 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Next: Lexicalizing Modalities as Discrete Tokens
Mar 29, 2026The prevailing Next-Token Prediction (NTP) paradigm has driven the success of large language models through discrete autoregressive modeling. However, contemporary multimodal systems remain language-centric, often treating non-linguistic modalities as external attachments, leading to fragmented architectures and suboptimal integration. To transcend this limitation, we introduce Discrete Native Autoregressive (DiNA), a unified framework that represents multimodal information within a shared discrete space, enabling a consistent and principled autoregressive modeling across modalities. A key innovation is the Discrete Native Any-resolution Visual Transformer (dNaViT), which performs tokenization and de-tokenization at arbitrary resolutions, transforming continuous visual signals into hierarchical discrete tokens. Building on this foundation, we develop LongCat-Next, a native multimodal model that processes text, vision, and audio under a single autoregressive objective with minimal modality-specific design. As an industrial-strength foundation model, it excels at seeing, painting, and talking within a single framework, achieving strong performance across a wide range of multimodal benchmarks. In particular, LongCat-Next addresses the long-standing performance ceiling of discrete vision modeling on understanding tasks and provides a unified approach to effectively reconcile the conflict between understanding and generation. As an attempt toward native multimodality, we open-source the LongCat-Next and its tokenizers, hoping to foster further research and development in the community. GitHub: https://github.com/meituan-longcat/LongCat-Next
UniHetero: Could Generation Enhance Understanding for Vision-Language-Model at Large Data Scale?
Dec 30, 2025Vision-language large models are moving toward the unification of visual understanding and visual generation tasks. However, whether generation can enhance understanding is still under-explored on large data scale. In this work, we analysis the unified structure with a concise model, UniHetero, under large-scale pretraining (>200M samples). Our key observations are: (1) Generation can improve understanding, but Only if you generate Semantics, Not Pixels. A common assumption in unified vision-language models is that adding generation will naturally strengthen understanding. However, this is not always true at scale. At 200M+ pretraining samples, generation helps understanding only when it operates at the semantic level, i.e. when the model learns to autoregress high-level visual representations inside the LLM. Once pixel-level objectives (e.g., diffusion losses) directly interfere with the LLM, understanding performance often degrades. (2) Generation reveals a superior Data Scaling trend and higher Data Utilization. Unified generation-understanding demonstrates a superior scaling trend compared to understanding alone, revealing a more effective way to learn vision-only knowledge directive from vision modality rather than captioning to text. (3) Autoregression on Input Embedding is effective to capture visual details. Compared to the commonly-used vision encoder, make visual autoregression on input embedding shows less cumulative error and is modality independent, which can be extend to all modalities. The learned semantic representations capture visual information such as objects, locations, shapes, and colors; further enable pixel-level image generation.
MegActor-$Σ$: Unlocking Flexible Mixed-Modal Control in Portrait Animation with Diffusion Transformer
Aug 27, 2024


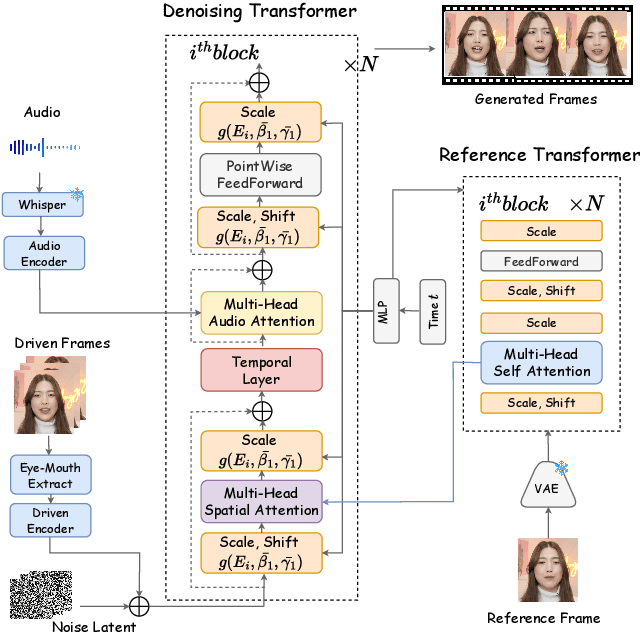
Diffusion models have demonstrated superior performance in the field of portrait animation. However, current approaches relied on either visual or audio modality to control character movements, failing to exploit the potential of mixed-modal control. This challenge arises from the difficulty in balancing the weak control strength of audio modality and the strong control strength of visual modality. To address this issue, we introduce MegActor-$\Sigma$: a mixed-modal conditional diffusion transformer (DiT), which can flexibly inject audio and visual modality control signals into portrait animation. Specifically, we make substantial advancements over its predecessor, MegActor, by leveraging the promising model structure of DiT and integrating audio and visual conditions through advanced modules within the DiT framework. To further achieve flexible combinations of mixed-modal control signals, we propose a ``Modality Decoupling Control" training strategy to balance the control strength between visual and audio modalities, along with the ``Amplitude Adjustment" inference strategy to freely regulate the motion amplitude of each modality. Finally, to facilitate extensive studies in this field, we design several dataset evaluation metrics to filter out public datasets and solely use this filtered dataset to train MegActor-$\Sigma$. Extensive experiments demonstrate the superiority of our approach in generating vivid portrait animations, outperforming previous methods trained on private dataset.
MegActor: Harness the Power of Raw Video for Vivid Portrait Animation
May 31, 2024
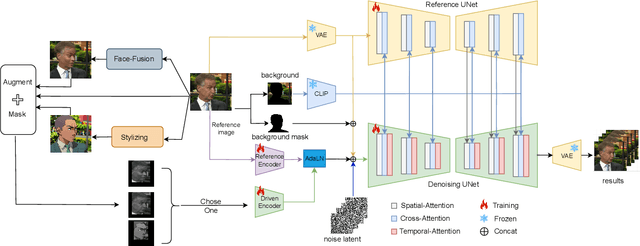


