 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpontaneous symmetry breaking and Goldstone modes for deep information propagation
May 14, 2026In physical systems, whenever a continuous symmetry is spontaneously broken, the system possesses excitations called Goldstone modes, which allow coherent information propagation over long distances and times. In this work, we study deep neural networks whose internal layers are equivariant under a continuous symmetry and may therefore support analogous Goldstone-like degrees of freedom. We demonstrate, both analytically and empirically, that these degrees of freedom enable coherent signal propagation across depth and recurrent iterations, providing a mechanism for stable information flow without relying on architectural stabilizers such as residual connections or normalization. In feedforward networks, this results in improved trainability and representational diversity across layers. In recurrent settings, we demonstrate the same mechanism is valuable for long-term memory by propagating information over recurrent iterations, thereby improving performance of RNNs and GRUs on long-sequence modeling tasks.
Krause Synchronization Transformers
Feb 12, 2026Self-attention in Transformers relies on globally normalized softmax weights, causing all tokens to compete for influence at every layer. When composed across depth, this interaction pattern induces strong synchronization dynamics that favor convergence toward a dominant mode, a behavior associated with representation collapse and attention sink phenomena. We introduce Krause Attention, a principled attention mechanism inspired by bounded-confidence consensus dynamics. Krause Attention replaces similarity-based global aggregation with distance-based, localized, and selectively sparse interactions, promoting structured local synchronization instead of global mixing. We relate this behavior to recent theory modeling Transformer dynamics as interacting particle systems, and show how bounded-confidence interactions naturally moderate attention concentration and alleviate attention sinks. Restricting interactions to local neighborhoods also reduces runtime complexity from quadratic to linear in sequence length. Experiments across vision (ViT on CIFAR/ImageNet), autoregressive generation (MNIST/CIFAR-10), and large language models (Llama/Qwen) demonstrate consistent gains with substantially reduced computation, highlighting bounded-confidence dynamics as a scalable and effective inductive bias for attention.
A Unified Masked Jigsaw Puzzle Framework for Vision and Language Models
Jan 17, 2026In federated learning, Transformer, as a popular architecture, faces critical challenges in defending against gradient attacks and improving model performance in both Computer Vision (CV) and Natural Language Processing (NLP) tasks. It has been revealed that the gradient of Position Embeddings (PEs) in Transformer contains sufficient information, which can be used to reconstruct the input data. To mitigate this issue, we introduce a Masked Jigsaw Puzzle (MJP) framework. MJP starts with random token shuffling to break the token order, and then a learnable \textit{unknown (unk)} position embedding is used to mask out the PEs of the shuffled tokens. In this manner, the local spatial information which is encoded in the position embeddings is disrupted, and the models are forced to learn feature representations that are less reliant on the local spatial information. Notably, with the careful use of MJP, we can not only improve models' robustness against gradient attacks, but also boost their performance in both vision and text application scenarios, such as classification for images (\textit{e.g.,} ImageNet-1K) and sentiment analysis for text (\textit{e.g.,} Yelp and Amazon). Experimental results suggest that MJP is a unified framework for different Transformer-based models in both vision and language tasks. Code is publicly available via https://github.com/ywxsuperstar/transformerattack
Constitutional Classifiers++: Efficient Production-Grade Defenses against Universal Jailbreaks
Jan 08, 2026We introduce enhanced Constitutional Classifiers that deliver production-grade jailbreak robustness with dramatically reduced computational costs and refusal rates compared to previous-generation defenses. Our system combines several key insights. First, we develop exchange classifiers that evaluate model responses in their full conversational context, which addresses vulnerabilities in last-generation systems that examine outputs in isolation. Second, we implement a two-stage classifier cascade where lightweight classifiers screen all traffic and escalate only suspicious exchanges to more expensive classifiers. Third, we train efficient linear probe classifiers and ensemble them with external classifiers to simultaneously improve robustness and reduce computational costs. Together, these techniques yield a production-grade system achieving a 40x computational cost reduction compared to our baseline exchange classifier, while maintaining a 0.05% refusal rate on production traffic. Through extensive red-teaming comprising over 1,700 hours, we demonstrate strong protection against universal jailbreaks -- no attack on this system successfully elicited responses to all eight target queries comparable in detail to an undefended model. Our work establishes Constitutional Classifiers as practical and efficient safeguards for large language models.
