 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTTAQ: Towards Stable Post-training Quantization in Continuous Domain Adaptation
Dec 13, 2024Post-training quantization (PTQ) reduces excessive hardware cost by quantizing full-precision models into lower bit representations on a tiny calibration set, without retraining. Despite the remarkable progress made through recent efforts, traditional PTQ methods typically encounter failure in dynamic and ever-changing real-world scenarios, involving unpredictable data streams and continual domain shifts, which poses greater challenges. In this paper, we propose a novel and stable quantization process for test-time adaptation (TTA), dubbed TTAQ, to address the performance degradation of traditional PTQ in dynamically evolving test domains. To tackle domain shifts in quantizer, TTAQ proposes the Perturbation Error Mitigation (PEM) and Perturbation Consistency Reconstruction (PCR). Specifically, PEM analyzes the error propagation and devises a weight regularization scheme to mitigate the impact of input perturbations. On the other hand, PCR introduces consistency learning to ensure that quantized models provide stable predictions for same sample. Furthermore, we introduce Adaptive Balanced Loss (ABL) to adjust the logits by taking advantage of the frequency and complexity of the class, which can effectively address the class imbalance caused by unpredictable data streams during optimization. Extensive experiments are conducted on multiple datasets with generic TTA methods, proving that TTAQ can outperform existing baselines and encouragingly improve the accuracy of low bit PTQ models in continually changing test domains. For instance, TTAQ decreases the mean error of 2-bit models on ImageNet-C dataset by an impressive 10.1\%.
MGRQ: Post-Training Quantization For Vision Transformer With Mixed Granularity Reconstruction
Jun 13, 2024



Post-training quantization (PTQ) efficiently compresses vision models, but unfortunately, it accompanies a certain degree of accuracy degradation. Reconstruction methods aim to enhance model performance by narrowing the gap between the quantized model and the full-precision model, often yielding promising results. However, efforts to significantly improve the performance of PTQ through reconstruction in the Vision Transformer (ViT) have shown limited efficacy. In this paper, we conduct a thorough analysis of the reasons for this limited effectiveness and propose MGRQ (Mixed Granularity Reconstruction Quantization) as a solution to address this issue. Unlike previous reconstruction schemes, MGRQ introduces a mixed granularity reconstruction approach. Specifically, MGRQ enhances the performance of PTQ by introducing Extra-Block Global Supervision and Intra-Block Local Supervision, building upon Optimized Block-wise Reconstruction. Extra-Block Global Supervision considers the relationship between block outputs and the model's output, aiding block-wise reconstruction through global supervision. Meanwhile, Intra-Block Local Supervision reduces generalization errors by aligning the distribution of outputs at each layer within a block. Subsequently, MGRQ is further optimized for reconstruction through Mixed Granularity Loss Fusion. Extensive experiments conducted on various ViT models illustrate the effectiveness of MGRQ. Notably, MGRQ demonstrates robust performance in low-bit quantization, thereby enhancing the practicality of the quantized model.
