 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUMI-Bench 1.0: An Open and Reproducible Real-World Benchmark for Tabletop Robotic Manipulation with UMI Data
Jun 09, 2026Real-robot evaluation is essential for understanding whether learned manipulation policies can operate reliably outside curated demonstrations. This need is particularly pressing for Universal Manipulation Interface (UMI)-style policies, whose performance depends on the coupling between wrist-view observations, action representation, data collection, and physical deployment. Existing real-world benchmarks have made important progress, but they are not designed around this UMI data-to-deployment setting. We present UMI-Bench 1.0, a local-first real-robot benchmark for standardized evaluation of UMI-style manipulation policies. To the best of our knowledge, this is the first benchmark dedicated to real-world evaluation of UMI-based manipulation models. UMI-Bench aligns data collection, scene reset, policy execution, result logging, and task-factor analysis within a unified protocol. By making the full evaluation process reproducible and auditable, UMI-Bench provides a practical testbed for measuring how UMI-trained policies generalize to real physical manipulation.
ACD: Direct Conditional Control for Video Diffusion Models via Attention Supervision
Dec 24, 2025Controllability is a fundamental requirement in video synthesis, where accurate alignment with conditioning signals is essential. Existing classifier-free guidance methods typically achieve conditioning indirectly by modeling the joint distribution of data and conditions, which often results in limited controllability over the specified conditions. Classifier-based guidance enforces conditions through an external classifier, but the model may exploit this mechanism to raise the classifier score without genuinely satisfying the intended condition, resulting in adversarial artifacts and limited effective controllability. In this paper, we propose Attention-Conditional Diffusion (ACD), a novel framework for direct conditional control in video diffusion models via attention supervision. By aligning the model's attention maps with external control signals, ACD achieves better controllability. To support this, we introduce a sparse 3D-aware object layout as an efficient conditioning signal, along with a dedicated Layout ControlNet and an automated annotation pipeline for scalable layout integration. Extensive experiments on benchmark video generation datasets demonstrate that ACD delivers superior alignment with conditioning inputs while preserving temporal coherence and visual fidelity, establishing an effective paradigm for conditional video synthesis.
Utilizing Machine Learning Models to Predict Acute Kidney Injury in Septic Patients from MIMIC-III Database
Dec 04, 2024Sepsis is a severe condition that causes the body to respond incorrectly to an infection. This reaction can subsequently cause organ failure, a major one being acute kidney injury (AKI). For septic patients, approximately 50% develop AKI, with a mortality rate above 40%. Creating models that can accurately predict AKI based on specific qualities of septic patients is crucial for early detection and intervention. Using medical data from septic patients during intensive care unit (ICU) admission from the Medical Information Mart for Intensive Care 3 (MIMIC-III) database, we extracted 3301 patients with sepsis, with 73% of patients developing AKI. The data was randomly divided into a training set (n = 1980, 40%), a test set (n = 661, 10%), and a validation set (n = 660, 50%). The proposed model was logistic regression, and it was compared against five baseline models: XGBoost, K Nearest Neighbors (KNN), Support Vector Machines (SVM), Random Forest (RF), and LightGBM. Area Under the Curve (AUC), Accuracy, F1-Score, and Recall were calculated for each model. After analysis, we were able to select 23 features to include in our model, the top features being urine output, maximum bilirubin, minimum bilirubin, weight, maximum blood urea nitrogen, and minimum estimated glomerular filtration rate. The logistic regression model performed the best, achieving an AUC score of 0.887 (95% CI: [0.861-0.915]), an accuracy of 0.817, an F1 score of 0.866, a recall score of 0.827, and a Brier score of 0.13. Compared to the best existing literature in this field, our model achieved an 8.57% improvement in AUC while using 13 fewer variables, showcasing its effectiveness in determining AKI in septic patients. While the features selected for predicting AKI in septic patients are similar to previous literature, the top features that influenced our model's performance differ.
