 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Lanes and Points in Complex Scenarios for Monocular 3D Lane Detection
Mar 08, 2025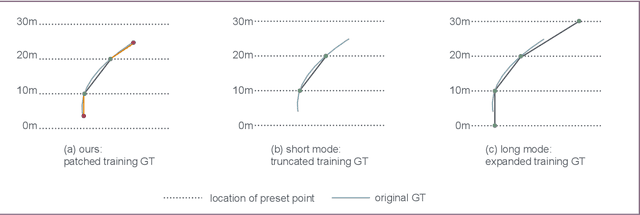
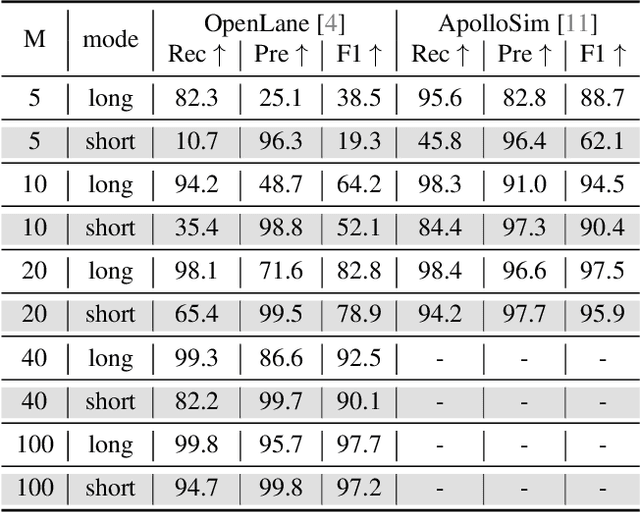
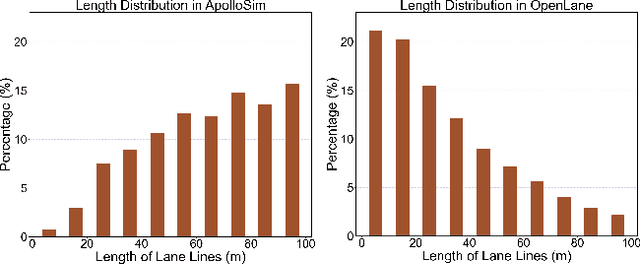
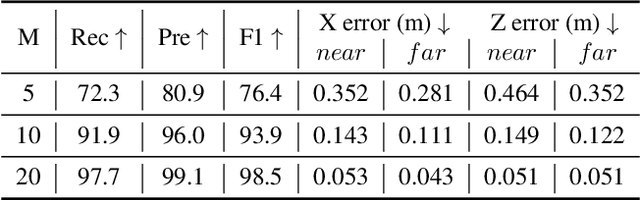
Monocular 3D lane detection is a fundamental task in autonomous driving. Although sparse-point methods lower computational load and maintain high accuracy in complex lane geometries, current methods fail to fully leverage the geometric structure of lanes in both lane geometry representations and model design. In lane geometry representations, we present a theoretical analysis alongside experimental validation to verify that current sparse lane representation methods contain inherent flaws, resulting in potential errors of up to 20 m, which raise significant safety concerns for driving. To address this issue, we propose a novel patching strategy to completely represent the full lane structure. To enable existing models to match this strategy, we introduce the EndPoint head (EP-head), which adds a patching distance to endpoints. The EP-head enables the model to predict more complete lane representations even with fewer preset points, effectively addressing existing limitations and paving the way for models that are faster and require fewer parameters in the future. In model design, to enhance the model's perception of lane structures, we propose the PointLane attention (PL-attention), which incorporates prior geometric knowledge into the attention mechanism. Extensive experiments demonstrate the effectiveness of the proposed methods on various state-of-the-art models. For instance, in terms of the overall F1-score, our methods improve Persformer by 4.4 points, Anchor3DLane by 3.2 points, and LATR by 2.8 points. The code will be available soon.
DrivingRecon: Large 4D Gaussian Reconstruction Model For Autonomous Driving
Dec 12, 2024



Photorealistic 4D reconstruction of street scenes is essential for developing real-world simulators in autonomous driving. However, most existing methods perform this task offline and rely on time-consuming iterative processes, limiting their practical applications. To this end, we introduce the Large 4D Gaussian Reconstruction Model (DrivingRecon), a generalizable driving scene reconstruction model, which directly predicts 4D Gaussian from surround view videos. To better integrate the surround-view images, the Prune and Dilate Block (PD-Block) is proposed to eliminate overlapping Gaussian points between adjacent views and remove redundant background points. To enhance cross-temporal information, dynamic and static decoupling is tailored to better learn geometry and motion features. Experimental results demonstrate that DrivingRecon significantly improves scene reconstruction quality and novel view synthesis compared to existing methods. Furthermore, we explore applications of DrivingRecon in model pre-training, vehicle adaptation, and scene editing. Our code is available at https://github.com/EnVision-Research/DriveRecon.
