 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAC-Refiner: Efficient Arithmetic Circuit Optimization Using Conditional Diffusion Models
Jul 03, 2025Arithmetic circuits, such as adders and multipliers, are fundamental components of digital systems, directly impacting the performance, power efficiency, and area footprint. However, optimizing these circuits remains challenging due to the vast design space and complex physical constraints. While recent deep learning-based approaches have shown promise, they struggle to consistently explore high-potential design variants, limiting their optimization efficiency. To address this challenge, we propose AC-Refiner, a novel arithmetic circuit optimization framework leveraging conditional diffusion models. Our key insight is to reframe arithmetic circuit synthesis as a conditional image generation task. By carefully conditioning the denoising diffusion process on target quality-of-results (QoRs), AC-Refiner consistently produces high-quality circuit designs. Furthermore, the explored designs are used to fine-tune the diffusion model, which focuses the exploration near the Pareto frontier. Experimental results demonstrate that AC-Refiner generates designs with superior Pareto optimality, outperforming state-of-the-art baselines. The performance gain is further validated by integrating AC-Refiner into practical applications.
LLM Inference Unveiled: Survey and Roofline Model Insights
Mar 11, 2024The field of efficient Large Language Model (LLM) inference is rapidly evolving, presenting a unique blend of opportunities and challenges. Although the field has expanded and is vibrant, there hasn't been a concise framework that analyzes the various methods of LLM Inference to provide a clear understanding of this domain. Our survey stands out from traditional literature reviews by not only summarizing the current state of research but also by introducing a framework based on roofline model for systematic analysis of LLM inference techniques. This framework identifies the bottlenecks when deploying LLMs on hardware devices and provides a clear understanding of practical problems, such as why LLMs are memory-bound, how much memory and computation they need, and how to choose the right hardware. We systematically collate the latest advancements in efficient LLM inference, covering crucial areas such as model compression (e.g., Knowledge Distillation and Quantization), algorithm improvements (e.g., Early Exit and Mixture-of-Expert), and both hardware and system-level enhancements. Our survey stands out by analyzing these methods with roofline model, helping us understand their impact on memory access and computation. This distinctive approach not only showcases the current research landscape but also delivers valuable insights for practical implementation, positioning our work as an indispensable resource for researchers new to the field as well as for those seeking to deepen their understanding of efficient LLM deployment. The analyze tool, LLM-Viewer, is open-sourced.
Latency-aware Spatial-wise Dynamic Networks
Oct 12, 2022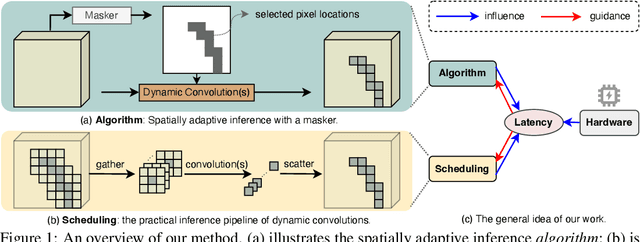

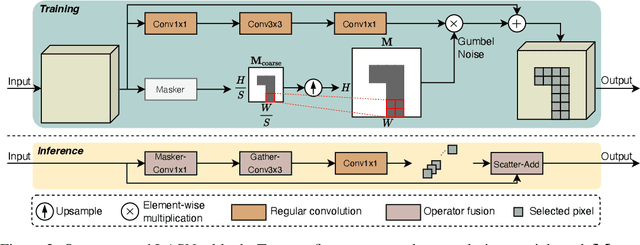

Spatial-wise dynamic convolution has become a promising approach to improving the inference efficiency of deep networks. By allocating more computation to the most informative pixels, such an adaptive inference paradigm reduces the spatial redundancy in image features and saves a considerable amount of unnecessary computation. However, the theoretical efficiency achieved by previous methods can hardly translate into a realistic speedup, especially on the multi-core processors (e.g. GPUs). The key challenge is that the existing literature has only focused on designing algorithms with minimal computation, ignoring the fact that the practical latency can also be influenced by scheduling strategies and hardware properties. To bridge the gap between theoretical computation and practical efficiency, we propose a latency-aware spatial-wise dynamic network (LASNet), which performs coarse-grained spatially adaptive inference under the guidance of a novel latency prediction model. The latency prediction model can efficiently estimate the inference latency of dynamic networks by simultaneously considering algorithms, scheduling strategies, and hardware properties. We use the latency predictor to guide both the algorithm design and the scheduling optimization on various hardware platforms. Experiments on image classification, object detection and instance segmentation demonstrate that the proposed framework significantly improves the practical inference efficiency of deep networks. For example, the average latency of a ResNet-101 on the ImageNet validation set could be reduced by 36% and 46% on a server GPU (Nvidia Tesla-V100) and an edge device (Nvidia Jetson TX2 GPU) respectively without sacrificing the accuracy. Code is available at https://github.com/LeapLabTHU/LASNet.
