 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Be Multimodal or Not to Be: Query-Adaptive Audio-Visual Person Retrieval via Active Modality Detection
Jun 04, 2026When retrieving a person from a video archive by voice and face, should the system be multimodal or not? In real-world broadcast archives, unlike curated benchmarks, a target may be heard but unseen, seen but unheard, or both. Fusing scores from an absent modality injects noise, degrading precision below the best unimodal system. We propose a query-adaptive framework that detects active modalities via cross-modal score consistency: when both modalities are active, files retrieved by one also score highly on the other; this agreement breaks down when a modality is absent. Classifiers driven by these cross-modal features achieve 89% detection accuracy. On the BBC Rewind corpus (with over 12,000 broadcast videos) the adaptive system attains 94.2% P@1, outperforming speaker-only (82.9%), face-only (93.4%), and fixed fusion (90.0%), recovering 64% of the gap to an oracle with ground-truth modality labels (96.6%).
Paving the Way for Point Cloud Video Representation Learning Using A PDE Model
Jun 01, 2026Investigating spatial-temporal correlations, specifically how spatial points vary over time, is crucial for understanding point cloud videos. Traditional methods, particularly flow-based techniques, struggle with these correlations due to the unordered spatial arrangement of sequential point cloud data. To address this challenge, we propose a novel approach that regularizes spatial-temporal correlation learning by formulating the problem as a solvable Partial Differential Equation (PDE). While PDEs have long been effective in the physical domain, their application to novel sequential data like point cloud video remains underexplored. Inspired by fluid analysis, we construct a simplified PDE, and the process of solving PDE is guided and refined by a contrastive learning structure between the temporal embeddings and the spatial embeddings. With this extra supervision, our method, named MotionPDE, serves as an effective, plug-and-play enhancement module for existing backbone models, adding minimal computational overhead and parameters. Capitalizing on the contrastive learning process, we delve deeper into the self-supervised capabilities of MotionPDE, yielding promising results that underscore its utility and adaptability in point cloud video data interpretation. The code repo with trained checkpoints will be available at https://github.com/zhh6425/motionpde.git for facilitating future research.
Information theoretic underpinning of self-supervised learning by clustering
May 12, 2026Self-supervised learning (SSL) is recognized as an essential tool for building foundation models for Artificial Intelligence applications. The advances in SSL have been made thanks to vigorous arguments about the principles of SSL and through extensive empirical research. The aim of this paper is to contribute to the development of the underpinning theory of SSL, focusing on the deep clustering approach. By analogy to supervised learning, we formulate SSL as K-L divergence optimization. The mode collapse is prevented by imposing an optimisation constraint on the teacher distribution. This leads to normalization using inverse cluster priors. We show that using Jensen inequality this normalization simplifies to the popular batch centering procedure. Distillation and centering are common {heuristics-based} practices in SSL, {but our work underpins them theoretically.} The theoretical model developed not only supports specific existing successful SSL methods, but also suggests directions for future investigations.
EvaNet: Towards More Efficient and Consistent Infrared and Visible Image Fusion Assessment
Apr 03, 2026Evaluation is essential in image fusion research, yet most existing metrics are directly borrowed from other vision tasks without proper adaptation. These traditional metrics, often based on complex image transformations, not only fail to capture the true quality of the fusion results but also are computationally demanding. To address these issues, we propose a unified evaluation framework specifically tailored for image fusion. At its core is a lightweight network designed efficiently to approximate widely used metrics, following a divide-and-conquer strategy. Unlike conventional approaches that directly assess similarity between fused and source images, we first decompose the fusion result into infrared and visible components. The evaluation model is then used to measure the degree of information preservation in these separated components, effectively disentangling the fusion evaluation process. During training, we incorporate a contrastive learning strategy and inform our evaluation model by perceptual scene assessment provided by a large language model. Last, we propose the first consistency evaluation framework, which measures the alignment between image fusion metrics and human visual perception, using both independent no-reference scores and downstream tasks performance as objective references. Extensive experiments show that our learning-based evaluation paradigm delivers both superior efficiency (up to 1,000 times faster) and greater consistency across a range of standard image fusion benchmarks. Our code will be publicly available at https://github.com/AWCXV/EvaNet.
