 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAW-Flow: Advancing RGB-to-RAW Image Reconstruction with Deterministic Latent Flow Matching
Jan 28, 2026RGB-to-RAW reconstruction, or the reverse modeling of a camera Image Signal Processing (ISP) pipeline, aims to recover high-fidelity RAW data from RGB images. Despite notable progress, existing learning-based methods typically treat this task as a direct regression objective and struggle with detail inconsistency and color deviation, due to the ill-posed nature of inverse ISP and the inherent information loss in quantized RGB images. To address these limitations, we pioneer a generative perspective by reformulating RGB-to-RAW reconstruction as a deterministic latent transport problem and introduce a novel framework named RAW-Flow, which leverages flow matching to learn a deterministic vector field in latent space, to effectively bridge the gap between RGB and RAW representations and enable accurate reconstruction of structural details and color information. To further enhance latent transport, we introduce a cross-scale context guidance module that injects hierarchical RGB features into the flow estimation process. Moreover, we design a dual-domain latent autoencoder with a feature alignment constraint to support the proposed latent transport framework, which jointly encodes RGB and RAW inputs while promoting stable training and high-fidelity reconstruction. Extensive experiments demonstrate that RAW-Flow outperforms state-of-the-art approaches both quantitatively and visually.
Blind-Spot Guided Diffusion for Self-supervised Real-World Denoising
Sep 19, 2025In this work, we present Blind-Spot Guided Diffusion, a novel self-supervised framework for real-world image denoising. Our approach addresses two major challenges: the limitations of blind-spot networks (BSNs), which often sacrifice local detail and introduce pixel discontinuities due to spatial independence assumptions, and the difficulty of adapting diffusion models to self-supervised denoising. We propose a dual-branch diffusion framework that combines a BSN-based diffusion branch, generating semi-clean images, with a conventional diffusion branch that captures underlying noise distributions. To enable effective training without paired data, we use the BSN-based branch to guide the sampling process, capturing noise structure while preserving local details. Extensive experiments on the SIDD and DND datasets demonstrate state-of-the-art performance, establishing our method as a highly effective self-supervised solution for real-world denoising. Code and pre-trained models are released at: https://github.com/Sumching/BSGD.
Estimating 2D Camera Motion with Hybrid Motion Basis
Jul 30, 2025Estimating 2D camera motion is a fundamental computer vision task that models the projection of 3D camera movements onto the 2D image plane. Current methods rely on either homography-based approaches, limited to planar scenes, or meshflow techniques that use grid-based local homographies but struggle with complex non-linear transformations. A key insight of our work is that combining flow fields from different homographies creates motion patterns that cannot be represented by any single homography. We introduce CamFlow, a novel framework that represents camera motion using hybrid motion bases: physical bases derived from camera geometry and stochastic bases for complex scenarios. Our approach includes a hybrid probabilistic loss function based on the Laplace distribution that enhances training robustness. For evaluation, we create a new benchmark by masking dynamic objects in existing optical flow datasets to isolate pure camera motion. Experiments show CamFlow outperforms state-of-the-art methods across diverse scenarios, demonstrating superior robustness and generalization in zero-shot settings. Code and datasets are available at our project page: https://lhaippp.github.io/CamFlow/.
Hand-Shadow Poser
May 11, 2025



Hand shadow art is a captivating art form, creatively using hand shadows to reproduce expressive shapes on the wall. In this work, we study an inverse problem: given a target shape, find the poses of left and right hands that together best produce a shadow resembling the input. This problem is nontrivial, since the design space of 3D hand poses is huge while being restrictive due to anatomical constraints. Also, we need to attend to the input's shape and crucial features, though the input is colorless and textureless. To meet these challenges, we design Hand-Shadow Poser, a three-stage pipeline, to decouple the anatomical constraints (by hand) and semantic constraints (by shadow shape): (i) a generative hand assignment module to explore diverse but reasonable left/right-hand shape hypotheses; (ii) a generalized hand-shadow alignment module to infer coarse hand poses with a similarity-driven strategy for selecting hypotheses; and (iii) a shadow-feature-aware refinement module to optimize the hand poses for physical plausibility and shadow feature preservation. Further, we design our pipeline to be trainable on generic public hand data, thus avoiding the need for any specialized training dataset. For method validation, we build a benchmark of 210 diverse shadow shapes of varying complexity and a comprehensive set of metrics, including a novel DINOv2-based evaluation metric. Through extensive comparisons with multiple baselines and user studies, our approach is demonstrated to effectively generate bimanual hand poses for a large variety of hand shapes for over 85% of the benchmark cases.