GPD-1: Generative Pre-training for Driving
Dec 11, 2024



Modeling the evolutions of driving scenarios is important for the evaluation and decision-making of autonomous driving systems. Most existing methods focus on one aspect of scene evolution such as map generation, motion prediction, and trajectory planning. In this paper, we propose a unified Generative Pre-training for Driving (GPD-1) model to accomplish all these tasks altogether without additional fine-tuning. We represent each scene with ego, agent, and map tokens and formulate autonomous driving as a unified token generation problem. We adopt the autoregressive transformer architecture and use a scene-level attention mask to enable intra-scene bi-directional interactions. For the ego and agent tokens, we propose a hierarchical positional tokenizer to effectively encode both 2D positions and headings. For the map tokens, we train a map vector-quantized autoencoder to efficiently compress ego-centric semantic maps into discrete tokens. We pre-train our GPD-1 on the large-scale nuPlan dataset and conduct extensive experiments to evaluate its effectiveness. With different prompts, our GPD-1 successfully generalizes to various tasks without finetuning, including scene generation, traffic simulation, closed-loop simulation, map prediction, and motion planning. Code: https://github.com/wzzheng/GPD.
Stag-1: Towards Realistic 4D Driving Simulation with Video Generation Model
Dec 06, 2024



4D driving simulation is essential for developing realistic autonomous driving simulators. Despite advancements in existing methods for generating driving scenes, significant challenges remain in view transformation and spatial-temporal dynamic modeling. To address these limitations, we propose a Spatial-Temporal simulAtion for drivinG (Stag-1) model to reconstruct real-world scenes and design a controllable generative network to achieve 4D simulation. Stag-1 constructs continuous 4D point cloud scenes using surround-view data from autonomous vehicles. It decouples spatial-temporal relationships and produces coherent keyframe videos. Additionally, Stag-1 leverages video generation models to obtain photo-realistic and controllable 4D driving simulation videos from any perspective. To expand the range of view generation, we train vehicle motion videos based on decomposed camera poses, enhancing modeling capabilities for distant scenes. Furthermore, we reconstruct vehicle camera trajectories to integrate 3D points across consecutive views, enabling comprehensive scene understanding along the temporal dimension. Following extensive multi-level scene training, Stag-1 can simulate from any desired viewpoint and achieve a deep understanding of scene evolution under static spatial-temporal conditions. Compared to existing methods, our approach shows promising performance in multi-view scene consistency, background coherence, and accuracy, and contributes to the ongoing advancements in realistic autonomous driving simulation. Code: https://github.com/wzzheng/Stag.
GaussianFormer-2: Probabilistic Gaussian Superposition for Efficient 3D Occupancy Prediction
Dec 06, 2024



3D semantic occupancy prediction is an important task for robust vision-centric autonomous driving, which predicts fine-grained geometry and semantics of the surrounding scene. Most existing methods leverage dense grid-based scene representations, overlooking the spatial sparsity of the driving scenes. Although 3D semantic Gaussian serves as an object-centric sparse alternative, most of the Gaussians still describe the empty region with low efficiency. To address this, we propose a probabilistic Gaussian superposition model which interprets each Gaussian as a probability distribution of its neighborhood being occupied and conforms to probabilistic multiplication to derive the overall geometry. Furthermore, we adopt the exact Gaussian mixture model for semantics calculation to avoid unnecessary overlapping of Gaussians. To effectively initialize Gaussians in non-empty region, we design a distribution-based initialization module which learns the pixel-aligned occupancy distribution instead of the depth of surfaces. We conduct extensive experiments on nuScenes and KITTI-360 datasets and our GaussianFormer-2 achieves state-of-the-art performance with high efficiency. Code: https://github.com/huang-yh/GaussianFormer.
Probabilistic Gaussian Superposition for Efficient 3D Occupancy Prediction
Dec 05, 20243D semantic occupancy prediction is an important task for robust vision-centric autonomous driving, which predicts fine-grained geometry and semantics of the surrounding scene. Most existing methods leverage dense grid-based scene representations, overlooking the spatial sparsity of the driving scenes. Although 3D semantic Gaussian serves as an object-centric sparse alternative, most of the Gaussians still describe the empty region with low efficiency. To address this, we propose a probabilistic Gaussian superposition model which interprets each Gaussian as a probability distribution of its neighborhood being occupied and conforms to probabilistic multiplication to derive the overall geometry. Furthermore, we adopt the exact Gaussian mixture model for semantics calculation to avoid unnecessary overlapping of Gaussians. To effectively initialize Gaussians in non-empty region, we design a distribution-based initialization module which learns the pixel-aligned occupancy distribution instead of the depth of surfaces. We conduct extensive experiments on nuScenes and KITTI-360 datasets and our GaussianFormer-2 achieves state-of-the-art performance with high efficiency. Code: https://github.com/huang-yh/GaussianFormer.