Enhanced Distribution Alignment for Post-Training Quantization of Diffusion Models
Jan 09, 2024
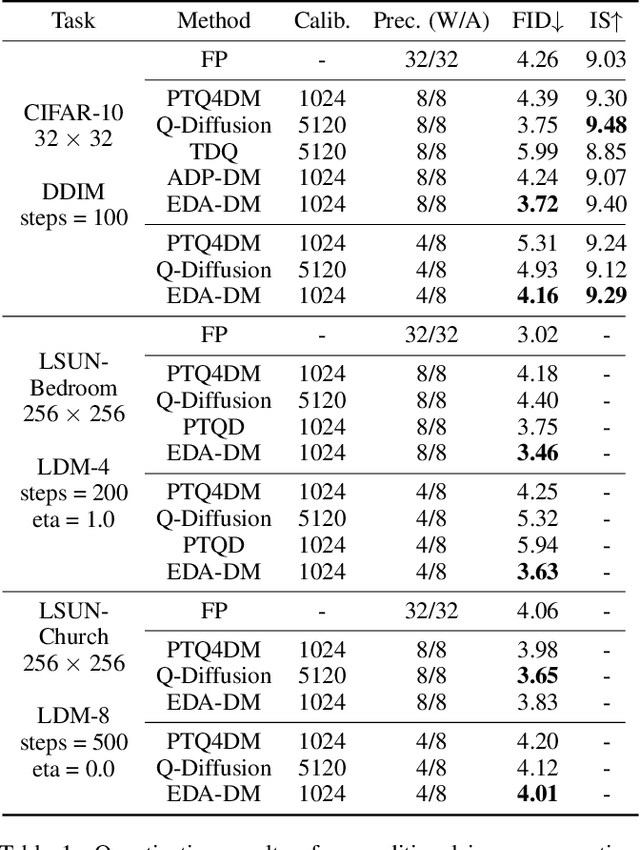


Diffusion models have achieved great success in image generation tasks through iterative noise estimation. However, the heavy denoising process and complex neural networks hinder their low-latency applications in real-world scenarios. Quantization can effectively reduce model complexity, and post-training quantization (PTQ), which does not require fine-tuning, is highly promising in accelerating the denoising process. Unfortunately, we find that due to the highly dynamic distribution of activations in different denoising steps, existing PTQ methods for diffusion models suffer from distribution mismatch issues at both calibration sample level and reconstruction output level, which makes the performance far from satisfactory, especially in low-bit cases. In this paper, we propose Enhanced Distribution Alignment for Post-Training Quantization of Diffusion Models (EDA-DM) to address the above issues. Specifically, at the calibration sample level, we select calibration samples based on the density and diversity in the latent space, thus facilitating the alignment of their distribution with the overall samples; and at the reconstruction output level, we propose Fine-grained Block Reconstruction, which can align the outputs of the quantized model and the full-precision model at different network granularity. Extensive experiments demonstrate that EDA-DM outperforms the existing post-training quantization frameworks in both unconditional and conditional generation scenarios. At low-bit precision, the quantized models with our method even outperform the full-precision models on most datasets.
BinaryViT: Towards Efficient and Accurate Binary Vision Transformers
May 24, 2023Vision Transformers (ViTs) have emerged as the fundamental architecture for most computer vision fields, but the considerable memory and computation costs hinders their application on resource-limited devices. As one of the most powerful compression methods, binarization reduces the computation of the neural network by quantizing the weights and activation values as $\pm$1. Although existing binarization methods have demonstrated excellent performance on Convolutional Neural Networks (CNNs), the full binarization of ViTs is still under-studied and suffering a significant performance drop. In this paper, we first argue empirically that the severe performance degradation is mainly caused by the weight oscillation in the binarization training and the information distortion in the activation of ViTs. Based on these analyses, we propose $\textbf{BinaryViT}$, an accurate full binarization scheme for ViTs, which pushes the quantization of ViTs to the limit. Specifically, we propose a novel gradient regularization scheme (GRS) for driving a bimodal distribution of the weights to reduce oscillation in binarization training. Moreover, we design an activation shift module (ASM) to adaptively tune the activation distribution to reduce the information distortion caused by binarization. Extensive experiments on ImageNet dataset show that our BinaryViT consistently surpasses the strong baseline by 2.05% and improve the accuracy of fully binarized ViTs to a usable level. Furthermore, our method achieves impressive savings of 16.2$\times$ and 17.7$\times$ in model size and OPs compared to the full-precision DeiT-S. The codes and models will be released on github.
