 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparsity Induction for Accurate Post-Training Pruning of Large Language Models
Feb 25, 2026Large language models have demonstrated capabilities in text generation, while their increasing parameter scales present challenges in computational and memory efficiency. Post-training sparsity (PTS), which reduces model cost by removing weights from dense networks, is an effective approach. However, native dense matrices lack high sparsity, making existing approaches that directly remove weights disrupt model states, resulting in unsatisfactory performance recovery even with post-tuning. We propose Sparsity Induction, which promotes models toward higher sparsity at both distribution and feature levels before pruning, to push the limits of PTS. At the distribution level, we enhance distributional sparsity through mathematically equivalent scaling transformations, which are fully absorbable and incur no extra parameters or inference-time overhead. At the feature level, we introduce Spectral Norm Loss to promote feature sparsity from a low-rank perspective. Experiments across diverse model architectures and tasks demonstrate that our method further enhances sparsity-friendliness, achieving superior pruning performance over existing approaches.
K-Sort Eval: Efficient Preference Evaluation for Visual Generation via Corrected VLM-as-a-Judge
Feb 10, 2026The rapid development of visual generative models raises the need for more scalable and human-aligned evaluation methods. While the crowdsourced Arena platforms offer human preference assessments by collecting human votes, they are costly and time-consuming, inherently limiting their scalability. Leveraging vision-language model (VLMs) as substitutes for manual judgments presents a promising solution. However, the inherent hallucinations and biases of VLMs hinder alignment with human preferences, thus compromising evaluation reliability. Additionally, the static evaluation approach lead to low efficiency. In this paper, we propose K-Sort Eval, a reliable and efficient VLM-based evaluation framework that integrates posterior correction and dynamic matching. Specifically, we curate a high-quality dataset from thousands of human votes in K-Sort Arena, with each instance containing the outputs and rankings of K models. When evaluating a new model, it undergoes (K+1)-wise free-for-all comparisons with existing models, and the VLM provide the rankings. To enhance alignment and reliability, we propose a posterior correction method, which adaptively corrects the posterior probability in Bayesian updating based on the consistency between the VLM prediction and human supervision. Moreover, we propose a dynamic matching strategy, which balances uncertainty and diversity to maximize the expected benefit of each comparison, thus ensuring more efficient evaluation. Extensive experiments show that K-Sort Eval delivers evaluation results consistent with K-Sort Arena, typically requiring fewer than 90 model runs, demonstrating both its efficiency and reliability.
Efficient-SAM2: Accelerating SAM2 with Object-Aware Visual Encoding and Memory Retrieval
Feb 09, 2026Segment Anything Model 2 (SAM2) shows excellent performance in video object segmentation tasks; however, the heavy computational burden hinders its application in real-time video processing. Although there have been efforts to improve the efficiency of SAM2, most of them focus on retraining a lightweight backbone, with little exploration into post-training acceleration. In this paper, we observe that SAM2 exhibits sparse perception pattern as biological vision, which provides opportunities for eliminating redundant computation and acceleration: i) In mask decoder, the attention primarily focuses on the foreground objects, whereas the image encoder in the earlier stage exhibits a broad attention span, which results in unnecessary computation to background regions. ii) In memory bank, only a small subset of tokens in each frame contribute significantly to memory attention, and the salient regions exhibit temporal consistency, making full-token computation redundant. With these insights, we propose Efficient-SAM2, which promotes SAM2 to adaptively focus on object regions while eliminating task-irrelevant computations, thereby significantly improving inference efficiency. Specifically, for image encoder, we propose object-aware Sparse Window Routing (SWR), a window-level computation allocation mechanism that leverages the consistency and saliency cues from the previous-frame decoder to route background regions into a lightweight shortcut branch. Moreover, for memory attention, we propose object-aware Sparse Memory Retrieval (SMR), which allows only the salient memory tokens in each frame to participate in computation, with the saliency pattern reused from their first recollection. With negligible additional parameters and minimal training overhead, Efficient-SAM2 delivers 1.68x speedup on SAM2.1-L model with only 1.0% accuracy drop on SA-V test set.
PTQ4ARVG: Post-Training Quantization for AutoRegressive Visual Generation Models
Jan 29, 2026AutoRegressive Visual Generation (ARVG) models retain an architecture compatible with language models, while achieving performance comparable to diffusion-based models. Quantization is commonly employed in neural networks to reduce model size and computational latency. However, applying quantization to ARVG remains largely underexplored, and existing quantization methods fail to generalize effectively to ARVG models. In this paper, we explore this issue and identify three key challenges: (1) severe outliers at channel-wise level, (2) highly dynamic activations at token-wise level, and (3) mismatched distribution information at sample-wise level. To these ends, we propose PTQ4ARVG, a training-free post-training quantization (PTQ) framework consisting of: (1) Gain-Projected Scaling (GPS) mitigates the channel-wise outliers, which expands the quantization loss via a Taylor series to quantify the gain of scaling for activation-weight quantization, and derives the optimal scaling factor through differentiation.(2) Static Token-Wise Quantization (STWQ) leverages the inherent properties of ARVG, fixed token length and position-invariant distribution across samples, to address token-wise variance without incurring dynamic calibration overhead.(3) Distribution-Guided Calibration (DGC) selects samples that contribute most to distributional entropy, eliminating the sample-wise distribution mismatch. Extensive experiments show that PTQ4ARVG can effectively quantize the ARVG family models to 8-bit and 6-bit while maintaining competitive performance. Code is available at http://github.com/BienLuky/PTQ4ARVG .
Unsupervised Learning for Class Distribution Mismatch
May 11, 2025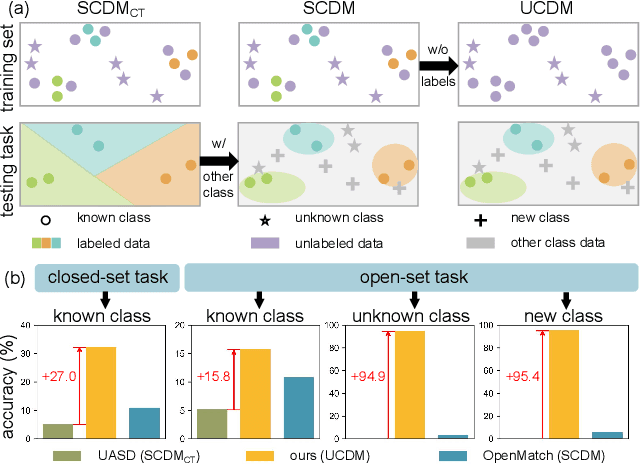


