 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Multi-Site Clinical Data: A Federated Approach to Privacy-First Child Autism Behavior Analysis
Apr 03, 2026Automated recognition of autistic behaviors in children is essential for early intervention and objective clinical assessment. However, the development of robust models is severely hindered by strict privacy regulations (e.g., HIPAA) and the sensitive nature of pediatric data, which prevents the centralized aggregation of clinical datasets. Furthermore, individual clinical sites often suffer from data scarcity, making it difficult to learn generalized behavior patterns or tailor models to site-specific patient distributions. To address these challenges, we observe that Federated Learning (FL) can decouple model training from raw data access, enabling multi-site collaboration while maintaining strict data residency. In this paper, we present the first study exploring Federated Learning for pose-based child autism behavior recognition. Our framework employs a two-layer privacy protection mechanism: utilizing human skeletal abstraction to remove identifiable visual information from the raw RGB videos and FL to ensure sensitive pose data remains within the clinic. This approach leverages distributed clinical data to learn generalized representations while providing the flexibility for site-specific personalization. Experimental results on the MMASD benchmark demonstrate that our framework achieves high recognition accuracy, outperforming traditional federated baselines and providing a robust, privacy-first solution for multi-site clinical analysis.
Geo$^\textbf{2}$: Geometry-Guided Cross-view Geo-Localization and Image Synthesis
Mar 26, 2026Cross-view geo-spatial learning consists of two important tasks: Cross-View Geo-Localization (CVGL) and Cross-View Image Synthesis (CVIS), both of which rely on establishing geometric correspondences between ground and aerial views. Recent Geometric Foundation Models (GFMs) have demonstrated strong capabilities in extracting generalizable 3D geometric features from images, but their potential in cross-view geo-spatial tasks remains underexplored. In this work, we present Geo^2, a unified framework that leverages Geometric priors from GFMs (e.g., VGGT) to jointly perform geo-spatial tasks, CVGL and bidirectional CVIS. Despite the 3D reconstruction ability of GFMs, directly applying them to CVGL and CVIS remains challenging due to the large viewpoint gap between ground and aerial imagery. We propose GeoMap, which embeds ground and aerial features into a shared 3D-aware latent space, effectively reducing cross-view discrepancies for localization. This shared latent space naturally bridges cross-view image synthesis in both directions. To exploit this, we propose GeoFlow, a flow-matching model conditioned on geometry-aware latent embeddings. We further introduce a consistency loss to enforce latent alignment between the two synthesis directions, ensuring bidirectional coherence. Extensive experiments on standard benchmarks, including CVUSA, CVACT, and VIGOR, demonstrate that Geo^2 achieves state-of-the-art performance in both localization and synthesis, highlighting the effectiveness of 3D geometric priors for cross-view geo-spatial learning.
AIM: Software and Hardware Co-design for Architecture-level IR-drop Mitigation in High-performance PIM
Nov 06, 2025



SRAM Processing-in-Memory (PIM) has emerged as the most promising implementation for high-performance PIM, delivering superior computing density, energy efficiency, and computational precision. However, the pursuit of higher performance necessitates more complex circuit designs and increased operating frequencies, which exacerbate IR-drop issues. Severe IR-drop can significantly degrade chip performance and even threaten reliability. Conventional circuit-level IR-drop mitigation methods, such as back-end optimizations, are resource-intensive and often compromise power, performance, and area (PPA). To address these challenges, we propose AIM, comprehensive software and hardware co-design for architecture-level IR-drop mitigation in high-performance PIM. Initially, leveraging the bit-serial and in-situ dataflow processing properties of PIM, we introduce Rtog and HR, which establish a direct correlation between PIM workloads and IR-drop. Building on this foundation, we propose LHR and WDS, enabling extensive exploration of architecture-level IR-drop mitigation while maintaining computational accuracy through software optimization. Subsequently, we develop IR-Booster, a dynamic adjustment mechanism that integrates software-level HR information with hardware-based IR-drop monitoring to adapt the V-f pairs of the PIM macro, achieving enhanced energy efficiency and performance. Finally, we propose the HR-aware task mapping method, bridging software and hardware designs to achieve optimal improvement. Post-layout simulation results on a 7nm 256-TOPS PIM chip demonstrate that AIM achieves up to 69.2% IR-drop mitigation, resulting in 2.29x energy efficiency improvement and 1.152x speedup.