Patch-wise Mixed-Precision Quantization of Vision Transformer
May 11, 2023



As emerging hardware begins to support mixed bit-width arithmetic computation, mixed-precision quantization is widely used to reduce the complexity of neural networks. However, Vision Transformers (ViTs) require complex self-attention computation to guarantee the learning of powerful feature representations, which makes mixed-precision quantization of ViTs still challenging. In this paper, we propose a novel patch-wise mixed-precision quantization (PMQ) for efficient inference of ViTs. Specifically, we design a lightweight global metric, which is faster than existing methods, to measure the sensitivity of each component in ViTs to quantization errors. Moreover, we also introduce a pareto frontier approach to automatically allocate the optimal bit-precision according to the sensitivity. To further reduce the computational complexity of self-attention in inference stage, we propose a patch-wise module to reallocate bit-width of patches in each layer. Extensive experiments on the ImageNet dataset shows that our method greatly reduces the search cost and facilitates the application of mixed-precision quantization to ViTs.
RepQ-ViT: Scale Reparameterization for Post-Training Quantization of Vision Transformers
Dec 16, 2022



Post-training quantization (PTQ), which only requires a tiny dataset for calibration without end-to-end retraining, is a light and practical model compression technique. Recently, several PTQ schemes for vision transformers (ViTs) have been presented; unfortunately, they typically suffer from non-trivial accuracy degradation, especially in low-bit cases. In this paper, we propose RepQ-ViT, a novel PTQ framework for ViTs based on quantization scale reparameterization, to address the above issues. RepQ-ViT decouples the quantization and inference processes, where the former employs complex quantizers and the latter employs scale-reparameterized simplified quantizers. This ensures both accurate quantization and efficient inference, which distinguishes it from existing approaches that sacrifice quantization performance to meet the target hardware. More specifically, we focus on two components with extreme distributions: post-LayerNorm activations with severe inter-channel variation and post-Softmax activations with power-law features, and initially apply channel-wise quantization and log$\sqrt{2}$ quantization, respectively. Then, we reparameterize the scales to hardware-friendly layer-wise quantization and log2 quantization for inference, with only slight accuracy or computational costs. Extensive experiments are conducted on multiple vision tasks with different model variants, proving that RepQ-ViT, without hyperparameters and expensive reconstruction procedures, can outperform existing strong baselines and encouragingly improve the accuracy of 4-bit PTQ of ViTs to a usable level.
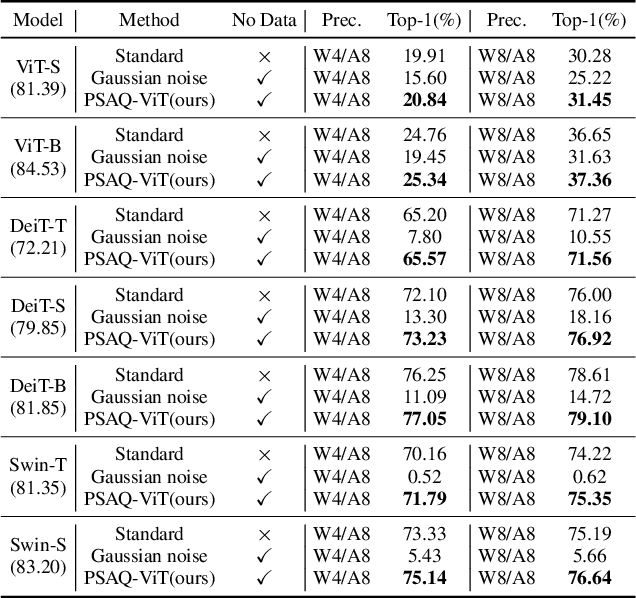
PSAQ-ViT V2: Towards Accurate and General Data-Free Quantization for Vision Transformers
Sep 13, 2022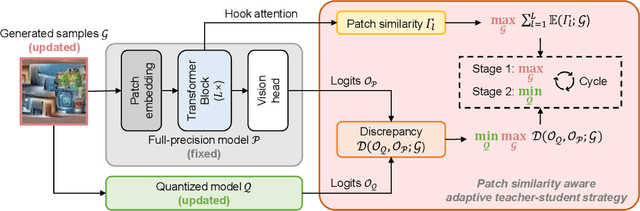


