 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMegActor: Harness the Power of Raw Video for Vivid Portrait Animation
Paper and Code

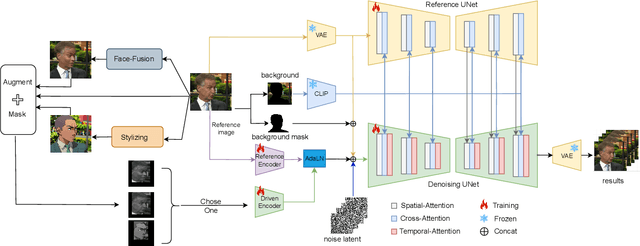


Despite raw driving videos contain richer information on facial expressions than intermediate representations such as landmarks in the field of portrait animation, they are seldom the subject of research. This is due to two challenges inherent in portrait animation driven with raw videos: 1) significant identity leakage; 2) Irrelevant background and facial details such as wrinkles degrade performance. To harnesses the power of the raw videos for vivid portrait animation, we proposed a pioneering conditional diffusion model named as MegActor. First, we introduced a synthetic data generation framework for creating videos with consistent motion and expressions but inconsistent IDs to mitigate the issue of ID leakage. Second, we segmented the foreground and background of the reference image and employed CLIP to encode the background details. This encoded information is then integrated into the network via a text embedding module, thereby ensuring the stability of the background. Finally, we further style transfer the appearance of the reference image to the driving video to eliminate the influence of facial details in the driving videos. Our final model was trained solely on public datasets, achieving results comparable to commercial models. We hope this will help the open-source community.The code is available at https://github.com/megvii-research/MegFaceAnimate.