 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPDFusion: An Infrared and Visible Image Fusion Network Based on a Non-Euclidean Representation of Riemannian Manifolds
Paper and Code
Nov 16, 2024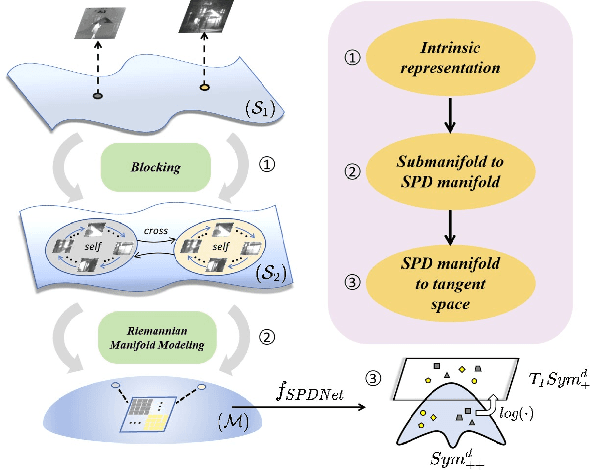

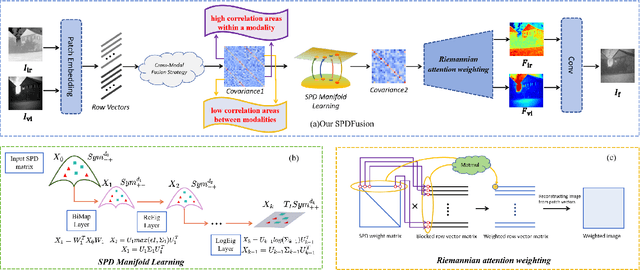

Euclidean representation learning methods have achieved commendable results in image fusion tasks, which can be attributed to their clear advantages in handling with linear space. However, data collected from a realistic scene usually have a non-Euclidean structure, where Euclidean metric might be limited in representing the true data relationships, degrading fusion performance. To address this issue, a novel SPD (symmetric positive definite) manifold learning framework is proposed for multi-modal image fusion, named SPDFusion, which extends the image fusion approach from the Euclidean space to the SPD manifolds. Specifically, we encode images according to the Riemannian geometry to exploit their intrinsic statistical correlations, thereby aligning with human visual perception. Actually, the SPD matrix underpins our network learning, with a cross-modal fusion strategy employed to harness modality-specific dependencies and augment complementary information. Subsequently, an attention module is designed to process the learned weight matrix, facilitating the weighting of spatial global correlation semantics via SPD matrix multiplication. Based on this, we design an end-to-end fusion network based on cross-modal manifold learning. Extensive experiments on public datasets demonstrate that our framework exhibits superior performance compared to the current state-of-the-art methods.