 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Velocity Deficit: Initial Energy Injection for Flow Matching
May 14, 2026While Flow Matching theoretically guarantees constant-velocity trajectories, we identify a critical breakdown in high-dimensional practice: the Velocity Deficit. We show that the MSE objective systematically underestimates velocity magnitude, causing generated samples to fail to reach the data manifold-a phenomenon we term Integration Lag. To rectify this, we propose Initial Energy Injection, instantiated via two complementary methods: the training-based Magnitude-Aware Flow Matching (MAFM) and the training-free Scale Schedule Corrector (SSC). Both are grounded in our discovery of a crucial asymmetry: velocity contraction causes harmful kinetic stagnation at the trajectory's start, yet acts as a beneficial denoising mechanism at its end. Empirically, SSC yields significant efficiency gains with zero retraining and just one line of code. On ImageNet-1k (256x256), it improves FID by 44.6% (from 13.68 to 7.58) and achieves a 5x speedup, enabling a 50-step generator (FID 7.58) to beat a 250-step baseline (FID 8.65). Furthermore, our methods generalize to Text-to-Image tasks and high-resolution generation, improving FID on MS-COCO by ~22%.
NTIRE 2026 Challenge on Video Saliency Prediction: Methods and Results
Apr 16, 2026This paper presents an overview of the NTIRE 2026 Challenge on Video Saliency Prediction. The goal of the challenge participants was to develop automatic saliency map prediction methods for the provided video sequences. The novel dataset of 2,000 diverse videos with an open license was prepared for this challenge. The fixations and corresponding saliency maps were collected using crowdsourced mouse tracking and contain viewing data from over 5,000 assessors. Evaluation was performed on a subset of 800 test videos using generally accepted quality metrics. The challenge attracted over 20 teams making submissions, and 7 teams passed the final phase with code review. All data used in this challenge is made publicly available - https://github.com/msu-video-group/NTIRE26_Saliency_Prediction.
Stable Spike: Dual Consistency Optimization via Bitwise AND Operations for Spiking Neural Networks
Mar 12, 2026Although the temporal spike dynamics of spiking neural networks (SNNs) enable low-power temporal pattern capture capabilities, they also incur inherent inconsistencies that severely compromise representation. In this paper, we perform dual consistency optimization via Stable Spike to mitigate this problem, thereby improving the recognition performance of SNNs. With the hardware-friendly ``AND" bit operation, we efficiently decouple the stable spike skeleton from the multi-timestep spike maps, thereby capturing critical semantics while reducing inconsistencies from variable noise spikes. Enforcing the unstable spike maps to converge to the stable spike skeleton significantly improves the inherent consistency across timesteps. Furthermore, we inject amplitude-aware spike noise into the stable spike skeleton to diversify the representations while preserving consistent semantics. The SNN is encouraged to produce perturbation-consistent predictions, thereby contributing to generalization. Extensive experiments across multiple architectures and datasets validate the effectiveness and versatility of our method. In particular, our method significantly advances neuromorphic object recognition under ultra-low latency, improving accuracy by up to 8.33\%. This will help unlock the full power consumption and speed potential of SNNs.
LEDiT: Your Length-Extrapolatable Diffusion Transformer without Positional Encoding
Mar 07, 2025

