 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Driven Fusion for Infrared and Visible Images: Achieving Image Scene Adaptation on Hyperbolic Space
Jun 13, 2026Infrared and visible image fusion aims to integrate complementary modalities, while existing Euclidean methods impose rigid distance metrics that distort multi-modal interactions and parent-to-child semantic hierarchies. To overcome these limitations, we introduce a text-driven fusion framework empowered by hyperbolic manifold learning. During training, BLIP-extracted text prompts serve as topological anchors within the hyperbolic space, guiding vision-attribute alignment through hyperbolic embeddings that naturally accommodate varying semantic granularities. By exploiting the exponential volume growth dictated by the Poincaré ball's negative curvature, this approach seamlessly embeds hierarchical trees to encode coarse-to-fine semantics without metric saturation, while the vast peripheral space prevents texture distortion during cross-modal fusion. At inference, the fusion process autonomously adapts to input content using the learned text-attribute priors, completely eliminating the need for textual input. Experimental results show our method outperforms state-of-the-art approaches on benchmark datasets, with code available at https://github.com/Shaoyun2023/TEDFusion.
EvaNet: Towards More Efficient and Consistent Infrared and Visible Image Fusion Assessment
Apr 03, 2026Evaluation is essential in image fusion research, yet most existing metrics are directly borrowed from other vision tasks without proper adaptation. These traditional metrics, often based on complex image transformations, not only fail to capture the true quality of the fusion results but also are computationally demanding. To address these issues, we propose a unified evaluation framework specifically tailored for image fusion. At its core is a lightweight network designed efficiently to approximate widely used metrics, following a divide-and-conquer strategy. Unlike conventional approaches that directly assess similarity between fused and source images, we first decompose the fusion result into infrared and visible components. The evaluation model is then used to measure the degree of information preservation in these separated components, effectively disentangling the fusion evaluation process. During training, we incorporate a contrastive learning strategy and inform our evaluation model by perceptual scene assessment provided by a large language model. Last, we propose the first consistency evaluation framework, which measures the alignment between image fusion metrics and human visual perception, using both independent no-reference scores and downstream tasks performance as objective references. Extensive experiments show that our learning-based evaluation paradigm delivers both superior efficiency (up to 1,000 times faster) and greater consistency across a range of standard image fusion benchmarks. Our code will be publicly available at https://github.com/AWCXV/EvaNet.
Learning Progressive Adaptation for Multi-Modal Tracking
Mar 22, 2026Due to the limited availability of paired multi-modal data, multi-modal trackers are typically built by adopting pre-trained RGB models with parameter-efficient fine-tuning modules. However, these fine-tuning methods overlook advanced adaptations for applying RGB pre-trained models and fail to modulate a single specific modality, cross-modal interactions, and the prediction head. To address the issues, we propose to perform Progressive Adaptation for Multi-Modal Tracking (PATrack). This innovative approach incorporates modality-dependent, modality-entangled, and task-level adapters, effectively bridging the gap in adapting RGB pre-trained networks to multi-modal data through a progressive strategy. Specifically, modality-specific information is enhanced through the modality-dependent adapter, decomposing the high- and low-frequency components, which ensures a more robust feature representation within each modality. The inter-modal interactions are introduced in the modality-entangled adapter, which implements a cross-attention operation guided by inter-modal shared information, ensuring the reliability of features conveyed between modalities. Additionally, recognising that the strong inductive bias of the prediction head does not adapt to the fused information, a task-level adapter specific to the prediction head is introduced. In summary, our design integrates intra-modal, inter-modal, and task-level adapters into a unified framework. Extensive experiments on RGB+Thermal, RGB+Depth, and RGB+Event tracking tasks demonstrate that our method shows impressive performance against state-of-the-art methods. Code is available at https://github.com/ouha1998/Learning-Progressive-Adaptation-for-Multi-Modal-Tracking.
FusionRegister: Every Infrared and Visible Image Fusion Deserves Registration
Mar 08, 2026Spatial registration across different visual modalities is a critical but formidable step in multi-modality image fusion for real-world perception. Although several methods are proposed to address this issue, the existing registration-based fusion methods typically require extensive pre-registration operations, limiting their efficiency. To overcome these limitations, a general cross-modality registration method guided by visual priors is proposed for infrared and visible image fusion task, termed FusionRegister. Firstly, FusionRegister achieves robustness by learning cross-modality misregistration representations rather than forcing alignment of all differences, ensuring stable outputs even under challenging input conditions. Moreover, FusionRegister demonstrates strong generality by operating directly on fused results, where misregistration is explicitly represented and effectively handled, enabling seamless integration with diverse fusion methods while preserving their intrinsic properties. In addition, its efficiency is further enhanced by serving the backbone fusion method as a natural visual prior provider, which guides the registration process to focus only on mismatch regions, thereby avoiding redundant operations. Extensive experiments on three datasets demonstrate that FusionRegister not only inherits the fusion quality of state-of-the-art methods, but also delivers superior detail alignment and robustness, making it highly suitable for infrared and visible image fusion method. The code will be available at https://github.com/bociic/FusionRegister.