Beyond Strict Pairing: Arbitrarily Paired Training for High-Performance Infrared and Visible Image Fusion
Mar 23, 2026Infrared and visible image fusion(IVIF) combines complementary modalities while preserving natural textures and salient thermal signatures. Existing solutions predominantly rely on extensive sets of rigidly aligned image pairs for training. However, acquiring such data is often impractical due to the costly and labour-intensive alignment process. Besides, maintaining a rigid pairing setting during training restricts the volume of cross-modal relationships, thereby limiting generalisation performance. To this end, this work challenges the necessity of Strictly Paired Training Paradigm (SPTP) by systematically investigating UnPaired and Arbitrarily Paired Training Paradigms (UPTP and APTP) for high-performance IVIF. We establish a theoretical objective of APTP, reflecting the complementary nature between UPTP and SPTP. More importantly, we develop a practical framework capable of significantly enriching cross-modal relationships even with severely limited and unaligned training data. To validate our propositions, three end-to-end lightweight baselines, alongside a set of innovative loss functions, are designed to cover three classic frameworks (CNN, Transformer, GAN). Comprehensive experiments demonstrate that the proposed APTP and UPTP are feasible and capable of training models on a severely limited and content-inconsistent infrared and visible dataset, achieving performance comparable to that of a dataset 100$\times$ larger in SPTP. This finding fundamentally alleviates the cost and difficulty of data collection while enhancing model robustness from the data perspective, delivering a feasible solution for IVIF studies. The code is available at \href{https://github.com/yanglinDeng/IVIF_unpair}{\textcolor{blue}{https://github.com/yanglinDeng/IVIF\_unpair}}.
Learning Progressive Adaptation for Multi-Modal Tracking
Mar 22, 2026Due to the limited availability of paired multi-modal data, multi-modal trackers are typically built by adopting pre-trained RGB models with parameter-efficient fine-tuning modules. However, these fine-tuning methods overlook advanced adaptations for applying RGB pre-trained models and fail to modulate a single specific modality, cross-modal interactions, and the prediction head. To address the issues, we propose to perform Progressive Adaptation for Multi-Modal Tracking (PATrack). This innovative approach incorporates modality-dependent, modality-entangled, and task-level adapters, effectively bridging the gap in adapting RGB pre-trained networks to multi-modal data through a progressive strategy. Specifically, modality-specific information is enhanced through the modality-dependent adapter, decomposing the high- and low-frequency components, which ensures a more robust feature representation within each modality. The inter-modal interactions are introduced in the modality-entangled adapter, which implements a cross-attention operation guided by inter-modal shared information, ensuring the reliability of features conveyed between modalities. Additionally, recognising that the strong inductive bias of the prediction head does not adapt to the fused information, a task-level adapter specific to the prediction head is introduced. In summary, our design integrates intra-modal, inter-modal, and task-level adapters into a unified framework. Extensive experiments on RGB+Thermal, RGB+Depth, and RGB+Event tracking tasks demonstrate that our method shows impressive performance against state-of-the-art methods. Code is available at https://github.com/ouha1998/Learning-Progressive-Adaptation-for-Multi-Modal-Tracking.
Towards Highly Transferable Vision-Language Attack via Semantic-Augmented Dynamic Contrastive Interaction
Mar 05, 2026With the rapid advancement and widespread application of vision-language pre-training (VLP) models, their vulnerability to adversarial attacks has become a critical concern. In general, the adversarial examples can typically be designed to exhibit transferable power, attacking not only different models but also across diverse tasks. However, existing attacks on language-vision models mainly rely on static cross-modal interactions and focus solely on disrupting positive image-text pairs, resulting in limited cross-modal disruption and poor transferability. To address this issue, we propose a Semantic-Augmented Dynamic Contrastive Attack (SADCA) that enhances adversarial transferability through progressive and semantically guided perturbation. SADCA progressively disrupts cross-modal alignment through dynamic interactions between adversarial images and texts. This is accomplished by SADCA establishing a contrastive learning mechanism involving adversarial, positive and negative samples, to reinforce the semantic inconsistency of the obtained perturbations. Moreover, we empirically find that input transformations commonly used in traditional transfer-based attacks also benefit VLPs, which motivates a semantic augmentation module that increases the diversity and generalization of adversarial examples. Extensive experiments on multiple datasets and models demonstrate that SADCA significantly improves adversarial transferability and consistently surpasses state-of-the-art methods. The code is released at https://github.com/LiYuanBoJNU/SADCA.