StableMotion: Repurposing Diffusion-Based Image Priors for Motion Estimation
May 10, 2025



We present StableMotion, a novel framework leverages knowledge (geometry and content priors) from pretrained large-scale image diffusion models to perform motion estimation, solving single-image-based image rectification tasks such as Stitched Image Rectangling (SIR) and Rolling Shutter Correction (RSC). Specifically, StableMotion framework takes text-to-image Stable Diffusion (SD) models as backbone and repurposes it into an image-to-motion estimator. To mitigate inconsistent output produced by diffusion models, we propose Adaptive Ensemble Strategy (AES) that consolidates multiple outputs into a cohesive, high-fidelity result. Additionally, we present the concept of Sampling Steps Disaster (SSD), the counterintuitive scenario where increasing the number of sampling steps can lead to poorer outcomes, which enables our framework to achieve one-step inference. StableMotion is verified on two image rectification tasks and delivers state-of-the-art performance in both, as well as showing strong generalizability. Supported by SSD, StableMotion offers a speedup of 200 times compared to previous diffusion model-based methods.
StabStitch++: Unsupervised Online Video Stitching with Spatiotemporal Bidirectional Warps
May 08, 2025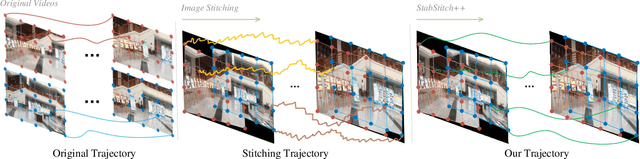
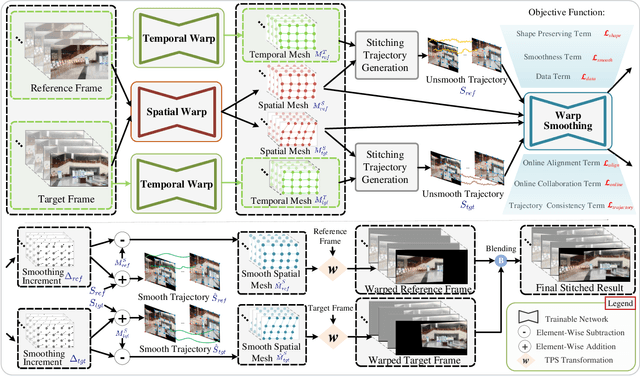
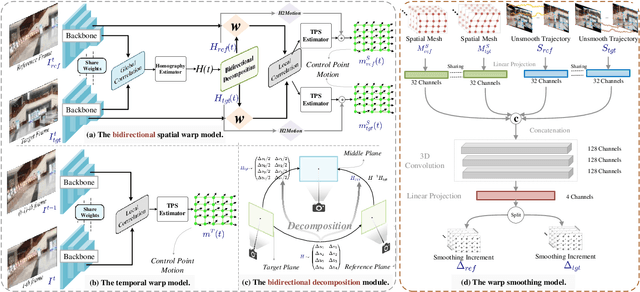
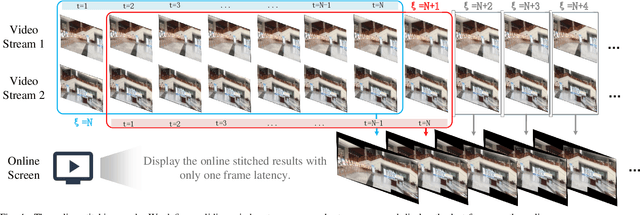
We retarget video stitching to an emerging issue, named warping shake, which unveils the temporal content shakes induced by sequentially unsmooth warps when extending image stitching to video stitching. Even if the input videos are stable, the stitched video can inevitably cause undesired warping shakes and affect the visual experience. To address this issue, we propose StabStitch++, a novel video stitching framework to realize spatial stitching and temporal stabilization with unsupervised learning simultaneously. First, different from existing learning-based image stitching solutions that typically warp one image to align with another, we suppose a virtual midplane between original image planes and project them onto it. Concretely, we design a differentiable bidirectional decomposition module to disentangle the homography transformation and incorporate it into our spatial warp, evenly spreading alignment burdens and projective distortions across two views. Then, inspired by camera paths in video stabilization, we derive the mathematical expression of stitching trajectories in video stitching by elaborately integrating spatial and temporal warps. Finally, a warp smoothing model is presented to produce stable stitched videos with a hybrid loss to simultaneously encourage content alignment, trajectory smoothness, and online collaboration. Compared with StabStitch that sacrifices alignment for stabilization, StabStitch++ makes no compromise and optimizes both of them simultaneously, especially in the online mode. To establish an evaluation benchmark and train the learning framework, we build a video stitching dataset with a rich diversity in camera motions and scenes. Experiments exhibit that StabStitch++ surpasses current solutions in stitching performance, robustness, and efficiency, offering compelling advancements in this field by building a real-time online video stitching system.