Towards Highly Transferable Vision-Language Attack via Semantic-Augmented Dynamic Contrastive Interaction
Mar 05, 2026With the rapid advancement and widespread application of vision-language pre-training (VLP) models, their vulnerability to adversarial attacks has become a critical concern. In general, the adversarial examples can typically be designed to exhibit transferable power, attacking not only different models but also across diverse tasks. However, existing attacks on language-vision models mainly rely on static cross-modal interactions and focus solely on disrupting positive image-text pairs, resulting in limited cross-modal disruption and poor transferability. To address this issue, we propose a Semantic-Augmented Dynamic Contrastive Attack (SADCA) that enhances adversarial transferability through progressive and semantically guided perturbation. SADCA progressively disrupts cross-modal alignment through dynamic interactions between adversarial images and texts. This is accomplished by SADCA establishing a contrastive learning mechanism involving adversarial, positive and negative samples, to reinforce the semantic inconsistency of the obtained perturbations. Moreover, we empirically find that input transformations commonly used in traditional transfer-based attacks also benefit VLPs, which motivates a semantic augmentation module that increases the diversity and generalization of adversarial examples. Extensive experiments on multiple datasets and models demonstrate that SADCA significantly improves adversarial transferability and consistently surpasses state-of-the-art methods. The code is released at https://github.com/LiYuanBoJNU/SADCA.
Multi-Paradigm Collaborative Adversarial Attack Against Multi-Modal Large Language Models
Mar 05, 2026The rapid progress of Multi-Modal Large Language Models (MLLMs) has significantly advanced downstream applications. However, this progress also exposes serious transferable adversarial vulnerabilities. In general, existing adversarial attacks against MLLMs typically rely on surrogate models trained within a single learning paradigm and perform independent optimisation in their respective feature spaces. This straightforward setting naturally restricts the richness of feature representations, delivering limits on the search space and thus impeding the diversity of adversarial perturbations. To address this, we propose a novel Multi-Paradigm Collaborative Attack (MPCAttack) framework to boost the transferability of adversarial examples against MLLMs. In principle, MPCAttack aggregates semantic representations, from both visual images and language texts, to facilitate joint adversarial optimisation on the aggregated features through a Multi-Paradigm Collaborative Optimisation (MPCO) strategy. By performing contrastive matching on multi-paradigm features, MPCO adaptively balances the importance of different paradigm representations and guides the global perturbation optimisation, effectively alleviating the representation bias. Extensive experimental results on multiple benchmarks demonstrate the superiority of MPCAttack, indicating that our solution consistently outperforms state-of-the-art methods in both targeted and untargeted attacks on open-source and closed-source MLLMs. The code is released at https://github.com/LiYuanBoJNU/MPCAttack.
Wasserstein-Aligned Hyperbolic Multi-View Clustering
Dec 10, 2025Multi-view clustering (MVC) aims to uncover the latent structure of multi-view data by learning view-common and view-specific information. Although recent studies have explored hyperbolic representations for better tackling the representation gap between different views, they focus primarily on instance-level alignment and neglect global semantic consistency, rendering them vulnerable to view-specific information (\textit{e.g.}, noise and cross-view discrepancies). To this end, this paper proposes a novel Wasserstein-Aligned Hyperbolic (WAH) framework for multi-view clustering. Specifically, our method exploits a view-specific hyperbolic encoder for each view to embed features into the Lorentz manifold for hierarchical semantic modeling. Whereafter, a global semantic loss based on the hyperbolic sliced-Wasserstein distance is introduced to align manifold distributions across views. This is followed by soft cluster assignments to encourage cross-view semantic consistency. Extensive experiments on multiple benchmarking datasets show that our method can achieve SOTA clustering performance.
MARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
Riemannian Batch Normalization: A Gyro Approach
Sep 08, 2025Normalization layers are crucial for deep learning, but their Euclidean formulations are inadequate for data on manifolds. On the other hand, many Riemannian manifolds in machine learning admit gyro-structures, enabling principled extensions of Euclidean neural networks to non-Euclidean domains. Inspired by this, we introduce GyroBN, a principled Riemannian batch normalization framework for gyrogroups. We establish two necessary conditions, namely \emph{pseudo-reduction} and \emph{gyroisometric gyrations}, that guarantee GyroBN with theoretical control over sample statistics, and show that these conditions hold for all known gyrogroups in machine learning. Our framework also incorporates several existing Riemannian normalization methods as special cases. We further instantiate GyroBN on seven representative geometries, including the Grassmannian, five constant curvature spaces, and the correlation manifold, and derive novel gyro and Riemannian structures to enable these instantiations. Experiments across these geometries demonstrate the effectiveness of GyroBN. The code is available at https://github.com/GitZH-Chen/GyroBN.git.