PTQ4ViT: Post-Training Quantization Framework for Vision Transformers
Nov 24, 2021

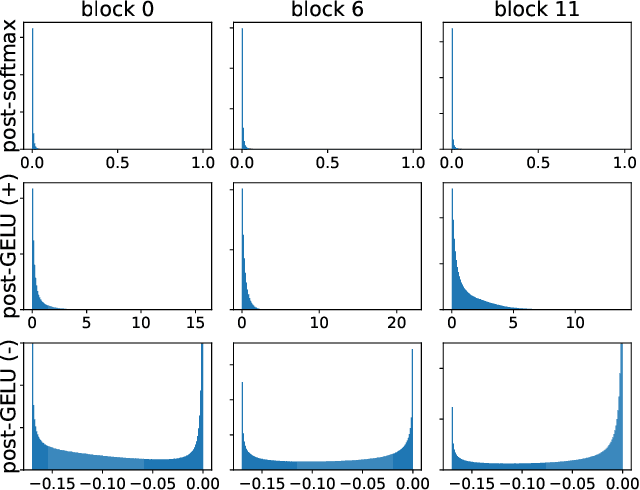
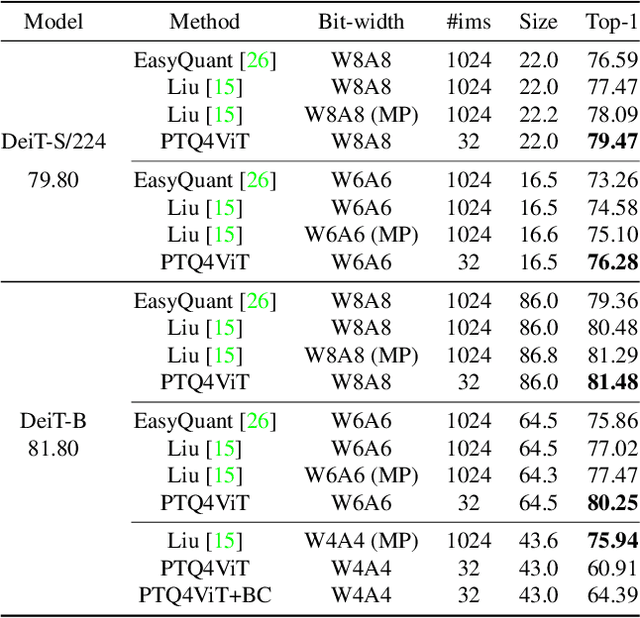
Quantization is one of the most effective methods to compress neural networks, which has achieved great success on convolutional neural networks (CNNs). Recently, vision transformers have demonstrated great potential in computer vision. However, previous post-training quantization methods performed not well on vision transformer, resulting in more than 1% accuracy drop even in 8-bit quantization. Therefore, we analyze the problems of quantization on vision transformers. We observe the distributions of activation values after softmax and GELU functions are quite different from the Gaussian distribution. We also observe that common quantization metrics, such as MSE and cosine distance, are inaccurate to determine the optimal scaling factor. In this paper, we propose the twin uniform quantization method to reduce the quantization error on these activation values. And we propose to use a Hessian guided metric to evaluate different scaling factors, which improves the accuracy of calibration with a small cost. To enable the fast quantization of vision transformers, we develop an efficient framework, PTQ4ViT. Experiments show the quantized vision transformers achieve near-lossless prediction accuracy (less than 0.5% drop at 8-bit quantization) on the ImageNet classification task.