Class distribution mismatch (CDM) refers to the discrepancy between class distributions in training data and target tasks. Previous methods address this by designing classifiers to categorize classes known during training, while grouping unknown or new classes into an "other" category. However, they focus on semi-supervised scenarios and heavily rely on labeled data, limiting their applicability and performance. To address this, we propose Unsupervised Learning for Class Distribution Mismatch (UCDM), which constructs positive-negative pairs from unlabeled data for classifier training. Our approach randomly samples images and uses a diffusion model to add or erase semantic classes, synthesizing diverse training pairs. Additionally, we introduce a confidence-based labeling mechanism that iteratively assigns pseudo-labels to valuable real-world data and incorporates them into the training process. Extensive experiments on three datasets demonstrate UCDM's superiority over previous semi-supervised methods. Specifically, with a 60% mismatch proportion on Tiny-ImageNet dataset, our approach, without relying on labeled data, surpasses OpenMatch (with 40 labels per class) by 35.1%, 63.7%, and 72.5% in classifying known, unknown, and new classes.
SAQ-SAM: Semantically-Aligned Quantization for Segment Anything Model
Mar 09, 2025



Segment Anything Model (SAM) exhibits remarkable zero-shot segmentation capability; however, its prohibitive computational costs make edge deployment challenging. Although post-training quantization (PTQ) offers a promising compression solution, existing methods yield unsatisfactory results when applied to SAM, owing to its specialized model components and promptable workflow: (i) The mask decoder's attention exhibits extreme outliers, and we find that aggressive clipping (ranging down to even 100$\times$), instead of smoothing or isolation, is effective in suppressing outliers while maintaining semantic capabilities. Unfortunately, traditional metrics (e.g., MSE) fail to provide such large-scale clipping. (ii) Existing reconstruction methods potentially neglect prompts' intention, resulting in distorted visual encodings during prompt interactions. To address the above issues, we propose SAQ-SAM in this paper, which boosts PTQ of SAM with semantic alignment. Specifically, we propose Perceptual-Consistency Clipping, which exploits attention focus overlap as clipping metric, to significantly suppress outliers. Furthermore, we propose Prompt-Aware Reconstruction, which incorporates visual-prompt interactions by leveraging cross-attention responses in mask decoder, thus facilitating alignment in both distribution and semantics. To ensure the interaction efficiency, we also introduce a layer-skipping strategy for visual tokens. Extensive experiments are conducted on different segmentation tasks and SAMs of various sizes, and the results show that the proposed SAQ-SAM consistently outperforms baselines. For example, when quantizing SAM-B to 4-bit, our method achieves 11.7% higher mAP than the baseline in instance segmentation task.
CacheQuant: Comprehensively Accelerated Diffusion Models
Mar 03, 2025



Diffusion models have gradually gained prominence in the field of image synthesis, showcasing remarkable generative capabilities. Nevertheless, the slow inference and complex networks, resulting from redundancy at both temporal and structural levels, hinder their low-latency applications in real-world scenarios. Current acceleration methods for diffusion models focus separately on temporal and structural levels. However, independent optimization at each level to further push the acceleration limits results in significant performance degradation. On the other hand, integrating optimizations at both levels can compound the acceleration effects. Unfortunately, we find that the optimizations at these two levels are not entirely orthogonal. Performing separate optimizations and then simply integrating them results in unsatisfactory performance. To tackle this issue, we propose CacheQuant, a novel training-free paradigm that comprehensively accelerates diffusion models by jointly optimizing model caching and quantization techniques. Specifically, we employ a dynamic programming approach to determine the optimal cache schedule, in which the properties of caching and quantization are carefully considered to minimize errors. Additionally, we propose decoupled error correction to further mitigate the coupled and accumulated errors step by step. Experimental results show that CacheQuant achieves a 5.18 speedup and 4 compression for Stable Diffusion on MS-COCO, with only a 0.02 loss in CLIP score. Our code are open-sourced: https://github.com/BienLuky/CacheQuant .
TTAQ: Towards Stable Post-training Quantization in Continuous Domain Adaptation
Dec 13, 2024



