 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Driven Fusion for Infrared and Visible Images: Achieving Image Scene Adaptation on Hyperbolic Space
Jun 13, 2026Infrared and visible image fusion aims to integrate complementary modalities, while existing Euclidean methods impose rigid distance metrics that distort multi-modal interactions and parent-to-child semantic hierarchies. To overcome these limitations, we introduce a text-driven fusion framework empowered by hyperbolic manifold learning. During training, BLIP-extracted text prompts serve as topological anchors within the hyperbolic space, guiding vision-attribute alignment through hyperbolic embeddings that naturally accommodate varying semantic granularities. By exploiting the exponential volume growth dictated by the Poincaré ball's negative curvature, this approach seamlessly embeds hierarchical trees to encode coarse-to-fine semantics without metric saturation, while the vast peripheral space prevents texture distortion during cross-modal fusion. At inference, the fusion process autonomously adapts to input content using the learned text-attribute priors, completely eliminating the need for textual input. Experimental results show our method outperforms state-of-the-art approaches on benchmark datasets, with code available at https://github.com/Shaoyun2023/TEDFusion.
GrFormer: A Novel Transformer on Grassmann Manifold for Infrared and Visible Image Fusion
Jun 17, 2025


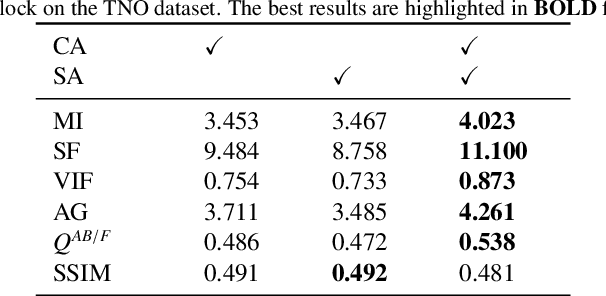
In the field of image fusion, promising progress has been made by modeling data from different modalities as linear subspaces. However, in practice, the source images are often located in a non-Euclidean space, where the Euclidean methods usually cannot encapsulate the intrinsic topological structure. Typically, the inner product performed in the Euclidean space calculates the algebraic similarity rather than the semantic similarity, which results in undesired attention output and a decrease in fusion performance. While the balance of low-level details and high-level semantics should be considered in infrared and visible image fusion task. To address this issue, in this paper, we propose a novel attention mechanism based on Grassmann manifold for infrared and visible image fusion (GrFormer). Specifically, our method constructs a low-rank subspace mapping through projection constraints on the Grassmann manifold, compressing attention features into subspaces of varying rank levels. This forces the features to decouple into high-frequency details (local low-rank) and low-frequency semantics (global low-rank), thereby achieving multi-scale semantic fusion. Additionally, to effectively integrate the significant information, we develop a cross-modal fusion strategy (CMS) based on a covariance mask to maximise the complementary properties between different modalities and to suppress the features with high correlation, which are deemed redundant. The experimental results demonstrate that our network outperforms SOTA methods both qualitatively and quantitatively on multiple image fusion benchmarks. The codes are available at https://github.com/Shaoyun2023.
SPDFusion: An Infrared and Visible Image Fusion Network Based on a Non-Euclidean Representation of Riemannian Manifolds
Nov 16, 2024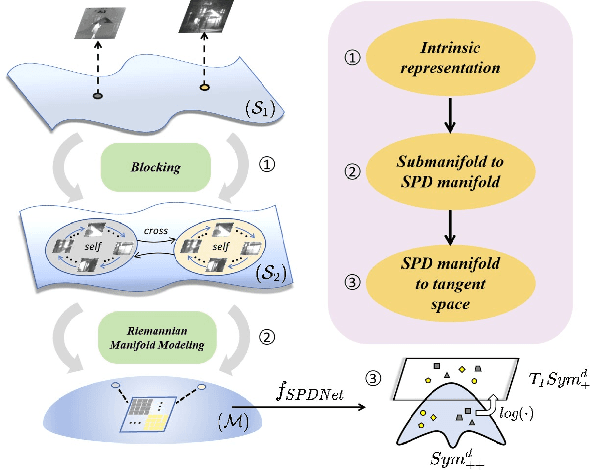

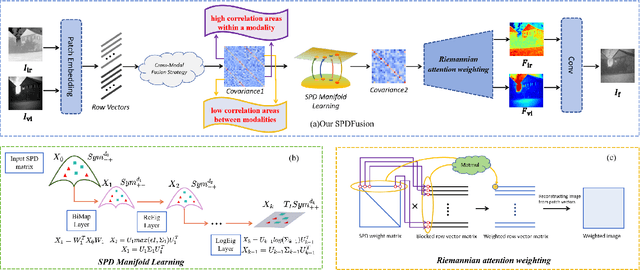

Euclidean representation learning methods have achieved commendable results in image fusion tasks, which can be attributed to their clear advantages in handling with linear space. However, data collected from a realistic scene usually have a non-Euclidean structure, where Euclidean metric might be limited in representing the true data relationships, degrading fusion performance. To address this issue, a novel SPD (symmetric positive definite) manifold learning framework is proposed for multi-modal image fusion, named SPDFusion, which extends the image fusion approach from the Euclidean space to the SPD manifolds. Specifically, we encode images according to the Riemannian geometry to exploit their intrinsic statistical correlations, thereby aligning with human visual perception. Actually, the SPD matrix underpins our network learning, with a cross-modal fusion strategy employed to harness modality-specific dependencies and augment complementary information. Subsequently, an attention module is designed to process the learned weight matrix, facilitating the weighting of spatial global correlation semantics via SPD matrix multiplication. Based on this, we design an end-to-end fusion network based on cross-modal manifold learning. Extensive experiments on public datasets demonstrate that our framework exhibits superior performance compared to the current state-of-the-art methods.