Uncertainty-aware Cross-training for Semi-supervised Medical Image Segmentation
Aug 12, 2025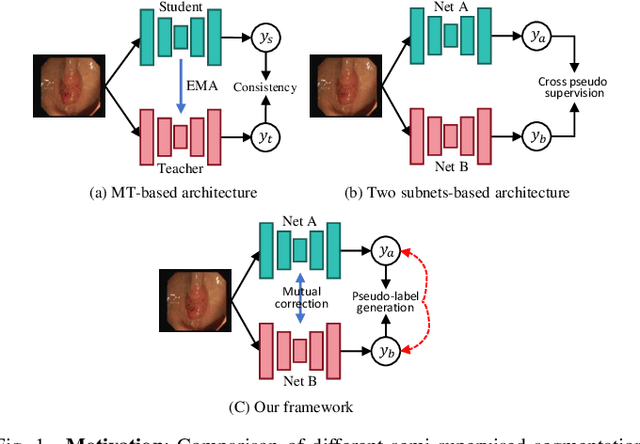
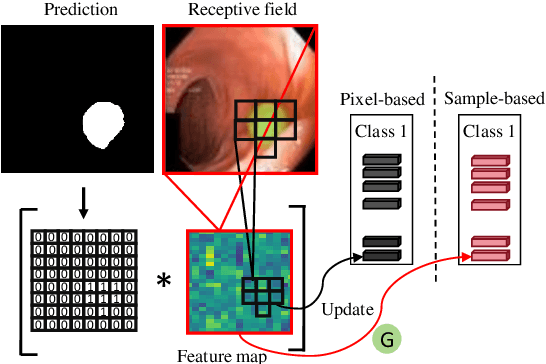
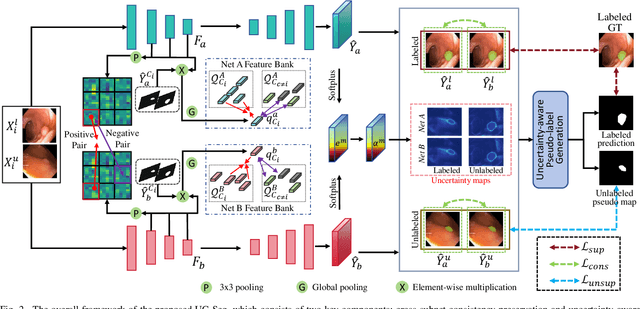
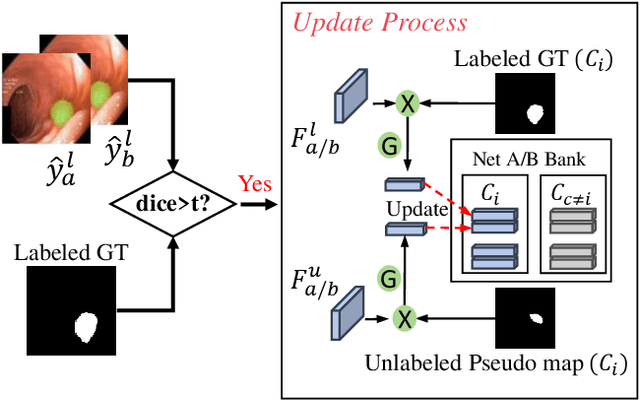
Semi-supervised learning has gained considerable popularity in medical image segmentation tasks due to its capability to reduce reliance on expert-examined annotations. Several mean-teacher (MT) based semi-supervised methods utilize consistency regularization to effectively leverage valuable information from unlabeled data. However, these methods often heavily rely on the student model and overlook the potential impact of cognitive biases within the model. Furthermore, some methods employ co-training using pseudo-labels derived from different inputs, yet generating high-confidence pseudo-labels from perturbed inputs during training remains a significant challenge. In this paper, we propose an Uncertainty-aware Cross-training framework for semi-supervised medical image Segmentation (UC-Seg). Our UC-Seg framework incorporates two distinct subnets to effectively explore and leverage the correlation between them, thereby mitigating cognitive biases within the model. Specifically, we present a Cross-subnet Consistency Preservation (CCP) strategy to enhance feature representation capability and ensure feature consistency across the two subnets. This strategy enables each subnet to correct its own biases and learn shared semantics from both labeled and unlabeled data. Additionally, we propose an Uncertainty-aware Pseudo-label Generation (UPG) component that leverages segmentation results and corresponding uncertainty maps from both subnets to generate high-confidence pseudo-labels. We extensively evaluate the proposed UC-Seg on various medical image segmentation tasks involving different modality images, such as MRI, CT, ultrasound, colonoscopy, and so on. The results demonstrate that our method achieves superior segmentation accuracy and generalization performance compared to other state-of-the-art semi-supervised methods. Our code will be released at https://github.com/taozh2017/UCSeg.