Multi-Paradigm Collaborative Adversarial Attack Against Multi-Modal Large Language Models
Mar 05, 2026The rapid progress of Multi-Modal Large Language Models (MLLMs) has significantly advanced downstream applications. However, this progress also exposes serious transferable adversarial vulnerabilities. In general, existing adversarial attacks against MLLMs typically rely on surrogate models trained within a single learning paradigm and perform independent optimisation in their respective feature spaces. This straightforward setting naturally restricts the richness of feature representations, delivering limits on the search space and thus impeding the diversity of adversarial perturbations. To address this, we propose a novel Multi-Paradigm Collaborative Attack (MPCAttack) framework to boost the transferability of adversarial examples against MLLMs. In principle, MPCAttack aggregates semantic representations, from both visual images and language texts, to facilitate joint adversarial optimisation on the aggregated features through a Multi-Paradigm Collaborative Optimisation (MPCO) strategy. By performing contrastive matching on multi-paradigm features, MPCO adaptively balances the importance of different paradigm representations and guides the global perturbation optimisation, effectively alleviating the representation bias. Extensive experimental results on multiple benchmarks demonstrate the superiority of MPCAttack, indicating that our solution consistently outperforms state-of-the-art methods in both targeted and untargeted attacks on open-source and closed-source MLLMs. The code is released at https://github.com/LiYuanBoJNU/MPCAttack.
MERGETUNE: Continued fine-tuning of vision-language models
Jan 16, 2026Fine-tuning vision-language models (VLMs) such as CLIP often leads to catastrophic forgetting of pretrained knowledge. Prior work primarily aims to mitigate forgetting during adaptation; however, forgetting often remains inevitable during this process. We introduce a novel paradigm, continued fine-tuning (CFT), which seeks to recover pretrained knowledge after a zero-shot model has already been adapted. We propose a simple, model-agnostic CFT strategy (named MERGETUNE) guided by linear mode connectivity (LMC), which can be applied post hoc to existing fine-tuned models without requiring architectural changes. Given a fine-tuned model, we continue fine-tuning its trainable parameters (e.g., soft prompts or linear heads) to search for a continued model which has two low-loss paths to the zero-shot (e.g., CLIP) and the fine-tuned (e.g., CoOp) solutions. By exploiting the geometry of the loss landscape, the continued model implicitly merges the two solutions, restoring pretrained knowledge lost in the fine-tuned counterpart. A challenge is that the vanilla LMC constraint requires data replay from the pretraining task. We approximate this constraint for the zero-shot model via a second-order surrogate, eliminating the need for large-scale data replay. Experiments show that MERGETUNE improves the harmonic mean of CoOp by +5.6% on base-novel generalisation without adding parameters. On robust fine-tuning evaluations, the LMC-merged model from MERGETUNE surpasses ensemble baselines with lower inference cost, achieving further gains and state-of-the-art results when ensembled with the zero-shot model. Our code is available at https://github.com/Surrey-UP-Lab/MERGETUNE.
Dynamic Avatar-Scene Rendering from Human-centric Context
Nov 13, 2025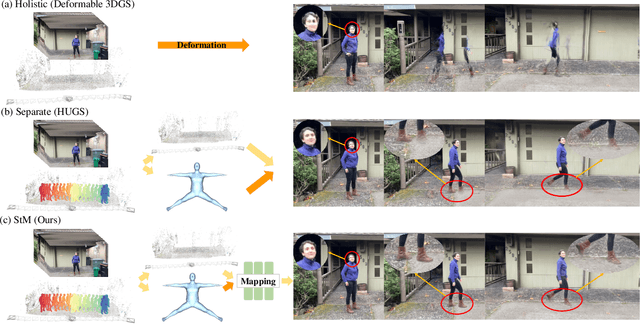
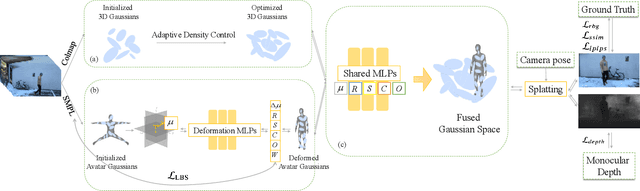


Reconstructing dynamic humans interacting with real-world environments from monocular videos is an important and challenging task. Despite considerable progress in 4D neural rendering, existing approaches either model dynamic scenes holistically or model scenes and backgrounds separately aim to introduce parametric human priors. However, these approaches either neglect distinct motion characteristics of various components in scene especially human, leading to incomplete reconstructions, or ignore the information exchange between the separately modeled components, resulting in spatial inconsistencies and visual artifacts at human-scene boundaries. To address this, we propose {\bf Separate-then-Map} (StM) strategy that introduces a dedicated information mapping mechanism to bridge separately defined and optimized models. Our method employs a shared transformation function for each Gaussian attribute to unify separately modeled components, enhancing computational efficiency by avoiding exhaustive pairwise interactions while ensuring spatial and visual coherence between humans and their surroundings. Extensive experiments on monocular video datasets demonstrate that StM significantly outperforms existing state-of-the-art methods in both visual quality and rendering accuracy, particularly at challenging human-scene interaction boundaries.