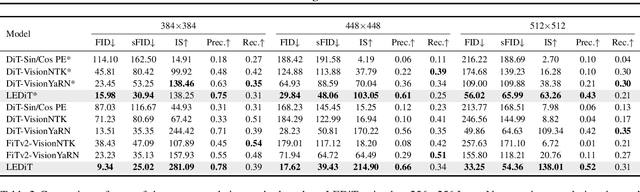
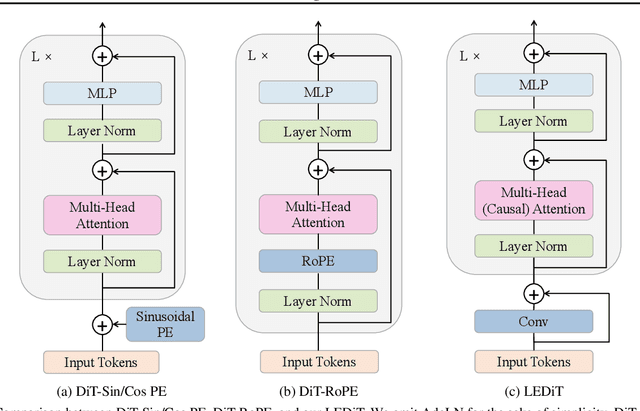
Diffusion transformers(DiTs) struggle to generate images at resolutions higher than their training resolutions. The primary obstacle is that the explicit positional encodings(PE), such as RoPE, need extrapolation which degrades performance when the inference resolution differs from training. In this paper, we propose a Length-Extrapolatable Diffusion Transformer(LEDiT), a simple yet powerful architecture to overcome this limitation. LEDiT needs no explicit PEs, thereby avoiding extrapolation. The key innovations of LEDiT are introducing causal attention to implicitly impart global positional information to tokens, while enhancing locality to precisely distinguish adjacent tokens. Experiments on 256x256 and 512x512 ImageNet show that LEDiT can scale the inference resolution to 512x512 and 1024x1024, respectively, while achieving better image quality compared to current state-of-the-art length extrapolation methods(NTK-aware, YaRN). Moreover, LEDiT achieves strong extrapolation performance with just 100K steps of fine-tuning on a pretrained DiT, demonstrating its potential for integration into existing text-to-image DiTs. Project page: https://shenzhang2145.github.io/ledit/
Optimizing Knowledge Distillation in Transformers: Enabling Multi-Head Attention without Alignment Barriers
Feb 11, 2025Knowledge distillation (KD) in transformers often faces challenges due to misalignment in the number of attention heads between teacher and student models. Existing methods either require identical head counts or introduce projectors to bridge dimensional gaps, limiting flexibility and efficiency. We propose Squeezing-Heads Distillation (SHD), a novel approach that enables seamless knowledge transfer between models with varying head counts by compressing multi-head attention maps via efficient linear approximation. Unlike prior work, SHD eliminates alignment barriers without additional parameters or architectural modifications. Our method dynamically approximates the combined effect of multiple teacher heads into fewer student heads, preserving fine-grained attention patterns while reducing redundancy. Experiments across language (LLaMA, GPT) and vision (DiT, MDT) generative and vision (DeiT) discriminative tasks demonstrate SHD's effectiveness: it outperforms logit-based and feature-alignment KD baselines, achieving state-of-the-art results in image classification, image generation language fine-tuning, and language pre-training. The key innovations of flexible head compression, projector-free design, and linear-time complexity make SHD a versatile and scalable solution for distilling modern transformers. This work bridges a critical gap in KD, enabling efficient deployment of compact models without compromising performance.
MAT: Multi-Range Attention Transformer for Efficient Image Super-Resolution
Nov 26, 2024



Recent advances in image super-resolution (SR) have significantly benefited from the incorporation of Transformer architectures. However, conventional techniques aimed at enlarging the self-attention window to capture broader contexts come with inherent drawbacks, especially the significantly increased computational demands. Moreover, the feature perception within a fixed-size window of existing models restricts the effective receptive fields and the intermediate feature diversity. This study demonstrates that a flexible integration of attention across diverse spatial extents can yield significant performance enhancements. In line with this insight, we introduce Multi-Range Attention Transformer (MAT) tailored for SR tasks. MAT leverages the computational advantages inherent in dilation operation, in conjunction with self-attention mechanism, to facilitate both multi-range attention (MA) and sparse multi-range attention (SMA), enabling efficient capture of both regional and sparse global features. Further coupled with local feature extraction, MAT adeptly capture dependencies across various spatial ranges, improving the diversity and efficacy of its feature representations. We also introduce the MSConvStar module, which augments the model's ability for multi-range representation learning. Comprehensive experiments show that our MAT exhibits superior performance to existing state-of-the-art SR models with remarkable efficiency (~3.3 faster than SRFormer-light).
MegActor-$Σ$: Unlocking Flexible Mixed-Modal Control in Portrait Animation with Diffusion Transformer
Aug 27, 2024


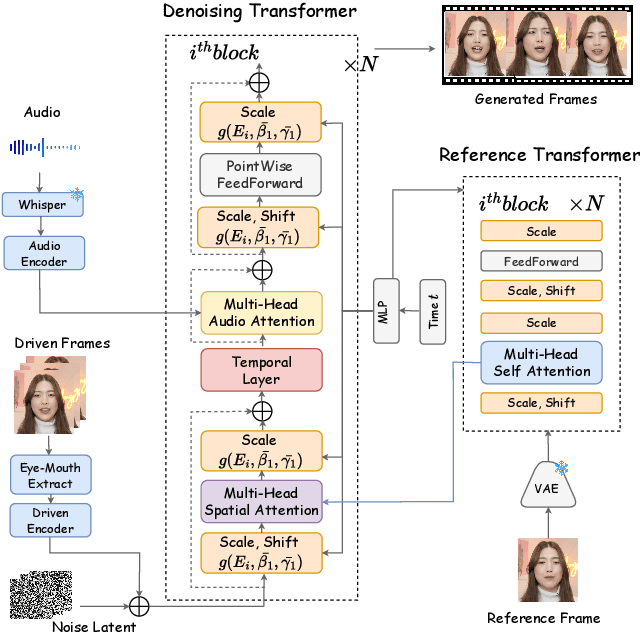
Diffusion models have demonstrated superior performance in the field of portrait animation. However, current approaches relied on either visual or audio modality to control character movements, failing to exploit the potential of mixed-modal control. This challenge arises from the difficulty in balancing the weak control strength of audio modality and the strong control strength of visual modality. To address this issue, we introduce MegActor-$\Sigma$: a mixed-modal conditional diffusion transformer (DiT), which can flexibly inject audio and visual modality control signals into portrait animation. Specifically, we make substantial advancements over its predecessor, MegActor, by leveraging the promising model structure of DiT and integrating audio and visual conditions through advanced modules within the DiT framework. To further achieve flexible combinations of mixed-modal control signals, we propose a ``Modality Decoupling Control" training strategy to balance the control strength between visual and audio modalities, along with the ``Amplitude Adjustment" inference strategy to freely regulate the motion amplitude of each modality. Finally, to facilitate extensive studies in this field, we design several dataset evaluation metrics to filter out public datasets and solely use this filtered dataset to train MegActor-$\Sigma$. Extensive experiments demonstrate the superiority of our approach in generating vivid portrait animations, outperforming previous methods trained on private dataset.
Efficient Single Image Super-Resolution with Entropy Attention and Receptive Field Augmentation
Aug 08, 2024
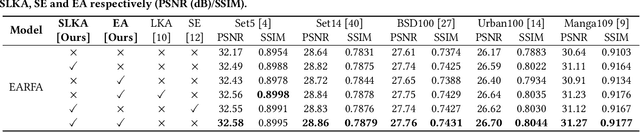