Cold & Warm Net: Addressing Cold-Start Users in Recommender Systems
Sep 27, 2023Cold-start recommendation is one of the major challenges faced by recommender systems (RS). Herein, we focus on the user cold-start problem. Recently, methods utilizing side information or meta-learning have been used to model cold-start users. However, it is difficult to deploy these methods to industrial RS. There has not been much research that pays attention to the user cold-start problem in the matching stage. In this paper, we propose Cold & Warm Net based on expert models who are responsible for modeling cold-start and warm-up users respectively. A gate network is applied to incorporate the results from two experts. Furthermore, dynamic knowledge distillation acting as a teacher selector is introduced to assist experts in better learning user representation. With comprehensive mutual information, features highly relevant to user behavior are selected for the bias net which explicitly models user behavior bias. Finally, we evaluate our Cold & Warm Net on public datasets in comparison to models commonly applied in the matching stage and it outperforms other models on all user types. The proposed model has also been deployed on an industrial short video platform and achieves a significant increase in app dwell time and user retention rate.
Robust One Round Federated Learning with Predictive Space Bayesian Inference
Jun 20, 2022


Making predictions robust is an important challenge. A separate challenge in federated learning (FL) is to reduce the number of communication rounds, particularly since doing so reduces performance in heterogeneous data settings. To tackle both issues, we take a Bayesian perspective on the problem of learning a global model. We show how the global predictive posterior can be approximated using client predictive posteriors. This is unlike other works which aggregate the local model space posteriors into the global model space posterior, and are susceptible to high approximation errors due to the posterior's high dimensional multimodal nature. In contrast, our method performs the aggregation on the predictive posteriors, which are typically easier to approximate owing to the low-dimensionality of the output space. We present an algorithm based on this idea, which performs MCMC sampling at each client to obtain an estimate of the local posterior, and then aggregates these in one round to obtain a global ensemble model. Through empirical evaluation on several classification and regression tasks, we show that despite using one round of communication, the method is competitive with other FL techniques, and outperforms them on heterogeneous settings. The code is publicly available at https://github.com/hasanmohsin/FedPredSpace_1Round.
Arithmetic addition of two integers by deep image classification networks: experiments to quantify their autonomous reasoning ability
Dec 10, 2019
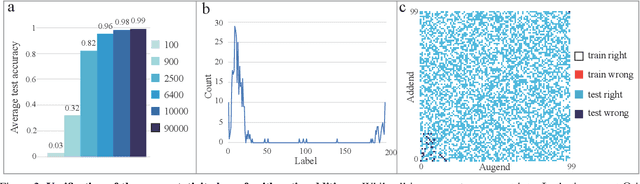
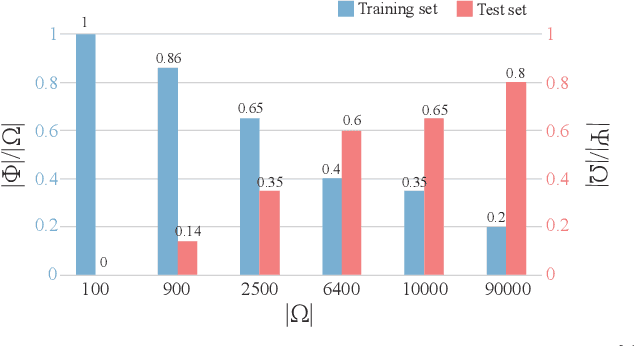
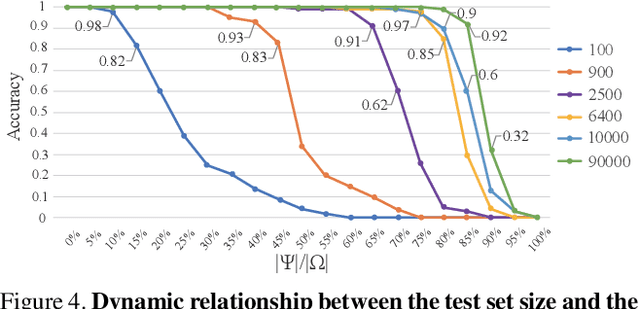
The unprecedented performance achieved by deep convolutional neural networks for image classification is linked primarily to their ability of capturing rich structural features at various layers within networks. Here we design a series of experiments, inspired by children's learning of the arithmetic addition of two integers, to showcase that such deep networks can go beyond the structural features to learn deeper knowledge. In our experiments, a set of images is constructed, each image containing an arithmetic addition $n+m$ in its central area, and several classification networks are then trained over a subset of images, using the sum as the label. Tests on the excluded images show that, as the image set gets larger, the networks have well learnt the law of arithmetic additions so as to build up their autonomous reasoning ability strongly. For instance, networks trained over a small percentage of images can classify a big majority of the remaining images correctly, and many arithmetic additions involving some integers that have never been seen during the training can also be solved correctly by the trained networks.