FactorLLM: Factorizing Knowledge via Mixture of Experts for Large Language Models
Aug 15, 2024



Recent research has demonstrated that Feed-Forward Networks (FFNs) in Large Language Models (LLMs) play a pivotal role in storing diverse linguistic and factual knowledge. Conventional methods frequently face challenges due to knowledge confusion stemming from their monolithic and redundant architectures, which calls for more efficient solutions with minimal computational overhead, particularly for LLMs. In this paper, we explore the FFN computation paradigm in LLMs and introduce FactorLLM, a novel approach that decomposes well-trained dense FFNs into sparse sub-networks without requiring any further modifications, while maintaining the same level of performance. Furthermore, we embed a router from the Mixture-of-Experts (MoE), combined with our devised Prior-Approximate (PA) loss term that facilitates the dynamic activation of experts and knowledge adaptation, thereby accelerating computational processes and enhancing performance using minimal training data and fine-tuning steps. FactorLLM thus enables efficient knowledge factorization and activates select groups of experts specifically tailored to designated tasks, emulating the interactive functional segmentation of the human brain. Extensive experiments across various benchmarks demonstrate the effectiveness of our proposed FactorLLM which achieves comparable performance to the source model securing up to 85% model performance while obtaining over a 30% increase in inference speed. Code: https://github.com/zhenwuweihe/FactorLLM.
Hierarchical Temporal Context Learning for Camera-based Semantic Scene Completion
Jul 02, 2024Camera-based 3D semantic scene completion (SSC) is pivotal for predicting complicated 3D layouts with limited 2D image observations. The existing mainstream solutions generally leverage temporal information by roughly stacking history frames to supplement the current frame, such straightforward temporal modeling inevitably diminishes valid clues and increases learning difficulty. To address this problem, we present HTCL, a novel Hierarchical Temporal Context Learning paradigm for improving camera-based semantic scene completion. The primary innovation of this work involves decomposing temporal context learning into two hierarchical steps: (a) cross-frame affinity measurement and (b) affinity-based dynamic refinement. Firstly, to separate critical relevant context from redundant information, we introduce the pattern affinity with scale-aware isolation and multiple independent learners for fine-grained contextual correspondence modeling. Subsequently, to dynamically compensate for incomplete observations, we adaptively refine the feature sampling locations based on initially identified locations with high affinity and their neighboring relevant regions. Our method ranks $1^{st}$ on the SemanticKITTI benchmark and even surpasses LiDAR-based methods in terms of mIoU on the OpenOccupancy benchmark. Our code is available on https://github.com/Arlo0o/HTCL.
NeuroGauss4D-PCI: 4D Neural Fields and Gaussian Deformation Fields for Point Cloud Interpolation
May 23, 2024Point Cloud Interpolation confronts challenges from point sparsity, complex spatiotemporal dynamics, and the difficulty of deriving complete 3D point clouds from sparse temporal information. This paper presents NeuroGauss4D-PCI, which excels at modeling complex non-rigid deformations across varied dynamic scenes. The method begins with an iterative Gaussian cloud soft clustering module, offering structured temporal point cloud representations. The proposed temporal radial basis function Gaussian residual utilizes Gaussian parameter interpolation over time, enabling smooth parameter transitions and capturing temporal residuals of Gaussian distributions. Additionally, a 4D Gaussian deformation field tracks the evolution of these parameters, creating continuous spatiotemporal deformation fields. A 4D neural field transforms low-dimensional spatiotemporal coordinates ($x,y,z,t$) into a high-dimensional latent space. Finally, we adaptively and efficiently fuse the latent features from neural fields and the geometric features from Gaussian deformation fields. NeuroGauss4D-PCI outperforms existing methods in point cloud frame interpolation, delivering leading performance on both object-level (DHB) and large-scale autonomous driving datasets (NL-Drive), with scalability to auto-labeling and point cloud densification tasks. The source code is released at https://github.com/jiangchaokang/NeuroGauss4D-PCI.