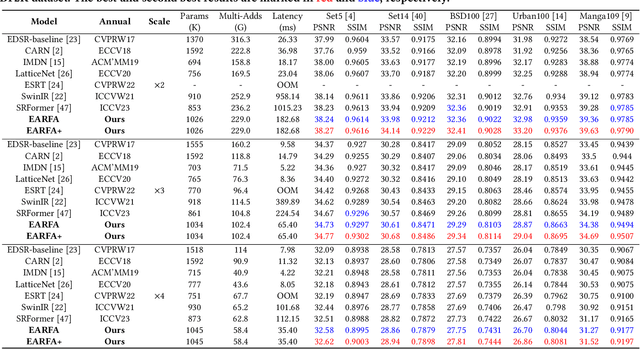
Transformer-based deep models for single image super-resolution (SISR) have greatly improved the performance of lightweight SISR tasks in recent years. However, they often suffer from heavy computational burden and slow inference due to the complex calculation of multi-head self-attention (MSA), seriously hindering their practical application and deployment. In this work, we present an efficient SR model to mitigate the dilemma between model efficiency and SR performance, which is dubbed Entropy Attention and Receptive Field Augmentation network (EARFA), and composed of a novel entropy attention (EA) and a shifting large kernel attention (SLKA). From the perspective of information theory, EA increases the entropy of intermediate features conditioned on a Gaussian distribution, providing more informative input for subsequent reasoning. On the other hand, SLKA extends the receptive field of SR models with the assistance of channel shifting, which also favors to boost the diversity of hierarchical features. Since the implementation of EA and SLKA does not involve complex computations (such as extensive matrix multiplications), the proposed method can achieve faster nonlinear inference than Transformer-based SR models while maintaining better SR performance. Extensive experiments show that the proposed model can significantly reduce the delay of model inference while achieving the SR performance comparable with other advanced models.
Large Kernel Distillation Network for Efficient Single Image Super-Resolution
Jul 19, 2024Efficient and lightweight single-image super-resolution (SISR) has achieved remarkable performance in recent years. One effective approach is the use of large kernel designs, which have been shown to improve the performance of SISR models while reducing their computational requirements. However, current state-of-the-art (SOTA) models still face problems such as high computational costs. To address these issues, we propose the Large Kernel Distillation Network (LKDN) in this paper. Our approach simplifies the model structure and introduces more efficient attention modules to reduce computational costs while also improving performance. Specifically, we employ the reparameterization technique to enhance model performance without adding extra cost. We also introduce a new optimizer from other tasks to SISR, which improves training speed and performance. Our experimental results demonstrate that LKDN outperforms existing lightweight SR methods and achieves SOTA performance.
C2C: Component-to-Composition Learning for Zero-Shot Compositional Action Recognition
Jul 08, 2024



Compositional actions consist of dynamic (verbs) and static (objects) concepts. Humans can easily recognize unseen compositions using the learned concepts. For machines, solving such a problem requires a model to recognize unseen actions composed of previously observed verbs and objects, thus requiring, so-called, compositional generalization ability. To facilitate this research, we propose a novel Zero-Shot Compositional Action Recognition (ZS-CAR) task. For evaluating the task, we construct a new benchmark, Something-composition (Sth-com), based on the widely used Something-Something V2 dataset. We also propose a novel Component-to-Composition (C2C) learning method to solve the new ZS-CAR task. C2C includes an independent component learning module and a composition inference module. Last, we devise an enhanced training strategy to address the challenges of component variation between seen and unseen compositions and to handle the subtle balance between learning seen and unseen actions. The experimental results demonstrate that the proposed framework significantly surpasses the existing compositional generalization methods and sets a new state-of-the-art. The new Sth-com benchmark and code are available at https://github.com/RongchangLi/ZSCAR_C2C.