Coding-Prior Guided Diffusion Network for Video Deblurring
Apr 16, 2025While recent video deblurring methods have advanced significantly, they often overlook two valuable prior information: (1) motion vectors (MVs) and coding residuals (CRs) from video codecs, which provide efficient inter-frame alignment cues, and (2) the rich real-world knowledge embedded in pre-trained diffusion generative models. We present CPGDNet, a novel two-stage framework that effectively leverages both coding priors and generative diffusion priors for high-quality deblurring. First, our coding-prior feature propagation (CPFP) module utilizes MVs for efficient frame alignment and CRs to generate attention masks, addressing motion inaccuracies and texture variations. Second, a coding-prior controlled generation (CPC) module network integrates coding priors into a pretrained diffusion model, guiding it to enhance critical regions and synthesize realistic details. Experiments demonstrate our method achieves state-of-the-art perceptual quality with up to 30% improvement in IQA metrics. Both the code and the codingprior-augmented dataset will be open-sourced.
CodingHomo: Bootstrapping Deep Homography With Video Coding
Apr 16, 2025Homography estimation is a fundamental task in computer vision with applications in diverse fields. Recent advances in deep learning have improved homography estimation, particularly with unsupervised learning approaches, offering increased robustness and generalizability. However, accurately predicting homography, especially in complex motions, remains a challenge. In response, this work introduces a novel method leveraging video coding, particularly by harnessing inherent motion vectors (MVs) present in videos. We present CodingHomo, an unsupervised framework for homography estimation. Our framework features a Mask-Guided Fusion (MGF) module that identifies and utilizes beneficial features among the MVs, thereby enhancing the accuracy of homography prediction. Additionally, the Mask-Guided Homography Estimation (MGHE) module is presented for eliminating undesired features in the coarse-to-fine homography refinement process. CodingHomo outperforms existing state-of-the-art unsupervised methods, delivering good robustness and generalizability. The code and dataset are available at: \href{github}{https://github.com/liuyike422/CodingHomo
ISPDiffuser: Learning RAW-to-sRGB Mappings with Texture-Aware Diffusion Models and Histogram-Guided Color Consistency
Mar 25, 2025



RAW-to-sRGB mapping, or the simulation of the traditional camera image signal processor (ISP), aims to generate DSLR-quality sRGB images from raw data captured by smartphone sensors. Despite achieving comparable results to sophisticated handcrafted camera ISP solutions, existing learning-based methods still struggle with detail disparity and color distortion. In this paper, we present ISPDiffuser, a diffusion-based decoupled framework that separates the RAW-to-sRGB mapping into detail reconstruction in grayscale space and color consistency mapping from grayscale to sRGB. Specifically, we propose a texture-aware diffusion model that leverages the generative ability of diffusion models to focus on local detail recovery, in which a texture enrichment loss is further proposed to prompt the diffusion model to generate more intricate texture details. Subsequently, we introduce a histogram-guided color consistency module that utilizes color histogram as guidance to learn precise color information for grayscale to sRGB color consistency mapping, with a color consistency loss designed to constrain the learned color information. Extensive experimental results show that the proposed ISPDiffuser outperforms state-of-the-art competitors both quantitatively and visually. The code is available at https://github.com/RenYangSCU/ISPDiffuser.
Learning Hazing to Dehazing: Towards Realistic Haze Generation for Real-World Image Dehazing
Mar 25, 2025Existing real-world image dehazing methods primarily attempt to fine-tune pre-trained models or adapt their inference procedures, thus heavily relying on the pre-trained models and associated training data. Moreover, restoring heavily distorted information under dense haze requires generative diffusion models, whose potential in dehazing remains underutilized partly due to their lengthy sampling processes. To address these limitations, we introduce a novel hazing-dehazing pipeline consisting of a Realistic Hazy Image Generation framework (HazeGen) and a Diffusion-based Dehazing framework (DiffDehaze). Specifically, HazeGen harnesses robust generative diffusion priors of real-world hazy images embedded in a pre-trained text-to-image diffusion model. By employing specialized hybrid training and blended sampling strategies, HazeGen produces realistic and diverse hazy images as high-quality training data for DiffDehaze. To alleviate the inefficiency and fidelity concerns associated with diffusion-based methods, DiffDehaze adopts an Accelerated Fidelity-Preserving Sampling process (AccSamp). The core of AccSamp is the Tiled Statistical Alignment Operation (AlignOp), which can provide a clean and faithful dehazing estimate within a small fraction of sampling steps to reduce complexity and enable effective fidelity guidance. Extensive experiments demonstrate the superior dehazing performance and visual quality of our approach over existing methods. The code is available at https://github.com/ruiyi-w/Learning-Hazing-to-Dehazing.