Diagnosing Visual Reasoning: Challenges, Insights, and a Path Forward
Oct 23, 2025Multimodal large language models (MLLMs) that integrate visual and textual reasoning leverage chain-of-thought (CoT) prompting to tackle complex visual tasks, yet continue to exhibit visual hallucinations and an over-reliance on textual priors. We present a systematic diagnosis of state-of-the-art vision-language models using a three-stage evaluation framework, uncovering key failure modes. To address these, we propose an agent-based architecture that combines LLM reasoning with lightweight visual modules, enabling fine-grained analysis and iterative refinement of reasoning chains. Our results highlight future visual reasoning models should focus on integrating a broader set of specialized tools for analyzing visual content. Our system achieves significant gains (+10.3 on MMMU, +6.0 on MathVista over a 7B baseline), matching or surpassing much larger models. We will release our framework and evaluation suite to facilitate future research.
From Frames to Clips: Efficient Key Clip Selection for Long-Form Video Understanding
Oct 02, 2025Video Large Language Models (VLMs) have achieved remarkable results on a variety of vision language tasks, yet their practical use is limited by the "needle in a haystack" problem: the massive number of visual tokens produced from raw video frames exhausts the model's context window. Existing solutions alleviate this issue by selecting a sparse set of frames, thereby reducing token count, but such frame-wise selection discards essential temporal dynamics, leading to suboptimal reasoning about motion and event continuity. In this work we systematically explore the impact of temporal information and demonstrate that extending selection from isolated key frames to key clips, which are short, temporally coherent segments, improves video understanding. To maintain a fixed computational budget while accommodating the larger token footprint of clips, we propose an adaptive resolution strategy that dynamically balances spatial resolution and clip length, ensuring a constant token count per video. Experiments on three long-form video benchmarks demonstrate that our training-free approach, F2C, outperforms uniform sampling up to 8.1%, 5.6%, and 10.3% on Video-MME, LongVideoBench and MLVU benchmarks, respectively. These results highlight the importance of preserving temporal coherence in frame selection and provide a practical pathway for scaling Video LLMs to real world video understanding applications. Project webpage is available at https://guangyusun.com/f2c .
AC-Refiner: Efficient Arithmetic Circuit Optimization Using Conditional Diffusion Models
Jul 03, 2025Arithmetic circuits, such as adders and multipliers, are fundamental components of digital systems, directly impacting the performance, power efficiency, and area footprint. However, optimizing these circuits remains challenging due to the vast design space and complex physical constraints. While recent deep learning-based approaches have shown promise, they struggle to consistently explore high-potential design variants, limiting their optimization efficiency. To address this challenge, we propose AC-Refiner, a novel arithmetic circuit optimization framework leveraging conditional diffusion models. Our key insight is to reframe arithmetic circuit synthesis as a conditional image generation task. By carefully conditioning the denoising diffusion process on target quality-of-results (QoRs), AC-Refiner consistently produces high-quality circuit designs. Furthermore, the explored designs are used to fine-tune the diffusion model, which focuses the exploration near the Pareto frontier. Experimental results demonstrate that AC-Refiner generates designs with superior Pareto optimality, outperforming state-of-the-art baselines. The performance gain is further validated by integrating AC-Refiner into practical applications.
Why Reasoning Matters? A Survey of Advancements in Multimodal Reasoning (v1)
Apr 04, 2025
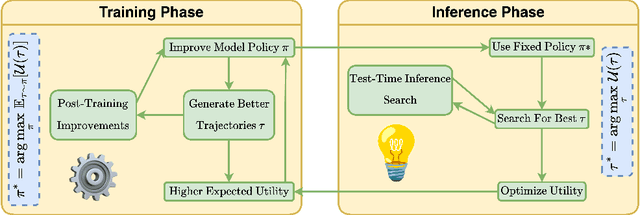
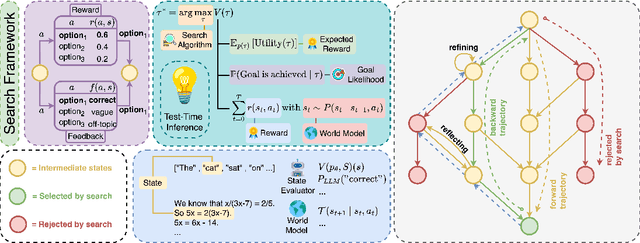
Reasoning is central to human intelligence, enabling structured problem-solving across diverse tasks. Recent advances in large language models (LLMs) have greatly enhanced their reasoning abilities in arithmetic, commonsense, and symbolic domains. However, effectively extending these capabilities into multimodal contexts-where models must integrate both visual and textual inputs-continues to be a significant challenge. Multimodal reasoning introduces complexities, such as handling conflicting information across modalities, which require models to adopt advanced interpretative strategies. Addressing these challenges involves not only sophisticated algorithms but also robust methodologies for evaluating reasoning accuracy and coherence. This paper offers a concise yet insightful overview of reasoning techniques in both textual and multimodal LLMs. Through a thorough and up-to-date comparison, we clearly formulate core reasoning challenges and opportunities, highlighting practical methods for post-training optimization and test-time inference. Our work provides valuable insights and guidance, bridging theoretical frameworks and practical implementations, and sets clear directions for future research.