Data-free quantization can potentially address data privacy and security concerns in model compression, and thus has been widely investigated. Recently, PSAQ-ViT designs a relative value metric, patch similarity, to generate data from pre-trained vision transformers (ViTs), achieving the first attempt at data-free quantization for ViTs. In this paper, we propose PSAQ-ViT V2, a more accurate and general data-free quantization framework for ViTs, built on top of PSAQ-ViT. More specifically, following the patch similarity metric in PSAQ-ViT, we introduce an adaptive teacher-student strategy, which facilitates the constant cyclic evolution of the generated samples and the quantized model (student) in a competitive and interactive fashion under the supervision of the full-precision model (teacher), thus significantly improving the accuracy of the quantized model. Moreover, without the auxiliary category guidance, we employ the task- and model-independent prior information, making the general-purpose scheme compatible with a broad range of vision tasks and models. Extensive experiments are conducted on various models on image classification, object detection, and semantic segmentation tasks, and PSAQ-ViT V2, with the naive quantization strategy and without access to real-world data, consistently achieves competitive results, showing potential as a powerful baseline on data-free quantization for ViTs. For instance, with Swin-S as the (backbone) model, 8-bit quantization reaches 82.13 top-1 accuracy on ImageNet, 50.9 box AP and 44.1 mask AP on COCO, and 47.2 mIoU on ADE20K. We hope that accurate and general PSAQ-ViT V2 can serve as a potential and practice solution in real-world applications involving sensitive data. Code will be released and merged at: https://github.com/zkkli/PSAQ-ViT.
HFT: Lifting Perspective Representations via Hybrid Feature Transformation
Apr 11, 2022

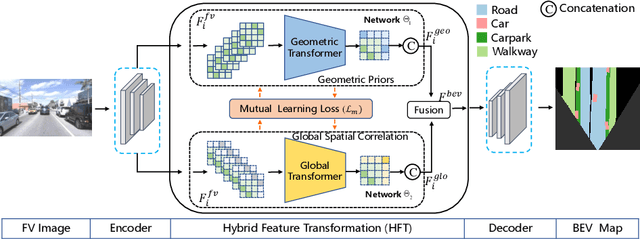
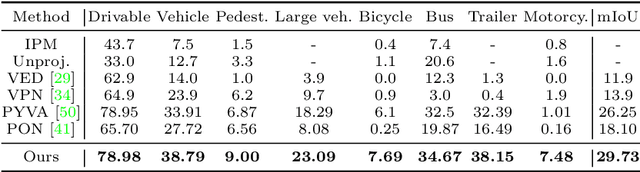
Autonomous driving requires accurate and detailed Bird's Eye View (BEV) semantic segmentation for decision making, which is one of the most challenging tasks for high-level scene perception. Feature transformation from frontal view to BEV is the pivotal technology for BEV semantic segmentation. Existing works can be roughly classified into two categories, i.e., Camera model-Based Feature Transformation (CBFT) and Camera model-Free Feature Transformation (CFFT). In this paper, we empirically analyze the vital differences between CBFT and CFFT. The former transforms features based on the flat-world assumption, which may cause distortion of regions lying above the ground plane. The latter is limited in the segmentation performance due to the absence of geometric priors and time-consuming computation. In order to reap the benefits and avoid the drawbacks of CBFT and CFFT, we propose a novel framework with a Hybrid Feature Transformation module (HFT). Specifically, we decouple the feature maps produced by HFT for estimating the layout of outdoor scenes in BEV. Furthermore, we design a mutual learning scheme to augment hybrid transformation by applying feature mimicking. Notably, extensive experiments demonstrate that with negligible extra overhead, HFT achieves a relative improvement of 13.3% on the Argoverse dataset and 16.8% on the KITTI 3D Object datasets compared to the best-performing existing method. The codes are available at https://github.com/JiayuZou2020/HFT.