On Exact Editing of Flow-Based Diffusion Models
Dec 30, 2025Recent methods in flow-based diffusion editing have enabled direct transformations between source and target image distribution without explicit inversion. However, the latent trajectories in these methods often exhibit accumulated velocity errors, leading to semantic inconsistency and loss of structural fidelity. We propose Conditioned Velocity Correction (CVC), a principled framework that reformulates flow-based editing as a distribution transformation problem driven by a known source prior. CVC rethinks the role of velocity in inter-distribution transformation by introducing a dual-perspective velocity conversion mechanism. This mechanism explicitly decomposes the latent evolution into two components: a structure-preserving branch that remains consistent with the source trajectory, and a semantically-guided branch that drives a controlled deviation toward the target distribution. The conditional velocity field exhibits an absolute velocity error relative to the true underlying distribution trajectory, which inherently introduces potential instability and trajectory drift in the latent space. To address this quantifiable deviation and maintain fidelity to the true flow, we apply a posterior-consistent update to the resulting conditional velocity field. This update is derived from Empirical Bayes Inference and Tweedie correction, which ensures a mathematically grounded error compensation over time. Our method yields stable and interpretable latent dynamics, achieving faithful reconstruction alongside smooth local semantic conversion. Comprehensive experiments demonstrate that CVC consistently achieves superior fidelity, better semantic alignment, and more reliable editing behavior across diverse tasks.
Kuramoto Orientation Diffusion Models
Sep 18, 2025Orientation-rich images, such as fingerprints and textures, often exhibit coherent angular directional patterns that are challenging to model using standard generative approaches based on isotropic Euclidean diffusion. Motivated by the role of phase synchronization in biological systems, we propose a score-based generative model built on periodic domains by leveraging stochastic Kuramoto dynamics in the diffusion process. In neural and physical systems, Kuramoto models capture synchronization phenomena across coupled oscillators -- a behavior that we re-purpose here as an inductive bias for structured image generation. In our framework, the forward process performs \textit{synchronization} among phase variables through globally or locally coupled oscillator interactions and attraction to a global reference phase, gradually collapsing the data into a low-entropy von Mises distribution. The reverse process then performs \textit{desynchronization}, generating diverse patterns by reversing the dynamics with a learned score function. This approach enables structured destruction during forward diffusion and a hierarchical generation process that progressively refines global coherence into fine-scale details. We implement wrapped Gaussian transition kernels and periodicity-aware networks to account for the circular geometry. Our method achieves competitive results on general image benchmarks and significantly improves generation quality on orientation-dense datasets like fingerprints and textures. Ultimately, this work demonstrates the promise of biologically inspired synchronization dynamics as structured priors in generative modeling.
Data-driven solar forecasting enables near-optimal economic decisions
Sep 08, 2025Solar energy adoption is critical to achieving net-zero emissions. However, it remains difficult for many industrial and commercial actors to decide on whether they should adopt distributed solar-battery systems, which is largely due to the unavailability of fast, low-cost, and high-resolution irradiance forecasts. Here, we present SunCastNet, a lightweight data-driven forecasting system that provides 0.05$^\circ$, 10-minute resolution predictions of surface solar radiation downwards (SSRD) up to 7 days ahead. SunCastNet, coupled with reinforcement learning (RL) for battery scheduling, reduces operational regret by 76--93\% compared to robust decision making (RDM). In 25-year investment backtests, it enables up to five of ten high-emitting industrial sectors per region to cross the commercial viability threshold of 12\% Internal Rate of Return (IRR). These results show that high-resolution, long-horizon solar forecasts can directly translate into measurable economic gains, supporting near-optimal energy operations and accelerating renewable deployment.
OneRec-V2 Technical Report
Aug 28, 2025



Recent breakthroughs in generative AI have transformed recommender systems through end-to-end generation. OneRec reformulates recommendation as an autoregressive generation task, achieving high Model FLOPs Utilization. While OneRec-V1 has shown significant empirical success in real-world deployment, two critical challenges hinder its scalability and performance: (1) inefficient computational allocation where 97.66% of resources are consumed by sequence encoding rather than generation, and (2) limitations in reinforcement learning relying solely on reward models. To address these challenges, we propose OneRec-V2, featuring: (1) Lazy Decoder-Only Architecture: Eliminates encoder bottlenecks, reducing total computation by 94% and training resources by 90%, enabling successful scaling to 8B parameters. (2) Preference Alignment with Real-World User Interactions: Incorporates Duration-Aware Reward Shaping and Adaptive Ratio Clipping to better align with user preferences using real-world feedback. Extensive A/B tests on Kuaishou demonstrate OneRec-V2's effectiveness, improving App Stay Time by 0.467%/0.741% while balancing multi-objective recommendations. This work advances generative recommendation scalability and alignment with real-world feedback, representing a step forward in the development of end-to-end recommender systems.