Post-training quantization (PTQ) reduces excessive hardware cost by quantizing full-precision models into lower bit representations on a tiny calibration set, without retraining. Despite the remarkable progress made through recent efforts, traditional PTQ methods typically encounter failure in dynamic and ever-changing real-world scenarios, involving unpredictable data streams and continual domain shifts, which poses greater challenges. In this paper, we propose a novel and stable quantization process for test-time adaptation (TTA), dubbed TTAQ, to address the performance degradation of traditional PTQ in dynamically evolving test domains. To tackle domain shifts in quantizer, TTAQ proposes the Perturbation Error Mitigation (PEM) and Perturbation Consistency Reconstruction (PCR). Specifically, PEM analyzes the error propagation and devises a weight regularization scheme to mitigate the impact of input perturbations. On the other hand, PCR introduces consistency learning to ensure that quantized models provide stable predictions for same sample. Furthermore, we introduce Adaptive Balanced Loss (ABL) to adjust the logits by taking advantage of the frequency and complexity of the class, which can effectively address the class imbalance caused by unpredictable data streams during optimization. Extensive experiments are conducted on multiple datasets with generic TTA methods, proving that TTAQ can outperform existing baselines and encouragingly improve the accuracy of low bit PTQ models in continually changing test domains. For instance, TTAQ decreases the mean error of 2-bit models on ImageNet-C dataset by an impressive 10.1\%.
A Stitch in Time Saves Nine: Small VLM is a Precise Guidance for Accelerating Large VLMs
Dec 05, 2024



Vision-language models (VLMs) have shown remarkable success across various multi-modal tasks, yet large VLMs encounter significant efficiency challenges due to processing numerous visual tokens. A promising approach to accelerating large VLM inference is using partial information, such as attention maps from specific layers, to assess token importance and prune less essential tokens. However, our study reveals three key insights: (i) Partial attention information is insufficient for accurately identifying critical visual tokens, resulting in suboptimal performance, especially at low token retention ratios; (ii) Global attention information, such as the attention map aggregated across all layers, more effectively preserves essential tokens and maintains comparable performance under aggressive pruning. However, the attention maps from all layers requires a full inference pass, which increases computational load and is therefore impractical in existing methods; and (iii) The global attention map aggregated from a small VLM closely resembles that of a large VLM, suggesting an efficient alternative. Based on these findings, we introduce a \textbf{training-free} method, \underline{\textbf{S}}mall VLM \underline{\textbf{G}}uidance for accelerating \underline{\textbf{L}}arge VLMs (\textbf{SGL}). Specifically, we employ the attention map aggregated from a small VLM to guide visual token pruning in a large VLM. Additionally, an early exiting mechanism is developed to fully use the small VLM's predictions, dynamically invoking the larger VLM only when necessary, yielding a superior trade-off between accuracy and computation. Extensive evaluations across 11 benchmarks demonstrate the effectiveness and generalizability of SGL, achieving up to 91\% pruning ratio for visual tokens while retaining competitive performance.
DilateQuant: Accurate and Efficient Diffusion Quantization via Weight Dilation
Sep 25, 2024



Diffusion models have shown excellent performance on various image generation tasks, but the substantial computational costs and huge memory footprint hinder their low-latency applications in real-world scenarios. Quantization is a promising way to compress and accelerate models. Nevertheless, due to the wide range and time-varying activations in diffusion models, existing methods cannot maintain both accuracy and efficiency simultaneously for low-bit quantization. To tackle this issue, we propose DilateQuant, a novel quantization framework for diffusion models that offers comparable accuracy and high efficiency. Specifically, we keenly aware of numerous unsaturated in-channel weights, which can be cleverly exploited to reduce the range of activations without additional computation cost. Based on this insight, we propose Weight Dilation (WD) that maximally dilates the unsaturated in-channel weights to a constrained range through a mathematically equivalent scaling. WD costlessly absorbs the activation quantization errors into weight quantization. The range of activations decreases, which makes activations quantization easy. The range of weights remains constant, which makes model easy to converge in training stage. Considering the temporal network leads to time-varying activations, we design a Temporal Parallel Quantizer (TPQ), which sets time-step quantization parameters and supports parallel quantization for different time steps, significantly improving the performance and reducing time cost. To further enhance performance while preserving efficiency, we introduce a Block-wise Knowledge Distillation (BKD) to align the quantized models with the full-precision models at a block level. The simultaneous training of time-step quantization parameters and weights minimizes the time required, and the shorter backpropagation paths decreases the memory footprint of the quantization process.