 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMegActor-$Σ$: Unlocking Flexible Mixed-Modal Control in Portrait Animation with Diffusion Transformer
Aug 27, 2024


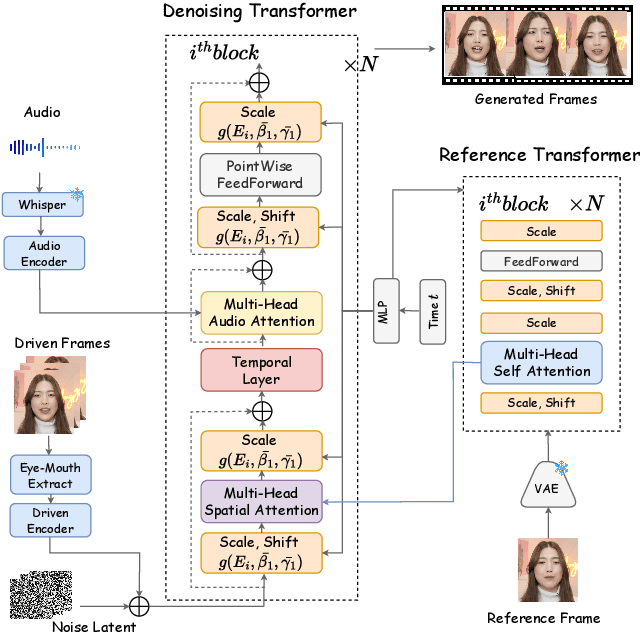
Diffusion models have demonstrated superior performance in the field of portrait animation. However, current approaches relied on either visual or audio modality to control character movements, failing to exploit the potential of mixed-modal control. This challenge arises from the difficulty in balancing the weak control strength of audio modality and the strong control strength of visual modality. To address this issue, we introduce MegActor-$\Sigma$: a mixed-modal conditional diffusion transformer (DiT), which can flexibly inject audio and visual modality control signals into portrait animation. Specifically, we make substantial advancements over its predecessor, MegActor, by leveraging the promising model structure of DiT and integrating audio and visual conditions through advanced modules within the DiT framework. To further achieve flexible combinations of mixed-modal control signals, we propose a ``Modality Decoupling Control" training strategy to balance the control strength between visual and audio modalities, along with the ``Amplitude Adjustment" inference strategy to freely regulate the motion amplitude of each modality. Finally, to facilitate extensive studies in this field, we design several dataset evaluation metrics to filter out public datasets and solely use this filtered dataset to train MegActor-$\Sigma$. Extensive experiments demonstrate the superiority of our approach in generating vivid portrait animations, outperforming previous methods trained on private dataset.
MegActor: Harness the Power of Raw Video for Vivid Portrait Animation
May 31, 2024
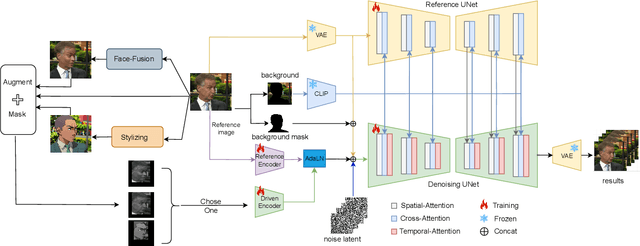


Despite raw driving videos contain richer information on facial expressions than intermediate representations such as landmarks in the field of portrait animation, they are seldom the subject of research. This is due to two challenges inherent in portrait animation driven with raw videos: 1) significant identity leakage; 2) Irrelevant background and facial details such as wrinkles degrade performance. To harnesses the power of the raw videos for vivid portrait animation, we proposed a pioneering conditional diffusion model named as MegActor. First, we introduced a synthetic data generation framework for creating videos with consistent motion and expressions but inconsistent IDs to mitigate the issue of ID leakage. Second, we segmented the foreground and background of the reference image and employed CLIP to encode the background details. This encoded information is then integrated into the network via a text embedding module, thereby ensuring the stability of the background. Finally, we further style transfer the appearance of the reference image to the driving video to eliminate the influence of facial details in the driving videos. Our final model was trained solely on public datasets, achieving results comparable to commercial models. We hope this will help the open-source community.The code is available at https://github.com/megvii-research/MegFaceAnimate.