Langevin Flows for Modeling Neural Latent Dynamics
Jul 15, 2025



Neural populations exhibit latent dynamical structures that drive time-evolving spiking activities, motivating the search for models that capture both intrinsic network dynamics and external unobserved influences. In this work, we introduce LangevinFlow, a sequential Variational Auto-Encoder where the time evolution of latent variables is governed by the underdamped Langevin equation. Our approach incorporates physical priors -- such as inertia, damping, a learned potential function, and stochastic forces -- to represent both autonomous and non-autonomous processes in neural systems. Crucially, the potential function is parameterized as a network of locally coupled oscillators, biasing the model toward oscillatory and flow-like behaviors observed in biological neural populations. Our model features a recurrent encoder, a one-layer Transformer decoder, and Langevin dynamics in the latent space. Empirically, our method outperforms state-of-the-art baselines on synthetic neural populations generated by a Lorenz attractor, closely matching ground-truth firing rates. On the Neural Latents Benchmark (NLB), the model achieves superior held-out neuron likelihoods (bits per spike) and forward prediction accuracy across four challenging datasets. It also matches or surpasses alternative methods in decoding behavioral metrics such as hand velocity. Overall, this work introduces a flexible, physics-inspired, high-performing framework for modeling complex neural population dynamics and their unobserved influences.
OneRec Technical Report
Jun 16, 2025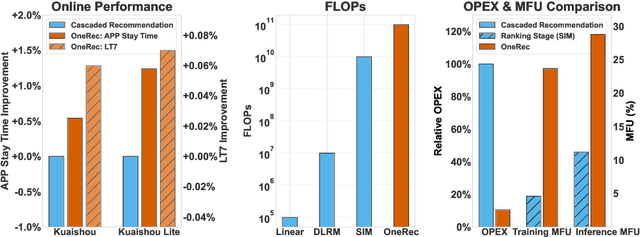

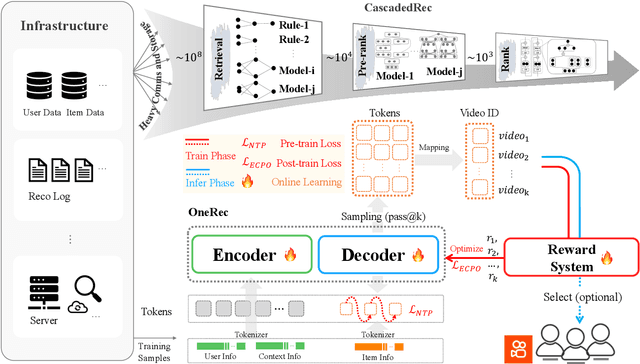

Recommender systems have been widely used in various large-scale user-oriented platforms for many years. However, compared to the rapid developments in the AI community, recommendation systems have not achieved a breakthrough in recent years. For instance, they still rely on a multi-stage cascaded architecture rather than an end-to-end approach, leading to computational fragmentation and optimization inconsistencies, and hindering the effective application of key breakthrough technologies from the AI community in recommendation scenarios. To address these issues, we propose OneRec, which reshapes the recommendation system through an end-to-end generative approach and achieves promising results. Firstly, we have enhanced the computational FLOPs of the current recommendation model by 10 $\times$ and have identified the scaling laws for recommendations within certain boundaries. Secondly, reinforcement learning techniques, previously difficult to apply for optimizing recommendations, show significant potential in this framework. Lastly, through infrastructure optimizations, we have achieved 23.7% and 28.8% Model FLOPs Utilization (MFU) on flagship GPUs during training and inference, respectively, aligning closely with the LLM community. This architecture significantly reduces communication and storage overhead, resulting in operating expense that is only 10.6% of traditional recommendation pipelines. Deployed in Kuaishou/Kuaishou Lite APP, it handles 25% of total queries per second, enhancing overall App Stay Time by 0.54% and 1.24%, respectively. Additionally, we have observed significant increases in metrics such as 7-day Lifetime, which is a crucial indicator of recommendation experience. We also provide practical lessons and insights derived from developing, optimizing, and maintaining a production-scale recommendation system with significant real-world impact.