We developed a deep learning model to assess mortality risk and implemented several baseline machine learning models for comparison. Results: XGB-DL model, combining XGBoost for feature selection and deep learning, effectively minimized false positives. Model AUROC improved from 0.865 (95% CI: 0.821 - 0.905) on first day to 0.903 (95% CI: 0.868 - 0.936) by fourth day using data from 3,646 ICU mortality patients in the MIMIC-IV database with 0.945 AUROC (95% CI: 0.944 - 0.947) during training. Although other ML models also performed well in terms of AUROC, we chose Deep Learning for its higher specificity. Conclusions: Through enhanced feature selection and data cleaning, proposed model demonstrates a 13% AUROC improvement compared to existing models while reducing feature number from 1095 in previous studies to 30.