PTQ-SL: Exploring the Sub-layerwise Post-training Quantization
Oct 18, 2021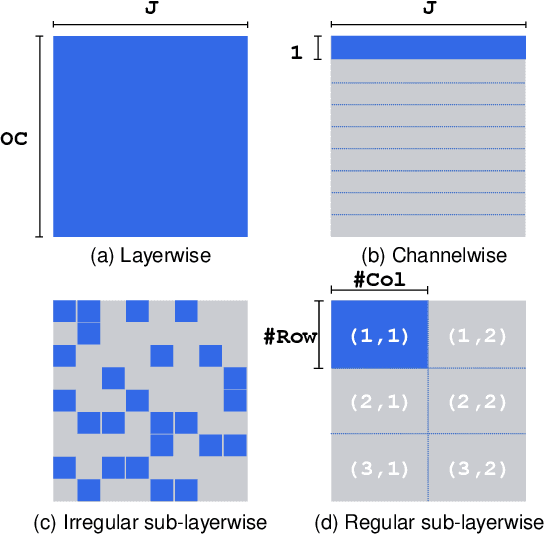
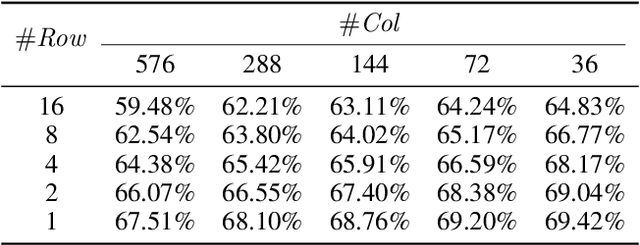
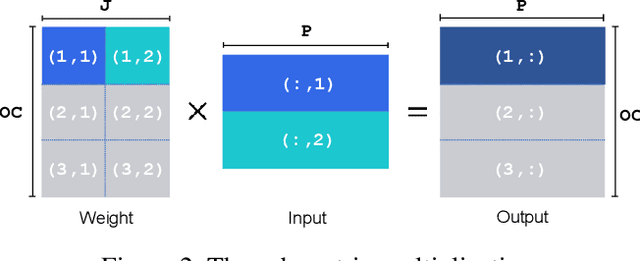
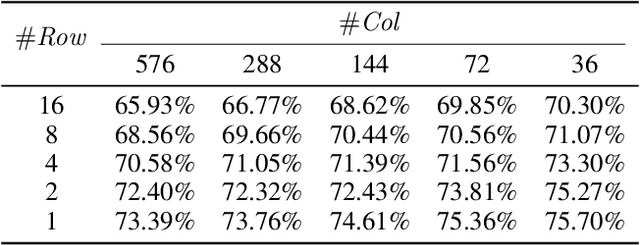
Network quantization is a powerful technique to compress convolutional neural networks. The quantization granularity determines how to share the scaling factors in weights, which affects the performance of network quantization. Most existing approaches share the scaling factors layerwisely or channelwisely for quantization of convolutional layers. Channelwise quantization and layerwise quantization have been widely used in various applications. However, other quantization granularities are rarely explored. In this paper, we will explore the sub-layerwise granularity that shares the scaling factor across multiple input and output channels. We propose an efficient post-training quantization method in sub-layerwise granularity (PTQ-SL). Then we systematically experiment on various granularities and observe that the prediction accuracy of the quantized neural network has a strong correlation with the granularity. Moreover, we find that adjusting the position of the channels can improve the performance of sub-layerwise quantization. Therefore, we propose a method to reorder the channels for sub-layerwise quantization. The experiments demonstrate that the sub-layerwise quantization with appropriate channel reordering can outperform the channelwise quantization.