 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDarkVisionNet: Low-Light Imaging via RGB-NIR Fusion with Deep Inconsistency Prior
Mar 13, 2023RGB-NIR fusion is a promising method for low-light imaging. However, high-intensity noise in low-light images amplifies the effect of structure inconsistency between RGB-NIR images, which fails existing algorithms. To handle this, we propose a new RGB-NIR fusion algorithm called Dark Vision Net (DVN) with two technical novelties: Deep Structure and Deep Inconsistency Prior (DIP). The Deep Structure extracts clear structure details in deep multiscale feature space rather than raw input space, which is more robust to noisy inputs. Based on the deep structures from both RGB and NIR domains, we introduce the DIP to leverage the structure inconsistency to guide the fusion of RGB-NIR. Benefiting from this, the proposed DVN obtains high-quality lowlight images without the visual artifacts. We also propose a new dataset called Dark Vision Dataset (DVD), consisting of aligned RGB-NIR image pairs, as the first public RGBNIR fusion benchmark. Quantitative and qualitative results on the proposed benchmark show that DVN significantly outperforms other comparison algorithms in PSNR and SSIM, especially in extremely low light conditions.
Separable Batch Normalization for Robust Facial Landmark Localization with Cross-protocol Network Training
Jan 17, 2021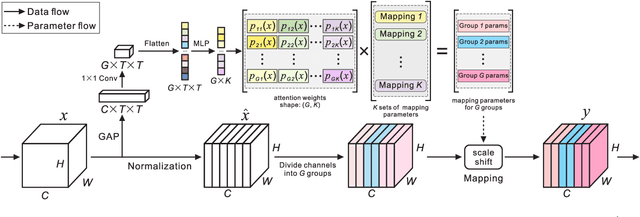
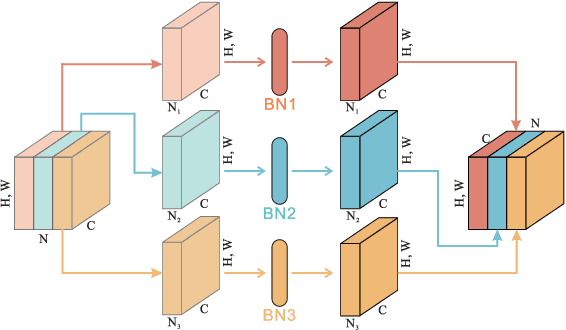
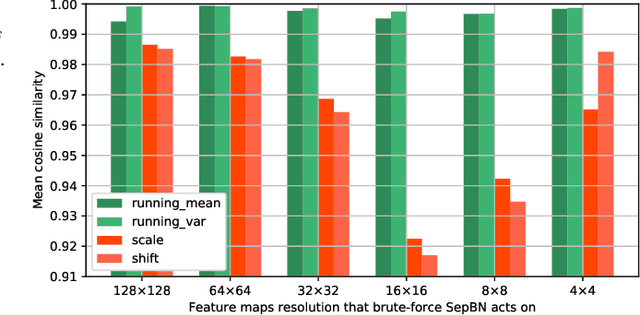
A big, diverse and balanced training data is the key to the success of deep neural network training. However, existing publicly available datasets used in facial landmark localization are usually much smaller than those for other computer vision tasks. A small dataset without diverse and balanced training samples cannot support the training of a deep network effectively. To address the above issues, this paper presents a novel Separable Batch Normalization (SepBN) module with a Cross-protocol Network Training (CNT) strategy for robust facial landmark localization. Different from the standard BN layer that uses all the training data to calculate a single set of parameters, SepBN considers that the samples of a training dataset may belong to different sub-domains. Accordingly, the proposed SepBN module uses multiple sets of parameters, each corresponding to a specific sub-domain. However, the selection of an appropriate branch in the inference stage remains a challenging task because the sub-domain of a test sample is unknown. To mitigate this difficulty, we propose a novel attention mechanism that assigns different weights to each branch for automatic selection in an effective style. As a further innovation, the proposed CNT strategy trains a network using multiple datasets having different facial landmark annotation systems, boosting the performance and enhancing the generalization capacity of the trained network. The experimental results obtained on several well-known datasets demonstrate the effectiveness of the proposed method.