Scaling Multi-Camera 3D Object Detection through Weak-to-Strong Eliciting
Apr 10, 2024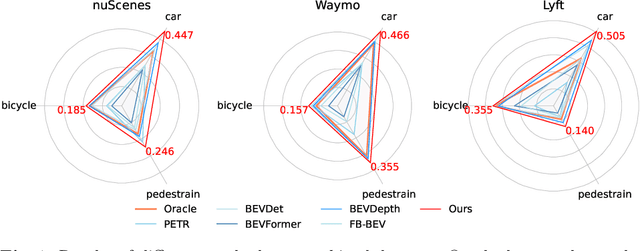
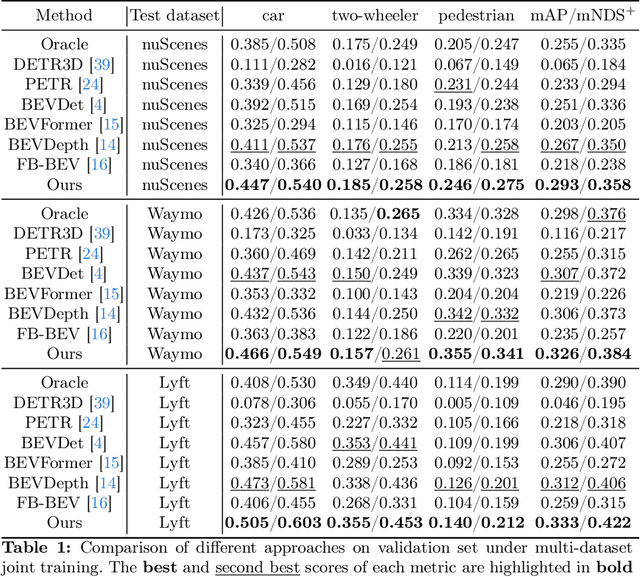
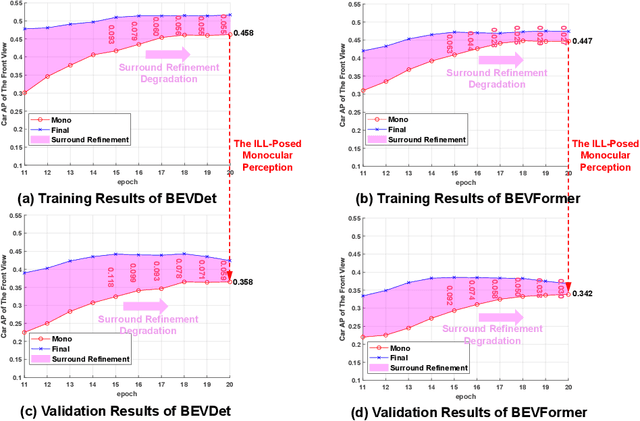
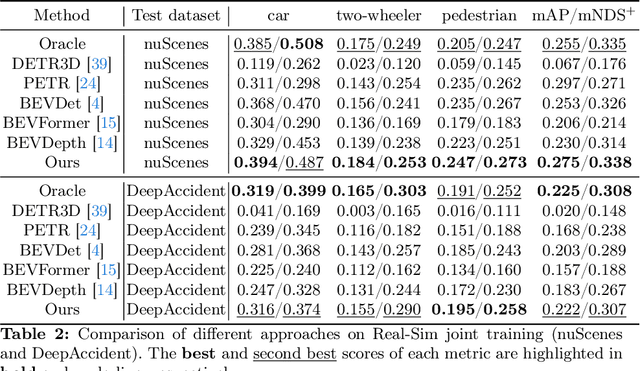
The emergence of Multi-Camera 3D Object Detection (MC3D-Det), facilitated by bird's-eye view (BEV) representation, signifies a notable progression in 3D object detection. Scaling MC3D-Det training effectively accommodates varied camera parameters and urban landscapes, paving the way for the MC3D-Det foundation model. However, the multi-view fusion stage of the MC3D-Det method relies on the ill-posed monocular perception during training rather than surround refinement ability, leading to what we term "surround refinement degradation". To this end, our study presents a weak-to-strong eliciting framework aimed at enhancing surround refinement while maintaining robust monocular perception. Specifically, our framework employs weakly tuned experts trained on distinct subsets, and each is inherently biased toward specific camera configurations and scenarios. These biased experts can learn the perception of monocular degeneration, which can help the multi-view fusion stage to enhance surround refinement abilities. Moreover, a composite distillation strategy is proposed to integrate the universal knowledge of 2D foundation models and task-specific information. Finally, for MC3D-Det joint training, the elaborate dataset merge strategy is designed to solve the problem of inconsistent camera numbers and camera parameters. We set up a multiple dataset joint training benchmark for MC3D-Det and adequately evaluated existing methods. Further, we demonstrate the proposed framework brings a generalized and significant boost over multiple baselines. Our code is at \url{https://github.com/EnVision-Research/Scale-BEV}.