Despite raw driving videos contain richer information on facial expressions than intermediate representations such as landmarks in the field of portrait animation, they are seldom the subject of research. This is due to two challenges inherent in portrait animation driven with raw videos: 1) significant identity leakage; 2) Irrelevant background and facial details such as wrinkles degrade performance. To harnesses the power of the raw videos for vivid portrait animation, we proposed a pioneering conditional diffusion model named as MegActor. First, we introduced a synthetic data generation framework for creating videos with consistent motion and expressions but inconsistent IDs to mitigate the issue of ID leakage. Second, we segmented the foreground and background of the reference image and employed CLIP to encode the background details. This encoded information is then integrated into the network via a text embedding module, thereby ensuring the stability of the background. Finally, we further style transfer the appearance of the reference image to the driving video to eliminate the influence of facial details in the driving videos. Our final model was trained solely on public datasets, achieving results comparable to commercial models. We hope this will help the open-source community.The code is available at https://github.com/megvii-research/MegFaceAnimate.
Towards RGB-NIR Cross-modality Image Registration and Beyond
May 30, 2024



This paper focuses on the area of RGB(visible)-NIR(near-infrared) cross-modality image registration, which is crucial for many downstream vision tasks to fully leverage the complementary information present in visible and infrared images. In this field, researchers face two primary challenges - the absence of a correctly-annotated benchmark with viewpoint variations for evaluating RGB-NIR cross-modality registration methods and the problem of inconsistent local features caused by the appearance discrepancy between RGB-NIR cross-modality images. To address these challenges, we first present the RGB-NIR Image Registration (RGB-NIR-IRegis) benchmark, which, for the first time, enables fair and comprehensive evaluations for the task of RGB-NIR cross-modality image registration. Evaluations of previous methods highlight the significant challenges posed by our RGB-NIR-IRegis benchmark, especially on RGB-NIR image pairs with viewpoint variations. To analyze the causes of the unsatisfying performance, we then design several metrics to reveal the toxic impact of inconsistent local features between visible and infrared images on the model performance. This further motivates us to develop a baseline method named Semantic Guidance Transformer (SGFormer), which utilizes high-level semantic guidance to mitigate the negative impact of local inconsistent features. Despite the simplicity of our motivation, extensive experimental results show the effectiveness of our method.
Sparse Beats Dense: Rethinking Supervision in Radar-Camera Depth Completion
Dec 08, 2023
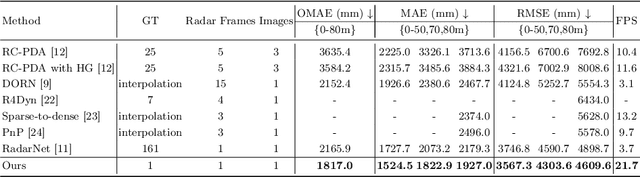


It is widely believed that the dense supervision is better than the sparse supervision in the field of depth completion, but the underlying reasons for this are rarely discussed. In this paper, we find that the challenge of using sparse supervision for training Radar-Camera depth prediction models is the Projection Transformation Collapse (PTC). The PTC implies that sparse supervision leads the model to learn unexpected collapsed projection transformations between Image/Radar/LiDAR spaces. Building on this insight, we propose a novel ``Disruption-Compensation" framework to handle the PTC, thereby relighting the use of sparse supervision in depth completion tasks. The disruption part deliberately discards position correspondences among Image/Radar/LiDAR, while the compensation part leverages 3D spatial and 2D semantic information to compensate for the discarded beneficial position correspondence. Extensive experimental results demonstrate that our framework (sparse supervision) outperforms the state-of-the-art (dense supervision) with 11.6$\%$ improvement in mean absolute error and $1.6 \times$ speedup. The code is available at ...
DarkVisionNet: Low-Light Imaging via RGB-NIR Fusion with Deep Inconsistency Prior
Mar 13, 2023RGB-NIR fusion is a promising method for low-light imaging. However, high-intensity noise in low-light images amplifies the effect of structure inconsistency between RGB-NIR images, which fails existing algorithms. To handle this, we propose a new RGB-NIR fusion algorithm called Dark Vision Net (DVN) with two technical novelties: Deep Structure and Deep Inconsistency Prior (DIP). The Deep Structure extracts clear structure details in deep multiscale feature space rather than raw input space, which is more robust to noisy inputs. Based on the deep structures from both RGB and NIR domains, we introduce the DIP to leverage the structure inconsistency to guide the fusion of RGB-NIR. Benefiting from this, the proposed DVN obtains high-quality lowlight images without the visual artifacts. We also propose a new dataset called Dark Vision Dataset (DVD), consisting of aligned RGB-NIR image pairs, as the first public RGBNIR fusion benchmark. Quantitative and qualitative results on the proposed benchmark show that DVN significantly outperforms other comparison algorithms in PSNR and SSIM, especially in extremely low light conditions.