VERIFY: A Benchmark of Visual Explanation and Reasoning for Investigating Multimodal Reasoning Fidelity
Mar 14, 2025Visual reasoning is central to human cognition, enabling individuals to interpret and abstractly understand their environment. Although recent Multimodal Large Language Models (MLLMs) have demonstrated impressive performance across language and vision-language tasks, existing benchmarks primarily measure recognition-based skills and inadequately assess true visual reasoning capabilities. To bridge this critical gap, we introduce VERIFY, a benchmark explicitly designed to isolate and rigorously evaluate the visual reasoning capabilities of state-of-the-art MLLMs. VERIFY compels models to reason primarily from visual information, providing minimal textual context to reduce reliance on domain-specific knowledge and linguistic biases. Each problem is accompanied by a human-annotated reasoning path, making it the first to provide in-depth evaluation of model decision-making processes. Additionally, we propose novel metrics that assess visual reasoning fidelity beyond mere accuracy, highlighting critical imbalances in current model reasoning patterns. Our comprehensive benchmarking of leading MLLMs uncovers significant limitations, underscoring the need for a balanced and holistic approach to both perception and reasoning. For more teaser and testing, visit our project page (https://verify-eqh.pages.dev/).
OriGen:Enhancing RTL Code Generation with Code-to-Code Augmentation and Self-Reflection
Jul 23, 2024Recent studies have illuminated that Large Language Models (LLMs) exhibit substantial potential in the realm of RTL (Register Transfer Level) code generation, with notable advancements evidenced by commercial models such as GPT-4 and Claude3-Opus. Despite their proficiency, these commercial LLMs often raise concerns regarding privacy and security. Conversely, open-source LLMs, which offer solutions to these concerns, have inferior performance in RTL code generation tasks to commercial models due to the lack of highquality open-source RTL datasets. To address this issue, we introduce OriGen, a fully open-source framework featuring self-reflection capabilities and a dataset augmentation methodology for generating high-quality, large-scale RTL code. We propose a novel code-to-code augmentation methodology that leverages knowledge distillation to enhance the quality of the open-source RTL code datasets. Additionally, OriGen is capable of correcting syntactic errors by leveraging a self-reflection process based on feedback from the compiler. The self-reflection ability of the model is facilitated by a carefully constructed dataset, which comprises a comprehensive collection of samples. Experimental results demonstrate that OriGen remarkably outperforms other open-source alternatives in RTL code generation, surpassing the previous best-performing LLM by 9.8% on the VerilogEval-Human benchmark. Furthermore, OriGen exhibits superior capabilities in self-reflection and error rectification, surpassing GPT-4 by 18.1% on the benchmark designed to evaluate the capability of self-reflection.
Navigating Heterogeneity and Privacy in One-Shot Federated Learning with Diffusion Models
May 02, 2024



Federated learning (FL) enables multiple clients to train models collectively while preserving data privacy. However, FL faces challenges in terms of communication cost and data heterogeneity. One-shot federated learning has emerged as a solution by reducing communication rounds, improving efficiency, and providing better security against eavesdropping attacks. Nevertheless, data heterogeneity remains a significant challenge, impacting performance. This work explores the effectiveness of diffusion models in one-shot FL, demonstrating their applicability in addressing data heterogeneity and improving FL performance. Additionally, we investigate the utility of our diffusion model approach, FedDiff, compared to other one-shot FL methods under differential privacy (DP). Furthermore, to improve generated sample quality under DP settings, we propose a pragmatic Fourier Magnitude Filtering (FMF) method, enhancing the effectiveness of generated data for global model training.