Patch Similarity Aware Data-Free Quantization for Vision Transformers
Mar 04, 2022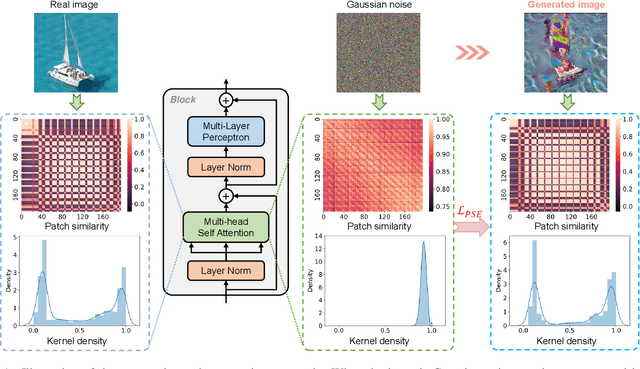
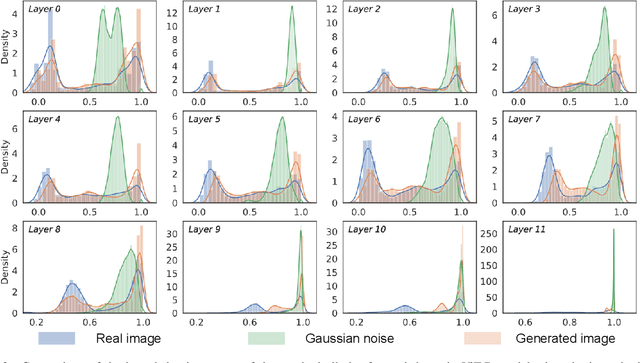
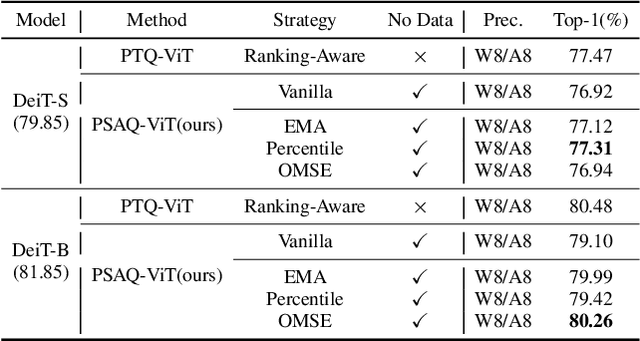
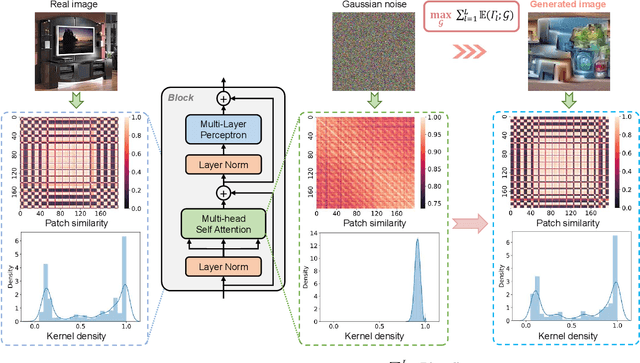
Vision transformers have recently gained great success on various computer vision tasks; nevertheless, their high model complexity makes it challenging to deploy on resource-constrained devices. Quantization is an effective approach to reduce model complexity, and data-free quantization, which can address data privacy and security concerns during model deployment, has received widespread interest. Unfortunately, all existing methods, such as BN regularization, were designed for convolutional neural networks and cannot be applied to vision transformers with significantly different model architectures. In this paper, we propose PSAQ-ViT, a Patch Similarity Aware data-free Quantization framework for Vision Transformers, to enable the generation of "realistic" samples based on the vision transformer's unique properties for calibrating the quantization parameters. Specifically, we analyze the self-attention module's properties and reveal a general difference (patch similarity) in its processing of Gaussian noise and real images. The above insights guide us to design a relative value metric to optimize the Gaussian noise to approximate the real images, which are then utilized to calibrate the quantization parameters. Extensive experiments and ablation studies are conducted on various benchmarks to validate the effectiveness of PSAQ-ViT, which can even outperform the real-data-driven methods.